【boto3.s3.connection高级特性】:安全连接和访问控制的专家指南
发布时间: 2024-10-17 16:26:31 阅读量: 5 订阅数: 4 

# 1. boto3库与S3连接的基础知识
## 1.1 boto3库简介
boto3是AWS官方提供的Python SDK,它简化了与AWS服务交互的过程。使用boto3,开发者可以轻松地通过Python脚本来管理AWS资源,比如EC2实例、RDS数据库以及S3存储桶等。本章将重点介绍如何使用boto3库与Amazon S3服务建立连接的基础知识。
## 1.2 安装和配置boto3
在开始之前,需要确保已经安装了boto3库。可以通过以下命令安装:
```python
pip install boto3
```
安装完成后,需要配置AWS的访问密钥和密钥ID,可以通过设置环境变量或者在代码中直接指定:
```python
import boto3
session = boto3.Session(
aws_access_key_id='你的访问密钥',
aws_secret_access_key='你的密钥ID',
region_name='你的AWS区域'
)
s3 = session.resource('s3')
```
## 1.3 建立与S3的连接
通过上述配置后,我们就可以使用boto3来访问S3服务了。以下是一个简单的示例,展示如何列出指定存储桶中的对象:
```python
# 列出指定存储桶中的对象
for obj in s3.Bucket('你的存储桶名称').objects.all():
print(obj.key)
```
这个例子中,我们首先创建了一个S3资源对象`s3`,然后通过`Bucket`方法访问特定的存储桶,并迭代打印出所有对象的key。
通过本章内容,你可以掌握使用boto3库连接到Amazon S3服务的基本知识,并为后续章节的学习打下坚实的基础。
# 2. S3连接的安全机制
## 2.1 认证和授权概述
### 2.1.1 AWS IAM的角色和策略
在AWS IAM(Identity and Access Management)中,角色(Role)是一种为特定的任务或服务授予临时权限的方式。角色并不与特定的用户绑定,而是可以被任何持有相应权限的实体扮演。角色的权限是由与之关联的一组策略(Policy)定义的,这些策略定义了角色可以执行的操作以及访问的资源。
AWS IAM策略是一种JSON文档,它定义了用户或角色的权限。策略可以附加到用户、角色、组或资源上。策略文档中包含了声明(Statement),每个声明包含三个主要部分:Effect、Action和Resource。Effect指定了声明是允许还是拒绝执行操作;Action定义了要允许或拒绝的操作;Resource指定了操作可以应用到的资源。
#### 代码示例:创建IAM策略
```json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource": "arn:aws:s3:::example-bucket/*"
}
]
}
```
### 2.1.2 S3存储桶的权限设置
S3存储桶的权限设置通常涉及到两种策略:存储桶策略(Bucket Policy)和访问控制列表(Access Control List, ACL)。存储桶策略是一种基于存储桶的IAM策略,它定义了哪些用户或角色可以对存储桶执行哪些操作。ACL是一种更细粒度的控制方式,它可以控制单个对象级别的权限。
存储桶策略通常用于定义跨多个用户和角色的通用权限规则,而ACL则适用于定义更具体的权限需求,例如特定对象的读写权限。
#### 表格:S3存储桶策略与ACL的比较
| 特性 | 存储桶策略(Bucket Policy) | 访问控制列表(ACL) |
| ------------- | ------------------------------ | -------------------------------- |
| 定义位置 | 存储桶的权限标签页 | 对象的属性对话框 |
| 权限粒度 | 存储桶级别的操作 | 对象级别的操作 |
| 是否支持通配符 | 支持(使用*或?等) | 支持(使用XML格式定义) |
| 应用范围 | 全部或特定的IAM角色和用户 | 具体的对象或用户 |
| 管理方式 | 可以使用AWS IAM策略语言 | 预定义的选项或XML格式 |
## 2.2 安全传输协议
### 2.2.1 HTTPS与SSL/TLS的介绍
HTTPS(Hyper Text Transfer Protocol Secure)是一种在互联网上安全通信的超文本传输协议。它通过SSL(Secure Socket Layer)或TLS(Transport Layer Security)协议在客户端和服务器之间建立加密的连接,确保数据传输的安全性。
SSL/TLS协议通过握手过程在客户端和服务器之间协商加密算法和密钥,然后使用这些密钥对数据进行加密传输。这个过程确保了即使数据在互联网上传输,也无法被第三方轻易截获和篡改。
### 2.2.2 boto3中SSL/TLS的配置和使用
在boto3中,可以通过配置SSL/TLS来确保S3连接的安全。这通常涉及到使用`requests`库的SSL上下文设置。以下是一个配置SSL/TLS上下文并在boto3中使用的示例:
```python
import boto3
import ssl
import requests
# 创建SSL上下文
context = ssl.create_default_context()
context.check_hostname = False
context.verify_mode = ssl.CERT_NONE
# 使用SSL上下文创建S3客户端
s3_client = boto3.client(
's3',
aws_access_key_id='YOUR_ACCESS_KEY',
aws_secret_access_key='YOUR_SECRET_KEY',
region_name='YOUR_REGION',
verify=False, # 不验证服务器证书
config=Config(ssl_context=context)
)
# 使用客户端进行操作
# ...
```
## 2.3 加密机制
### 2.3.1 服务器端加密与客户端加密
在S3中,数据加密可以发生在服务器端或客户端。服务器端加密(Server-side Encryption)是指在数据写入S3存储桶时自动进行加密,而客户端加密(Client-side Encryption)则是在数据离开客户端之前进行加密。
服务器端加密可以在Amazon S3中使用几种不同的方法,包括使用由AWS Key Management Service(KMS)托管的密钥(SSE-KMS)、使用由Amazon S3托管的密钥(SSE-S3)或使用服务器端加密的客户提供的密钥(SSE-C)。
客户端加密则更加灵活,允许用户使用自定义的加密算法和密钥。这通常需要在数据写入之前使用加密库(如PyCrypto或cryptography)对数据进行加密,并在读取时进行解密。
### 2.3.2 如何在boto3中设置和管理加密选项
在boto3中,可以通过设置`ServerSideEncryption`参数来指定服务器端加密的方法。以下是一个使用SSE-KMS加密对象的示例:
```python
import boto3
# 创建S3客户端
s3_client = boto3.client(
's3',
aws_access_key_id='YOUR_ACCESS_KEY',
aws_secret_access_key='YOUR_SECRET_KEY',
region_name='YOUR_REGION'
)
# 使用SSE-KMS加密上传对象
response = s3_client.put_object(
Bucket='example-bucket',
Key='example-key',
Body='example-data',
ServerSideEncryption='aws:kms',
SSEKMSKeyId='your-kms-key-id'
)
# 确认上传成功
print(response)
```
在客户端加密的情况下,需要在数据写入之前手动加密,并在读取时解密。这涉及到使用Python的加密库来处理数据的加密和解密。
```python
from cryptography.fernet import Fernet
# 生成密钥
key = Fernet.generate_key()
# 创建一个加密器
cipher_suite = Fernet(key)
# 加密数据
encrypted_data = cipher_suite.encrypt(b'example-data')
# 使用boto3上传加密数据
s3_client.put_object(
Bucket='example-bucket',
Key='example-key',
Body=encrypted_data
)
# 在读取时,需要使用相同的密钥解密数据
decrypted_data = cipher_suite.decrypt(encrypted_data)
```
通过本章节的介绍,我们了解了S3连接的安全机制,包括认证和授权、安全传输协议以及加密机制。在下一节中,我们将深入探讨访问控制的高级实践,包括AWS IAM策略的详细解析和如何在boto3中实现细粒度访问控制。
# 3. 访问控制的高级实践
## 3.1 AWS IAM策略详解
### 3.1.1 策略语法和结构
AWS Identity and Access Management (IAM) 是 AWS 中用于控制用户和服务访问权限的服务。策略是 IAM 中的核心概念,它们定义了访问权限的具体规则。理解 IAM 策略的语法和结构对于管理 AWS 资源的安全访问至关重要。
IAM 策略是以 JSON 格式编写的,包含一个或多个语句(Statement),每个语句定义了一组权限。每个语句由以下元素组成:
- **Effect**: 指定权限是允许(Allow)还是拒绝(Deny)。
- **Principal**: 指定策略应用到的用户、用户组或角色。
- **Action**: 指定允许或拒绝的操作,例如 `s3:GetObject`。
- **Resource**: 指定操作的目标资源,通常是 ARN(Amazon Resource Name)。
- **Condition**: 指定额外的条件,这些条件决定了策略语句是否应用于特定的情况。
### 3.1.2 创建自定义IAM策略
创建自定义 IAM 策略可以帮助你实现精细的访问控制。以下是一个简单的 IAM 策略示例,该策略允许用户对名为 `my-bucket` 的 S3 存储桶中的对象进行 `GetObject` 和 `PutObject` 操作。
```json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::***:user/MyUser"
},
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::my-bucket/*"
]
}
]
}
```
在本章节中,我们将深入探讨 IAM 策略的创建和应用,包括如何使用条件来进一步限制访问权限。我们将通过实际案例来展示如何构建能够满足特定安全需求的策略。此外,本章节还将介绍 IAM 策略的最佳实践,帮助你避免常见的安全陷阱。
## 3.2 S3存储桶和对象的权限
### 3.2.1 理解存储桶策略和访问控制列表
S3 存储桶和对象的权限可以通过两种方式控制:存储桶策略(Bucket Policy)和访问控制列表(ACL)。理解这两者的区别和适用场景对于构建高效的安全策略至关重要。
**存储桶策略**是一种 JSON 策略文档,可以直接附加到存储桶上,控制用户对存储桶和存储桶内对象的访问权限。存储桶策略可以实现细粒度的访问控制,并且可以对跨多个 AWS 账户的资源施加权限。
**访问控制列表(ACL)**是一种较旧的访问控制方法,用于控制存储桶和对象的访问权限。ACL 使用预定义的权限集,并且通常用于存储桶级别的访问控制。虽然 ACL 仍然可以在某些情况下使用,但 AWS 推荐使用存

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
1024大促
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
分布式缓存演进实战:Python cache库从单机到集群的升级策略
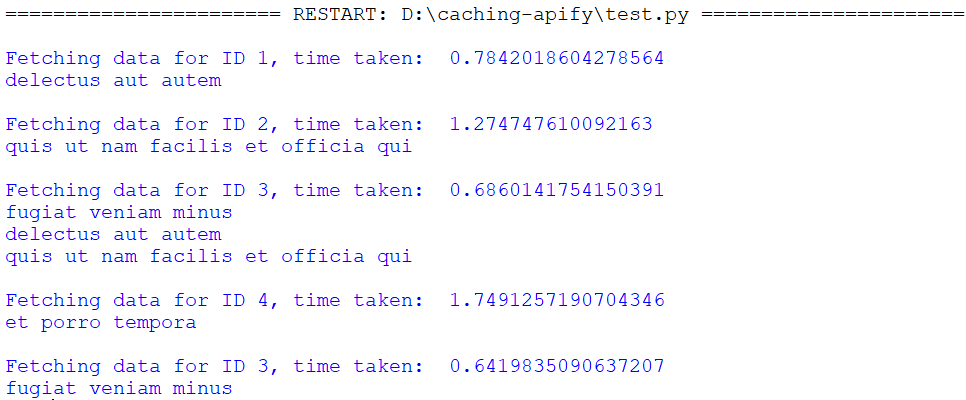
# 1. 分布式缓存概念与挑战
在现代的IT架构中,数据处理的速度和效率至关重要。分布式缓存作为一种提高系统性能的重要技术手段,已经被广泛应用于各种系统和应用中。本章将介绍分布式缓存的基础概念,并深入探讨在实施过程中可能遇到的挑战。
## 1.1 分布式缓存的定义和作用
分布式缓存是一种将数据存储在多台服务器上的缓存方式,它能够有效地解决大规模并发访问时的性能瓶颈问题。通过将数据分
确保数据准确:Django Admin自定义验证和高级查询策略
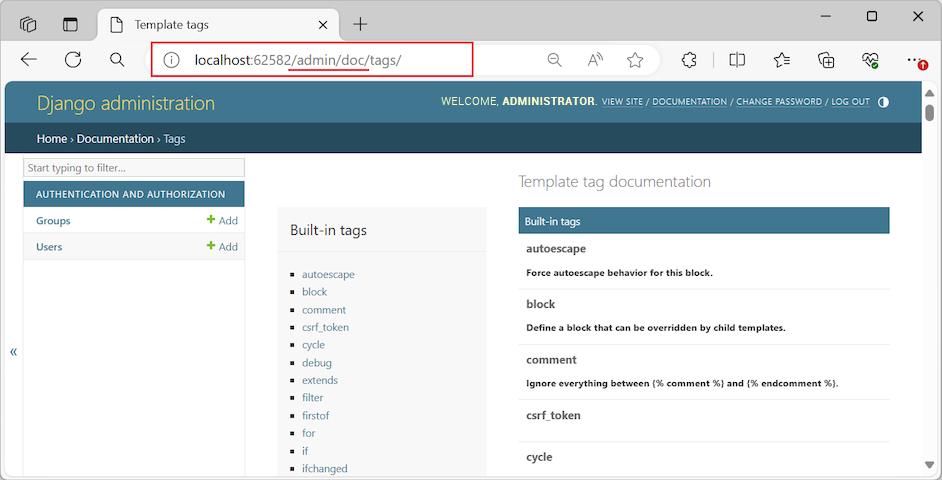
# 1. Django Admin基础与验证机制
Django Admin是Django框架内置的模型管理后台,为开发者提供了一个简单易用的管理界面,方便进行数据的增删改查操作。了解Django Admin的基础功能以及其内建的验证机制是构建高效后台管理系统的起点。
## 1
Python DB库性能监控:数据库性能指标的跟踪技巧
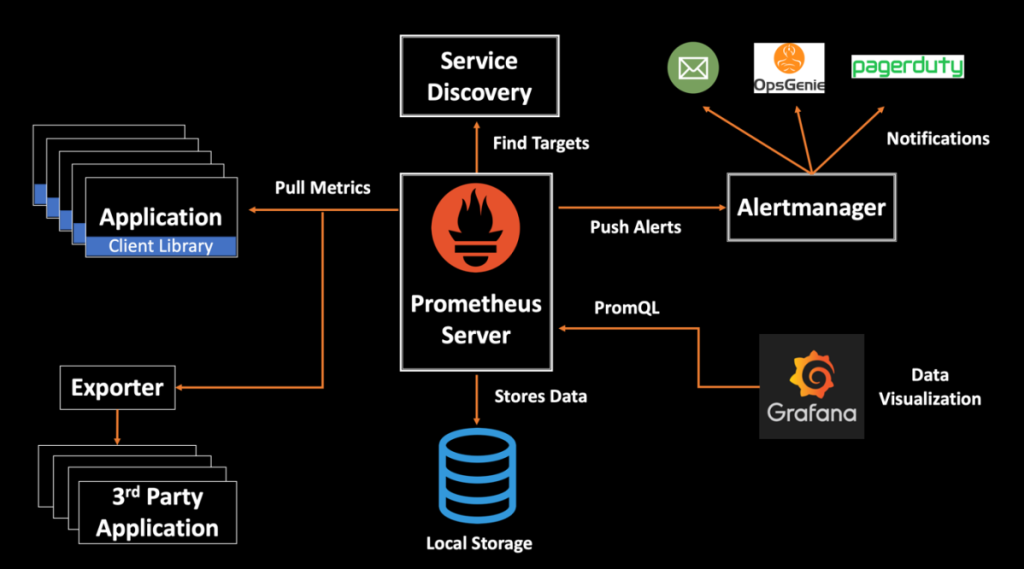
# 1. 数据库性能监控的重要性
## 1.1 数据库性能监控概述
数据库作为现代信息系统的核心组件,其性能的好坏直接影响到整个系统的运行效率。数据库性能监控(Database Performance Monitoring, DPM)是一种主动管理策略,它能够实时跟踪数据库的运行状态,及时发现潜在的问题,并提供必要的数据支持来进行性能优化。没有有效的监控机制,问
【表单国际化深度解析】:在tagging.forms中实现多语言支持的策略
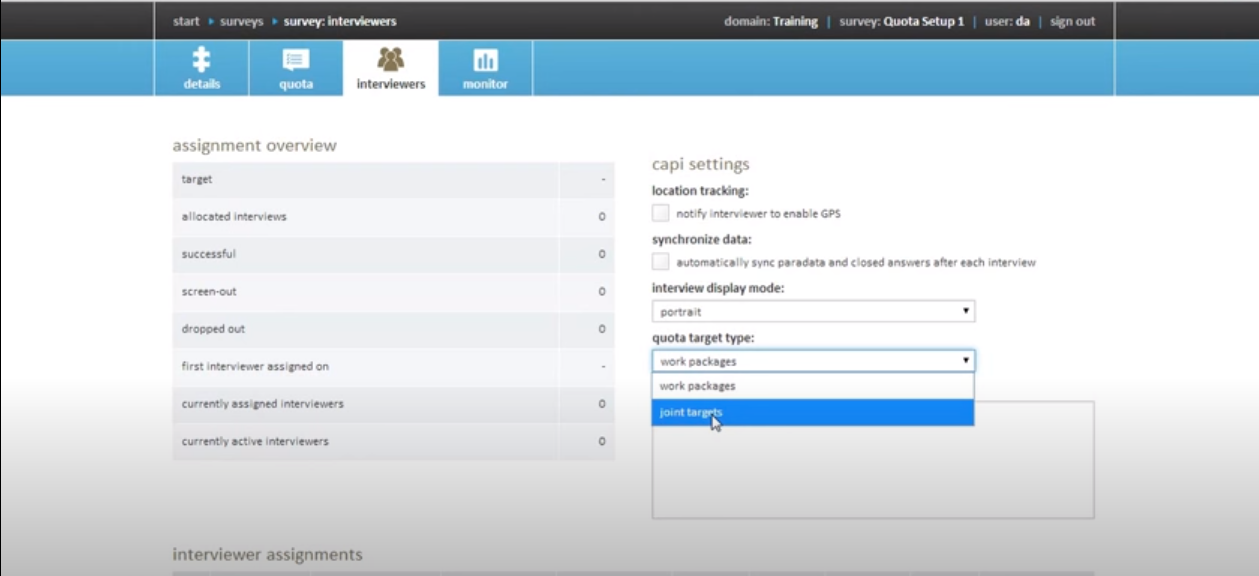
# 1. 表单国际化的基本概念
在当今的互联网时代,一个产品的用户可能遍布全球各地,因此,对于许多应用程序来说,提供国际化(通常简称为i18n)支持已经变得至关重要。在Web开发中,表单国际化是这项工作的关键组成部分,它涉及到设计和实现能够适应不同语言和文化需求的用户输入界面。为了准确地向用户提供信息,实现表单字
深度学习图像处理揭秘:使用ImageFile库部署卷积神经网络

# 1. 深度学习与图像处理
## 简介深度学习在图像处理领域的应用
深度学习已革新了图像处理的多个方面,从最初的图像分类和对象检测,到复杂场景理解和图像生成。通过模拟人类大脑的神经网络结构,深度学习模型能够自动从数据中学习特征,显著提升了图像处理任务的性能和准确性。
## 图像处理中的基本概念和任务
图像处理涉及一系列基本概念和
Werkzeug与数据库集成】:ORM和原生数据库访问模式:性能与安全的双重选择

# 1. Werkzeug与数据库集成概览
## 简介
在现代Web开发中,与数据库的高效集成是构建稳定可靠后端服务的关键因素。Werkzeug,一个强大的WSGI工具库,是Python Web开发的重要组件之一,为集成数据库提供了多种方式。无论是选择使用对象关系映射(ORM)技术简化数据库操作,还是采用原生SQL直接
【教育领域中的pygments.lexer应用】:开发代码教学工具的策略
# 1. Pygments.lexer在代码教学中的重要性
在现代的代码教学中,Pygments.lexer扮演了一个重要的角色,它不仅能够帮助教师更好地展示和讲解代码,还能显著提升学生的学习体验。通过高亮显示和语法解析功能,Pygments.lexer能够将代码结构清晰地展示给学生,使他们更容易理解复杂的代码逻辑和语法。此外,Pygments.lexer的定制化功能使得教师可以根据教学需要
【lxml.etree实战演练】:构建XML解析器与生成器
# 1. XML解析与生成概述
在当今的数据交换和处理中,XML(可扩展标记语言)作为一种跨平台、独立于语言的文本格式,仍然扮演着重要角色。本章将为读者提供一个概览,了解XML的基础知识以及解析与生成的基本概念。
## 1.1 XML的重要性与应用领域
XML被广泛用于各种领域,包括Web服务、配置文件以及数据交换。由于它的可扩展性和自描述特性,XML使得数据
【测试持续改进】:基于zope.testing结果优化代码结构的策略

# 1. 测试持续改进的意义和目标
## 1.1 持续改进的概念和重要性
持续改进是软件开发中一个至关重要的过程,它涉及对测试和开发流程的不断评估和优化。这种方法认识到软件开发不是一成不变的,而是需要适应变化、修正问题,并提高产品质量的过程。通过持续改进,团队能够提升软
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
1024大促
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )