【Python开发者必备】:boto3.s3.connection模块的自定义扩展全解析
发布时间: 2024-10-17 16:38:55 阅读量: 1 订阅数: 4 

# 1. boto3.s3.connection模块基础
## 简介
在本章节中,我们将介绍`boto3.s3.connection`模块的基本概念和用途。`boto3`是AWS的Python SDK,它提供了与Amazon S3等AWS服务交互的能力。`boto3.s3.connection`模块是构建这些交互的基础,它封装了底层的网络连接和协议细节,使得开发者可以专注于业务逻辑的实现。
## 基本使用
首先,我们需要了解如何创建一个S3连接。通过`boto3.Session`对象,我们可以配置和管理AWS资源的访问。以下是一个简单的示例代码,展示了如何创建一个连接并访问S3服务:
```python
import boto3
# 创建一个Session对象
session = boto3.Session(
aws_access_key_id='your_access_key',
aws_secret_access_key='your_secret_key',
region_name='your_region'
)
# 通过Session对象创建S3客户端
s3_client = session.client('s3')
# 使用客户端获取一个bucket的列表
buckets = s3_client.list_buckets()
```
在这个示例中,我们首先导入了`boto3`库,并创建了一个`Session`对象,其中包含了访问密钥、秘密密钥和区域信息。然后,我们通过这个`Session`对象创建了一个S3客户端,并调用了`list_buckets`方法来获取当前AWS账户下的所有S3 bucket列表。
## 模块功能
`boto3.s3.connection`模块不仅提供连接到S3服务的功能,它还支持许多高级特性,例如连接池管理、身份验证机制优化、错误处理、日志记录和性能优化等。这些高级特性将在后续章节中详细介绍,帮助开发者更好地理解和使用`boto3`。
通过本章节的学习,你应该对`boto3.s3.connection`模块有了初步的了解,并能够进行基本的操作。接下来的章节将深入探讨这个模块的高级特性和扩展实践。
# 2. boto3.s3.connection模块的高级特性
在第一章中,我们介绍了`boto3.s3.connection`模块的基础知识,包括如何创建连接、管理桶和对象以及执行基本的操作。本章将深入探讨`boto3.s3.connection`模块的高级特性,包括连接管理的高级选项、错误处理和日志记录的配置以及性能优化技术。这些高级特性可以帮助我们更好地控制和优化与S3服务的交互。
## 2.1 深入了解连接管理
### 2.1.1 连接池的使用和配置
在处理大量并发请求时,连接池可以显著提高性能和效率。`boto3`默认使用连接池,但允许我们自定义连接池的大小和行为。
#### 代码示例:自定义连接池配置
```python
import boto3
from boto3.session import Session
from botocore.session import get_session
# 自定义连接池大小
session = Session()
session._loader._session.get_component('connection_pool')._maxsize = 10
# 创建S3资源对象
s3_resource = session.resource('s3')
```
在上述代码中,我们通过修改`Session`对象的内部组件`connection_pool`的最大大小来设置连接池的大小。这样,当处理多个并发请求时,`boto3`会使用更多的连接,从而提高性能。
### 2.1.2 身份验证机制的优化
身份验证是连接到S3服务时的一个重要方面。`boto3`提供了多种身份验证机制,包括使用AWS凭证文件、环境变量和IAM角色等。
#### 代码示例:使用AWS凭证文件
```python
import boto3
# 指定AWS凭证文件路径
credentials_path = '/path/to/your/credentials/file'
session = boto3.Session(
aws_access_key_id='your_access_key',
aws_secret_access_key='your_secret_key',
aws_session_token='your_session_token', # 如果需要的话
region_name='us-west-2'
)
s3 = session.client('s3')
```
在这个示例中,我们创建了一个`Session`对象,并通过`aws_access_key_id`、`aws_secret_access_key`和`aws_session_token`(如果需要的话)直接传递凭证。这比默认的环境变量和配置文件方法更为直接和明确。
## 2.2 错误处理和日志记录
### 2.2.1 自定义错误处理策略
错误处理是编写可靠代码的关键部分。`boto3`允许我们自定义错误处理策略,以便更好地控制异常处理。
#### 代码示例:自定义异常处理
```python
import boto3
from botocore.exceptions import ClientError
session = boto3.Session()
s3 = session.client('s3')
def handle_error(exception):
if isinstance(exception, ClientError):
# 处理客户端错误
print(f"Error: {exception}")
else:
# 处理其他错误
print("An unexpected error occurred")
s3.meta.events.register('choose-service-error', handle_error)
```
在这个示例中,我们使用`meta.events.register`方法注册了一个事件处理器,它会在发生客户端错误时调用`handle_error`函数。这样,我们可以根据错误类型提供自定义的错误处理逻辑。
### 2.2.2 日志记录的配置和最佳实践
日志记录对于调试和监控应用程序至关重要。`boto3`提供了一种方式来配置日志记录,以捕获和记录关键信息。
#### 代码示例:配置日志记录
```python
import boto3
import logging
# 配置日志
logging.basicConfig(level=***)
session = boto3.Session()
# 获取S3客户端
s3 = session.client('s3')
# 设置日志记录
s3.meta.events.register('before-call.s3.*', ***)
s3.meta.events.register('after-call.s3.*', ***)
```
在这个示例中,我们首先配置了基本的日志记录级别为`INFO`,然后为S3客户端注册了两个事件处理器,一个在调用前记录信息,另一个在调用后记录信息。这样,我们可以在客户端操作之前和之后捕获和记录日志信息。
## 2.3 性能优化技术
### 2.3.1 并发传输和分片上传
当上传大文件时,使用并发传输和分片上传可以显著提高上传速度。
#### 代码示例:分片上传
```python
import boto3
from botocore.exceptions import ClientError
session = boto3.Session()
s3 = session.client('s3')
def upload_file(file_name, bucket, object_name=None):
if object_name is None:
object_name = file_name
s3.upload_file(file_name, bucket, object_name)
# 分片上传的代码略复杂,通常会涉及到多线程或多进程来分割文件并上传各个分片。
```
在上述代码中,我们定义了一个简单的上传函数,它可以用于上传文件到S3。然而,对于大型文件的分片上传,我们通常需要使用多线程或多进程来分割文件并上传各个分片,这可以显著提高上传速度。
### 2.3.2 缓存机制的应用
缓存机制可以帮助我们减少不必要的网络请求,从而提高性能。
#### 代码示例:使用缓存
```python
import boto3
from botocore.cache import Config
session = boto3.Session()
s3 = session.client('s3')
# 配置缓存
config = Config(
read_timeout=10, # 设置读取超时时间
connect_timeout=5, # 设置连接超时时间
retries = {
'max_attempts': 5, # 最大尝试次数
'mode': 'standard' # 重试模式
}
)
# 使用缓存配置的客户端
s3 = session.client('s3', config=config)
```
在上述代码中,我们通过`Config`类配置了客户端的读取超时、连接超时和重试模式。这些配置可以帮助我们优化网络请求,减少不必要的重试和超时,从而提高性能。
通过本章节的介绍,我们可以看到`boto3.s3.connection`模块提供了许多高级特性,这些特性可以帮助我们在与S3服务交互时实现更高的性能和效率。通过使用连接池、优化身份验证机制、自定义错误处理和日志记录策略以及应用性能优化技术,我们可以构建出更加健壮和高效的S3应用程序。在接下来的章节中,我们将进一步探讨如何在不同场景中应用这些高级特性,以及如何实现自定义连接类和集成第三方服务。
# 3. boto3.s3.co

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
1024大促
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
分布式缓存演进实战:Python cache库从单机到集群的升级策略
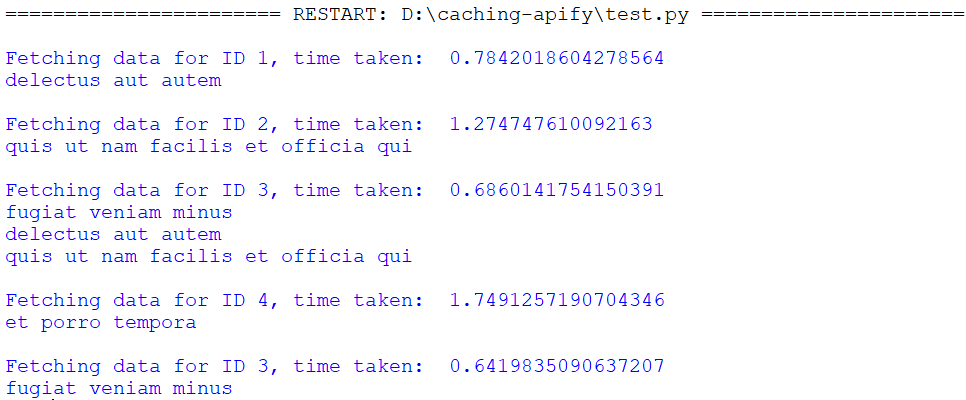
# 1. 分布式缓存概念与挑战
在现代的IT架构中,数据处理的速度和效率至关重要。分布式缓存作为一种提高系统性能的重要技术手段,已经被广泛应用于各种系统和应用中。本章将介绍分布式缓存的基础概念,并深入探讨在实施过程中可能遇到的挑战。
## 1.1 分布式缓存的定义和作用
分布式缓存是一种将数据存储在多台服务器上的缓存方式,它能够有效地解决大规模并发访问时的性能瓶颈问题。通过将数据分
确保数据准确:Django Admin自定义验证和高级查询策略
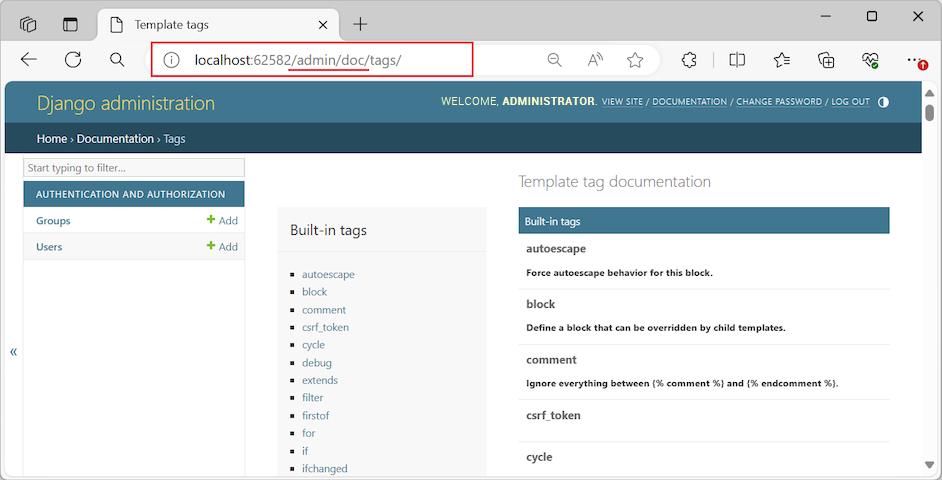
# 1. Django Admin基础与验证机制
Django Admin是Django框架内置的模型管理后台,为开发者提供了一个简单易用的管理界面,方便进行数据的增删改查操作。了解Django Admin的基础功能以及其内建的验证机制是构建高效后台管理系统的起点。
## 1
Python DB库性能监控:数据库性能指标的跟踪技巧
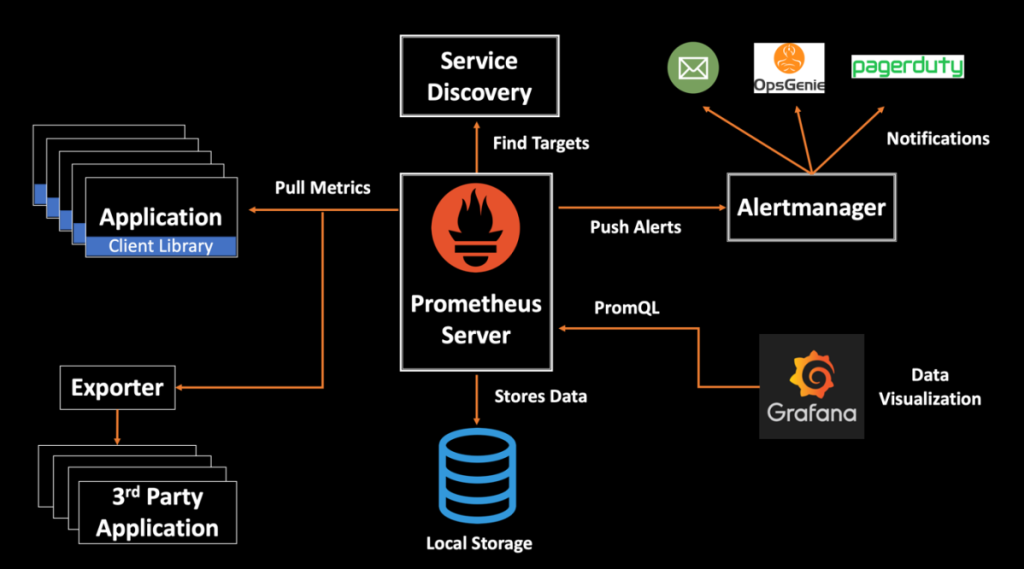
# 1. 数据库性能监控的重要性
## 1.1 数据库性能监控概述
数据库作为现代信息系统的核心组件,其性能的好坏直接影响到整个系统的运行效率。数据库性能监控(Database Performance Monitoring, DPM)是一种主动管理策略,它能够实时跟踪数据库的运行状态,及时发现潜在的问题,并提供必要的数据支持来进行性能优化。没有有效的监控机制,问
【表单国际化深度解析】:在tagging.forms中实现多语言支持的策略
# 1. 表单国际化的基本概念
在当今的互联网时代,一个产品的用户可能遍布全球各地,因此,对于许多应用程序来说,提供国际化(通常简称为i18n)支持已经变得至关重要。在Web开发中,表单国际化是这项工作的关键组成部分,它涉及到设计和实现能够适应不同语言和文化需求的用户输入界面。为了准确地向用户提供信息,实现表单字
深度学习图像处理揭秘:使用ImageFile库部署卷积神经网络

# 1. 深度学习与图像处理
## 简介深度学习在图像处理领域的应用
深度学习已革新了图像处理的多个方面,从最初的图像分类和对象检测,到复杂场景理解和图像生成。通过模拟人类大脑的神经网络结构,深度学习模型能够自动从数据中学习特征,显著提升了图像处理任务的性能和准确性。
## 图像处理中的基本概念和任务
图像处理涉及一系列基本概念和
Werkzeug与数据库集成】:ORM和原生数据库访问模式:性能与安全的双重选择

# 1. Werkzeug与数据库集成概览
## 简介
在现代Web开发中,与数据库的高效集成是构建稳定可靠后端服务的关键因素。Werkzeug,一个强大的WSGI工具库,是Python Web开发的重要组件之一,为集成数据库提供了多种方式。无论是选择使用对象关系映射(ORM)技术简化数据库操作,还是采用原生SQL直接
【教育领域中的pygments.lexer应用】:开发代码教学工具的策略
# 1. Pygments.lexer在代码教学中的重要性
在现代的代码教学中,Pygments.lexer扮演了一个重要的角色,它不仅能够帮助教师更好地展示和讲解代码,还能显著提升学生的学习体验。通过高亮显示和语法解析功能,Pygments.lexer能够将代码结构清晰地展示给学生,使他们更容易理解复杂的代码逻辑和语法。此外,Pygments.lexer的定制化功能使得教师可以根据教学需要
【lxml.etree实战演练】:构建XML解析器与生成器
# 1. XML解析与生成概述
在当今的数据交换和处理中,XML(可扩展标记语言)作为一种跨平台、独立于语言的文本格式,仍然扮演着重要角色。本章将为读者提供一个概览,了解XML的基础知识以及解析与生成的基本概念。
## 1.1 XML的重要性与应用领域
XML被广泛用于各种领域,包括Web服务、配置文件以及数据交换。由于它的可扩展性和自描述特性,XML使得数据
【测试持续改进】:基于zope.testing结果优化代码结构的策略

# 1. 测试持续改进的意义和目标
## 1.1 持续改进的概念和重要性
持续改进是软件开发中一个至关重要的过程,它涉及对测试和开发流程的不断评估和优化。这种方法认识到软件开发不是一成不变的,而是需要适应变化、修正问题,并提高产品质量的过程。通过持续改进,团队能够提升软
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
1024大促
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )