从零开始:xml.dom.Node入门教程与XML文档构建指南
发布时间: 2024-10-12 18:07:55 阅读量: 15 订阅数: 13 
# 1. XML基础与DOM模型概述
## 1.1 XML简介
XML(可扩展标记语言)是一种用于存储和传输数据的标记语言。它通过使用标签来描述数据,使得数据与表现形式分离,增强了跨平台和跨应用的互操作性。XML广泛应用于数据交换、配置文件、数据存储等领域。
## 1.2 XML的特点
XML具有以下特点:
- **可扩展性**:用户可以定义自己的标签。
- **自描述性**:XML文档中的数据结构自包含,易于理解。
- **层次性**:数据通过嵌套标签形成树状结构。
- **纯文本格式**:XML是纯文本,易于阅读和编辑。
## 1.3 DOM模型概述
DOM(文档对象模型)是一种用于表示和操作XML文档的接口。DOM将XML文档视为一个树形结构,每个节点代表文档中的一个元素或属性。通过DOM API,开发者可以编程方式访问和修改XML文档的内容、结构和样式。
```python
# 示例代码:使用Python的xml.dom模块加载XML文档
from xml.dom import minidom
# 解析XML文档
dom_tree = minidom.parse('example.xml')
# 获取根节点
root = dom_tree.documentElement
# 输出根节点名称
print(root.tagName)
```
以上代码段展示了如何使用Python的`xml.dom`模块加载一个XML文档,并获取其根节点名称。这只是DOM操作的一个简单示例,接下来的章节将深入探讨DOM模型的使用和操作。
# 2. xml.dom.Node核心概念与使用
在本章节中,我们将深入探讨`xml.dom.Node`接口的核心概念及其在实际应用中的使用方法。`xml.dom.Node`是XML处理中非常重要的一个接口,它提供了对文档对象模型(DOM)节点操作的基本方法和属性。
## 2.1 xml.dom.Node接口简介
### 2.1.1 Node接口的主要属性和方法
`xml.dom.Node`接口定义了一系列属性和方法,这些是操作XML文档的基础。下面是一些核心的属性和方法:
- `nodeType`:这是一个整数,表示节点的类型。常见的节点类型包括元素节点(`Node.ELEMENT_NODE`)、文本节点(`Node.TEXT_NODE`)、属性节点(`Node.ATTRIBUTE_NODE`)等。
- `nodeName`:返回节点的名称,对于元素节点,它是标签名;对于属性节点,它是属性名。
- `nodeValue`:返回或设置节点的值。对于文本节点或属性节点,这个属性表示实际的文本内容或属性值。
- `childNodes`:返回一个包含所有子节点的实时`NodeList`对象。
- `parentNode`:返回当前节点的父节点。
- `insertBefore(newChild, refChild)`:在参考子节点`refChild`之前插入一个新的子节点`newChild`。
- `removeChild(child)`:移除当前节点的一个子节点。
- `appendChild(newChild)`:向`childNodes`列表的末尾添加一个新节点。
### 2.1.2 Node类型及其区分
节点类型是区分不同节点的关键。`xml.dom.Node`接口定义了多种节点类型常量,例如:
- `Node.ELEMENT_NODE`:元素节点
- `Node.TEXT_NODE`:文本节点
- `Node.ATTRIBUTE_NODE`:属性节点
- `Node.CDATA_SECTION_NODE`:CDATA区块节点
- `Node.PROCESSING_INSTRUCTION_NODE`:处理指令节点
- `***MENT_NODE`:注释节点
不同的节点类型有不同的属性和方法,例如,文本节点和元素节点在获取子节点时会有不同的结果。理解这些节点类型对于正确操作XML文档至关重要。
## 2.2 Node对象的操作
### 2.2.1 创建和插入节点
创建和插入节点是DOM操作中的基本步骤。以下是一个创建元素节点并将其插入到文档的示例:
```python
from xml.dom import minidom
# 创建一个空的DOM文档
dom = minidom.getDOMImplementation().createDocument("", "", None)
# 创建一个新的元素节点
new_element = dom.createElement("newElement")
# 获取根节点
root = dom.documentElement
# 插入新元素节点到根节点
root.appendChild(new_element)
```
在这个例子中,我们首先创建了一个空的DOM文档,然后创建了一个名为`newElement`的新元素节点,并将其添加到了文档的根节点下。
### 2.2.2 删除和替换节点
删除和替换节点是常见的操作需求。以下是如何删除一个节点的示例:
```python
# 假设我们已经有了一个名为root的根节点
# 找到要删除的节点
node_to_remove = root.firstChild
# 删除节点
root.removeChild(node_to_remove)
```
在这个例子中,我们首先获取了根节点的第一个子节点,然后调用`removeChild`方法将其从DOM树中删除。
### 2.2.3 克隆节点与节点遍历
克隆节点和遍历节点是处理复杂XML文档时常用的操作。以下是克隆节点和遍历子节点的示例:
```python
# 克隆节点
cloned_node = new_element.cloneNode(True) # 参数为True表示深拷贝
# 节点遍历
for node in root.childNodes:
if node.nodeType == Node.ELEMENT_NODE:
print(node.nodeName)
```
在这个例子中,我们使用`cloneNode`方法克隆了一个元素节点,并遍历了根节点的所有子节点,打印出所有元素节点的名称。
## 2.3 命名空间处理
### 2.3.1 命名空间的概念和重要性
XML命名空间用于区分具有相同名称的不同元素或属性。它在XML文档中起着重要作用,尤其是在处理大型或复杂文档时。命名空间通常由URI标识,并且可以使用前缀进行引用。
### 2.3.2 在Node操作中处理命名空间
在进行Node操作时,正确处理命名空间是非常重要的。以下是如何在DOM中创建带有命名空间的元素节点的示例:
```python
# 创建带有命名空间的元素节点
namespace_uri = "***"
prefix = "ex"
qualified_name = f"{prefix}:newElement"
# 创建带有命名空间的元素节点
new_element = dom.createElementNS(namespace_uri, qualified_name)
```
在这个例子中,我们使用`createElementNS`方法创建了一个带有命名空间的元素节点。这种方法允许我们在创建元素时指定命名空间URI和前缀。
通过本章节的介绍,我们了解了`xml.dom.Node`接口的基本概念、主要属性和方法、节点类型及其区分。我们还学习了如何进行节点的创建、插入、删除、替换、克隆以及遍历,以及如何在Node操作中处理命名空间。这些操作是XML文档处理的基础,掌握它们对于进行更高级的XML操作至关重要。
# 3. XML文档结构化构建实践
在本章节中,我们将深入探讨如何使用xml.dom.Node接口来构建XML文档的结构。我们将从创建文档和根节点开始,逐步构建子节点和属性,并最终实现XML文档的序列化和错误处理。本章节旨在提供实用的指导,帮助开发者高效地构建和管理XML文档结构。
## 3.1 基于xml.dom.Node构建XML结构
### 3.1.1 创建文档和根节点
在XML文档结构的构建中,第一步是创建一个Document对象和根节点。Document对象是DOM树的根节点,它包含着整个XML文档的结构。根节点是XML文档的最顶层元素,所有的子节点都将直接或间接地挂载在根节点下。
#### 代码示例:
```python
from xml.dom import minidom
# 创建一个Document对象
dom_tree = minidom.Document()
# 创建根节点
root = dom_tree.createElement("root")
dom_tree.appendChild(root)
```
#### 逻辑分析:
在上述代码中,我们首先导入了`xml.dom.minidom`模块,这是Python中处理XML的一个轻量级库。接着,我们创建了一个Document对象`dom_tree`。`createElement`方法用于创建一个新元素,我们将其命名为`"root"`作为根节点。最后,我们使用`appendChild`方法将根节点添加到Document对象中。
#### 参数说明:
- `minidom`: Python标准库中的一个模块,用于处理XML文档。
- `createElement`: 在Document对象上创建一个新元素节点的方法。
- `appendChild`: 将新创建的节点添加到DOM树中的指定父节点。
### 3.1.2 构建子节点和属性
在根节点创建完成后,我们可以开始构建XML文档的子节点和属性。子节点可以是元素节点,也可以是文本节点。在XML中,属性被视为元素的子节点。
#### 代码示例:
```python
# 创建子节点
child = dom_tree.createElement("child")
text = dom_tree.createTextNode("This is a child node")
child.appendChild(text)
root.appendChild(child)
# 设置属性
child.setAttribute("id", "child1")
```
#### 逻辑分析:
在这个代码示例中,我们首先创建了一个名为`"child"`的子元素节点,并为其创建了一个文本子节点,其中包含文本内容`"This is a child node"`。然后,我们将文本节点添加到子元素节点中,并将子元素节点添加到根节点下。
接着,我们使用`setAttribute`方法为子元素节点设置了一个属性`"id"`,其值为`"child1"`。
#### 参数说明:
- `createElement`: 创建一个新元素节点。
- `createTextNode`: 创建一个新的文本节点。
- `appendChild`: 添加子节点。
- `setAttribute`: 为元素节点设置属性。
## 3.2 XML文档的序列化
### 3.2.1 使用DOMSerializer序列化文档
序列化是将DOM树转换为XML格式的文本表示的过程。在Python中,可以使用`DOMSerializer`类来实现这一功能。
#### 代码示例:
```python
from xml.dom import minidom
# 创建Document对象和根节点
dom_tree = minidom.Document()
root = dom_tree.createElement("root")
dom_tree.appendChild(root)
# 序列化文档
serializer = dom_tree.toxml()
print(serializer)
```
#### 逻辑分析:
在上述代码中,我们首先创建了一个Document对象和一个根节点。然后,我们使用`toxml`方法将DOM树序列化为XML格式的字符串。最后,我们打印出序列化后的XML字符串。
#### 参数说明:
- `toxml`: 将DOM树序列化为XML格式的字符串。
### 3.2.2 使用XMLWriter类进行格式化输出
除了简单的序列化,我们还可以使用`XMLWriter`类来格式化输出XML文档,这样可以使XML文档的结构更加清晰易读。
#### 代码示例:
```python
from xml.dom import minidom
from xml.dom.minidom import XMLWriter
# 创建Document对象和根节点
dom_tree = minidom.Document()
root = dom_tree.createElement("root")
dom_tree.appendChild(root)
# 使用XMLWriter格式化输出
output = XMLWriter(open("output.xml", "w"))
output.write(dom_tree)
output.close()
```
#### 逻辑分析:
在这个代码示例中,我们首先创建了一个Document对象和一个根节点。然后,我们创建了一个`XMLWriter`对象,并将其关联到一个文件输出流。`write`方法用于将DOM树格式化写入到指定的文件中。最后,我们关闭了文件输出流。
#### 参数说明:
- `XMLWriter`: 一个工具类,用于格式化写入DOM树到文件。
- `open`: 打开一个文件用于写入。
- `write`: 将DOM树格式化写入到文件。
- `close`: 关闭文件输出流。
## 3.3 错误处理和异常管理
### 3.3.1 错误处理策略
在构建和操作XML文档的过程中,难免会遇到错误。良好的错误处理策略对于确保程序的健壮性至关重要。
#### 代码示例:
```python
from xml.dom import minidom
from xml.parsers.expat import XMLException
try:
# 创建Document对象和根节点
dom_tree = minidom.Document()
root = dom_tree.createElement("root")
dom_tree.appendChild(root)
# 这里故意引入一个错误
# root.appendChild("This is not a node")
except XMLException as e:
print(f"XML解析错误: {e}")
```
#### 逻辑分析:
在这个代码示例中,我们首先尝试创建一个Document对象和一个根节点。然后,我们故意引入了一个错误,即尝试将一个字符串直接添加到根节点下,而不是一个节点对象。这将引发一个`XMLException`异常。我们使用`try...except`结构来捕获并处理这个异常。
#### 参数说明:
- `XMLException`: XML解析过程中可能抛出的异常。
- `try...except`: Python中的异常处理结构。
### 3.3.2 异常捕获与日志记录
为了进一步提高错误处理的效率,我们可以将异常信息记录到日志文件中,以便于后续的错误分析和调试。
#### 代码示例:
```python
import logging
# 配置日志
logging.basicConfig(filename='error.log', level=logging.ERROR)
try:
# 创建Document对象和根节点
dom_tree = minidom.Document()
root = dom_tree.createElement("root")
dom_tree.appendChild(root)
# 故意引入一个错误
# root.appendChild("This is not a node")
except Exception as e:
logging.error(f"发生错误: {e}")
```
#### 逻辑分析:
在这个代码示例中,我们首先配置了Python的日志系统,将错误信息记录到`error.log`文件中,并设置日志级别为`ERROR`。然后,我们在`try...except`结构中捕获了异常,并使用`logging.error`方法将错误信息记录到日志文件中。
#### 参数说明:
- `logging.basicConfig`: 配置日志系统的基本信息。
- `filename`: 日志文件的名称。
- `level`: 日志级别。
- `logging.error`: 记录错误级别的日志信息。
通过本章节的介绍,我们了解了如何使用xml.dom.Node接口构建XML文档的结构,包括创建文档和根节点、构建子节点和属性、序列化XML文档以及错误处理和异常管理。这些技能对于开发中处理XML数据至关重要,能够帮助开发者构建出结构良好、易于维护的XML文档。
在本章节中,我们首先介绍了如何使用xml.dom.Node接口创建文档和根节点,然后逐步构建了子节点和属性。接着,我们探讨了XML文档的序列化方法,包括使用DOMSerializer和XMLWriter类。最后,我们讨论了错误处理和异常管理的重要性,并展示了如何使用Python的日志系统来记录错误信息。
本章节的实践操作为开发者提供了一个完整的XML文档构建流程,涵盖了从创建到序列化再到错误处理的各个方面。通过这些示例和解释,开发者可以更好地理解和掌握xml.dom.Node接口的使用,从而在实际项目中更有效地处理XML数据。
# 4. XML文档解析与数据提取
解析XML文档是XML数据处理的核心步骤,它涉及到将XML文档转换成我们可以操作的数据结构。在本章节中,我们将深入探讨如何使用xml.dom.Node接口解析XML文档,并提取所需的数据。我们将介绍解析器的选择与配置,解析XML文档到DOM树的方法,以及如何查询和遍历节点,提取特定数据的技术和实例。此外,我们还将探索如何使用DOM动态修改文档以及更新XML数据的技巧。
## 4.1 解析XML文档
解析XML文档的目的是将XML文本转换成DOM树,这样我们就可以使用DOM API进行数据操作。在这一小节中,我们将讨论如何选择合适的解析器,配置解析选项,并将XML文档解析成DOM树。
### 4.1.1 解析器的选择与配置
在Python中,常用的XML解析库有`xml.dom.minidom`和`xml.etree.ElementTree`。`xml.dom.minidom`是DOM解析器,它可以将XML文档解析成DOM对象,方便我们使用DOM API进行数据操作。`xml.etree.ElementTree`是一个基于事件的解析器,适合处理大型XML文件。
选择解析器时,我们需要考虑文件的大小、结构复杂度以及处理速度等因素。对于小型到中等大小的XML文件,`xml.dom.minidom`通常是一个不错的选择,因为它易于使用且功能强大。对于非常大的XML文件,我们可能需要使用`xml.etree.ElementTree`或其他基于事件的解析器来提高性能。
### 4.1.2 解析XML文档到DOM树
使用`xml.dom.minidom`解析XML文档到DOM树的过程非常直接。首先,我们需要创建一个解析器对象,然后调用其`parse`方法。下面是一个简单的示例代码,展示了如何使用`xml.dom.minidom`解析器解析XML文档:
```python
from xml.dom import minidom
# 假设我们有一个XML字符串
xml_data = """<root>
<child id="1">Hello World</child>
<child id="2">Hello Python</child>
</root>"""
# 创建一个解析器对象
parser = minidom.getDOMParser()
# 解析XML数据
dom_tree = parser.parseString(xml_data)
# 输出DOM树的结构
print(dom_tree.toxml())
```
在上述代码中,我们首先导入了`minidom`模块,并定义了一个XML字符串。然后,我们创建了一个`DOMParser`对象,并调用`parseString`方法来解析这个XML字符串。最后,我们使用`toxml`方法输出了DOM树的结构。
### 4.1.3 错误处理策略
解析XML时可能会遇到各种错误,例如格式错误或解析器不支持的特性。为了避免程序在遇到错误时崩溃,我们需要实现适当的错误处理策略。`xml.dom.minidom`提供了一些方法来处理这些错误,例如`parseString`方法的异常处理:
```python
try:
dom_tree = parser.parseString(xml_data)
except Exception as e:
print("解析出错:", e)
```
在上述代码中,我们使用`try-except`语句来捕获可能发生的异常,并打印出错误信息。
## 4.2 提取XML数据
解析XML文档后,我们通常需要提取特定的数据。这可以通过查询和遍历DOM树来实现。在这一小节中,我们将讨论如何查询和遍历节点,以及如何提取特定数据的技术和实例。
### 4.2.1 查询和遍历节点
DOM API提供了多种方法来查询和遍历节点。例如,我们可以使用`getElementsByTagName`方法来获取具有特定标签名的所有节点,或者使用`getAttribute`方法来获取节点的属性值。
### 4.2.2 提取特定数据的技术和实例
为了提取特定的数据,我们可以编写函数来遍历DOM树,并查询特定的节点和属性。下面是一个示例函数,它提取了所有`<child>`节点的文本内容和属性:
```python
def extract_data(dom_tree):
# 获取所有<child>节点
children = dom_tree.getElementsByTagName("child")
# 遍历每个节点
for child in children:
# 获取文本内容
text = child.firstChild.data.strip()
# 获取属性值
attr_id = child.getAttribute("id")
print(f"Text: {text}, ID: {attr_id}")
# 调用函数
extract_data(dom_tree)
```
在上述代码中,我们定义了一个`extract_data`函数,它接受一个DOM树作为参数。该函数首先获取所有`<child>`节点,然后遍历每个节点,获取其文本内容和属性值,并打印出来。
## 4.3 动态修改与数据更新
在某些情况下,我们可能需要对已经解析的XML文档进行动态修改。在这一小节中,我们将讨论如何使用DOM API动态修改文档,以及更新XML数据的技巧。
### 4.3.1 使用DOM动态修改文档
DOM API允许我们动态地创建、修改和删除节点。例如,我们可以使用`createElement`方法创建新节点,使用`appendChild`方法添加节点到父节点,使用`removeChild`方法删除节点。
### 4.3.2 更新XML数据的技巧
更新XML数据通常涉及到创建新节点或修改现有节点的内容。下面是一个示例函数,它演示了如何更新特定节点的文本内容:
```python
def update_data(dom_tree):
# 获取所有<child>节点
children = dom_tree.getElementsByTagName("child")
# 假设我们要更新ID为1的节点的文本
for child in children:
if child.getAttribute("id") == "1":
# 更新文本内容
child.firstChild.data = "Updated Text"
break
# 调用函数
update_data(dom_tree)
```
在上述代码中,我们定义了一个`update_data`函数,它接受一个DOM树作为参数。该函数遍历所有`<child>`节点,找到ID为1的节点,并更新其文本内容。
通过本章节的介绍,我们了解了如何使用xml.dom.Node接口解析XML文档,并提取所需的数据。我们讨论了解析器的选择与配置,解析XML文档到DOM树的方法,以及如何查询和遍历节点,提取特定数据的技术和实例。此外,我们还探讨了如何使用DOM动态修改文档以及更新XML数据的技巧。这些知识对于处理XML数据在实际项目中的应用至关重要,无论是在数据交换与集成,自动化文档生成,还是Web服务与API设计方面,xml.dom.Node都是一个强大的工具。
# 5. xml.dom.Node在实际项目中的应用
## 5.1 数据交换与集成
### 5.1.1 使用xml.dom.Node进行数据交换
在进行数据交换时,XML由于其良好的结构化和可读性成为了诸多开发者的选择。xml.dom.Node作为DOM结构的基石,为数据交换提供了灵活的操作能力。使用xml.dom.Node,我们能够精确地操作XML文档的每一个节点,从而确保数据交换的准确性和完整性。
#### 示例场景:企业间数据交换
假设需要在两个企业间进行数据交换,比如订单信息。首先,你需要定义一个XML模式(Schema),它规定了交换数据的结构和类型。然后,使用xml.dom.Node API来创建XML文档,按照定义的模式填充数据。
```python
import xml.dom.minidom
# 创建一个空的DOM文档
dom = xml.dom.minidom.Document()
# 创建根节点
root = dom.createElement('Orders')
dom.appendChild(root)
# 创建并插入订单节点
order = dom.createElement('Order')
root.appendChild(order)
# 添加订单详情,如产品、数量等
product = dom.createElement('Product')
product.setAttribute('name', 'Widget')
product.setAttribute('quantity', '42')
order.appendChild(product)
```
在这个示例中,我们创建了一个订单文档,并添加了商品信息。之后,这个XML文档可以发送给对方,对方使用相同的xml.dom.Node操作,按照自己的需求解析和处理。
### 5.1.2 集成不同数据源
在实际项目中,数据往往来源于多个系统或应用。通过xml.dom.Node,我们可以把来自不同源的数据集成到一个统一的XML文档中,再进行处理或分发。
#### 示例场景:集成多个数据源
假设你有一个项目需要集成来自CRM系统、ERP系统和第三方API的数据。xml.dom.Node可以帮助你按照统一的格式整合这些数据源:
```python
import xml.dom.minidom
# 假设我们已经从不同系统获取了数据
customer_data = {...} # CRM数据
order_data = {...} # ERP数据
third_party_data = {...} # 第三方数据
# 创建一个新的DOM文档
dom = xml.dom.minidom.Document()
# 创建并添加根节点
root = dom.createElement('IntegratedData')
dom.appendChild(root)
# 将不同数据源的数据转换为XML格式并添加到根节点
# 这里仅以CRM数据为例,其他数据源类似处理
for customer in customer_data:
customer_node = dom.createElement('Customer')
customer_node.setAttribute('id', customer['id'])
# ...添加其他属性和子节点
root.appendChild(customer_node)
# 最后,XML文档可以被序列化和传输到其他系统
```
通过这种方式,xml.dom.Node不仅提供了数据整合的能力,还提供了灵活性来应对不同数据源的结构差异。
## 5.2 自动化文档生成
### 5.2.1 利用XML文档自动化生成报表
在商业环境中,定期生成报表是一项常见的任务。xml.dom.Node使得这个过程自动化变得可能。通过编程方式,我们可以轻松地创建报表模板,填充数据,然后生成格式化的文档。
#### 示例场景:自动化生成销售报表
假设我们需要为销售团队自动化生成每周销售报表。我们可以使用xml.dom.Node来构建报表模板,并填充最新的销售数据。
```python
import xml.dom.minidom
# 创建DOM文档和根节点
dom = xml.dom.minidom.Document()
root = dom.createElement('SalesReport')
dom.appendChild(root)
# 假设我们已获取最新的销售数据
sales_data = {...} # 销售数据
# 为报表添加标题和日期
title = dom.createElement('Title')
title.textContent = 'Weekly Sales Report'
date = dom.createElement('Date')
date.textContent = '2023-04-10'
root.appendChild(title)
root.appendChild(date)
# 填充销售数据到报表中
for sale in sales_data:
sale_entry = dom.createElement('SaleEntry')
sale_entry.setAttribute('product', sale['product'])
sale_entry.setAttribute('quantity', str(sale['quantity']))
sale_entry.setAttribute('total', str(sale['total']))
root.appendChild(sale_entry)
# 将XML文档保存为文件
with open('sales_report.xml', 'w') as f:
f.write(***rettyxml())
```
### 5.2.2 文档生成工具的集成与使用
自动化文档生成可以通过集成专门的工具来实现更高级的功能。例如,可以使用JasperReports或XML Generator这样的工具来生成PDF或Excel格式的报表。
#### 示例场景:集成XML Generator生成PDF报表
```python
# 假设我们已经创建好了一个XML文档,名为sales_report.xml
xml_content = open('sales_report.xml').read()
# 使用XML Generator工具,假设我们有一个名为xml2pdf的函数
# 这个函数接受XML内容并将其转换成PDF格式
pdf_content = xml2pdf(xml_content)
# 将PDF内容保存到文件
with open('sales_report.pdf', 'wb') as f:
f.write(pdf_content)
```
在实际应用中,这些工具通常需要进行配置和脚本编写,但是它们提供了强大的文档处理能力,使得报表的生成更加高效和灵活。
## 5.3 Web服务与API设计
### 5.3.1 使用xml.dom.Node处理Web服务请求
在设计Web服务和API时,特别是RESTful服务中,需要处理大量的XML数据。xml.dom.Node提供了处理这些数据的强大工具。
#### 示例场景:处理RESTful服务的XML请求
假设有一个Web服务API端点,需要处理来自客户端的订单信息。我们使用xml.dom.Node来解析和处理这个请求:
```python
from flask import Flask, request
import xml.dom.minidom
app = Flask(__name__)
@app.route('/submit_order', methods=['POST'])
def submit_order():
xml_data = request.data.decode('utf-8')
dom = xml.dom.minidom.parseString(xml_data)
order_root = dom.documentElement
# 解析订单信息,例如获取客户ID和订单详情
customer_id = order_root.getAttribute('customer_id')
order_details = []
for child in order_root.childNodes:
if child.nodeName == 'OrderDetail':
quantity = child.getAttribute('quantity')
product = child.getElementsByTagName('Product')[0].firstChild.data
order_details.append({'product': product, 'quantity': quantity})
# 处理订单逻辑...
return 'Order received'
if __name__ == '__main__':
app.run()
```
### 5.3.2 构建RESTful API的XML响应
RESTful API通常会响应JSON格式的数据,但有些情况下,由于客户端的要求或其他技术限制,API需要返回XML格式的数据。xml.dom.Node也提供了构建这种响应的方法。
#### 示例场景:返回XML格式的订单信息
```python
from flask import Flask, make_response
app = Flask(__name__)
@app.route('/get_order', methods=['GET'])
def get_order():
# 假设我们已经获取到了订单信息
order_info = {...} # 订单数据
dom = xml.dom.minidom.Document()
# 创建并构建订单根节点
root = dom.createElement('Order')
dom.appendChild(root)
# 添加订单详情
for detail in order_info['details']:
order_detail = dom.createElement('OrderDetail')
order_detail.setAttribute('quantity', detail['quantity'])
product_node = dom.createElement('Product')
product_node.appendChild(dom.createTextNode(detail['product']))
order_detail.appendChild(product_node)
root.appendChild(order_detail)
# 将DOM文档转换为响应对象
response = make_response(***rettyxml())
response.headers['Content-Type'] = 'application/xml'
return response
if __name__ == '__main__':
app.run()
```
在这个示例中,我们创建了一个包含订单详情的XML响应,然后将其返回给请求的客户端。这样,即使API客户端期望以XML格式接收数据,我们也能够满足其需求。
通过这一系列的示例和分析,我们可以看出xml.dom.Node在数据交换、文档生成以及Web服务中发挥了至关重要的作用。在构建实际项目时,xml.dom.Node的灵活性和强大功能使得它成为一个不可或缺的工具。
# 6. xml.dom.Node高级应用与最佳实践
## 6.1 高级节点操作技巧
在本章节中,我们将深入探讨xml.dom.Node接口在实际应用中的高级技巧,包括节点事件监听与处理,以及复杂结构的节点操作策略。
### 6.1.1 节点事件监听与处理
在处理XML文档时,事件监听可以提供一种机制,以响应DOM操作中发生的变化。例如,当一个节点被添加到文档中时,你可能需要执行一些额外的操作,如验证数据或更新其他节点。xml.dom.Node事件监听可以使用事件处理程序来实现这一点。
```python
from xml.dom import minidom
from xml.dom.events import EventTarget
# 创建一个DOM文档
doc = minidom.Document()
# 定义一个事件监听器
class MyEventListener(EventTarget):
def handleEvent(self, event):
print(f"Event occurred: {event.type}")
# 创建一个监听器实例
listener = MyEventListener()
# 注册监听器
doc.addEventListener('appendChild', listener.handleEvent)
# 创建一个节点并添加到文档中
new_node = doc.createElement('newNode')
doc.appendChild(new_node)
```
在这个例子中,我们定义了一个事件监听器类`MyEventListener`,它有一个`handleEvent`方法,该方法在事件发生时被调用。我们创建了一个监听器实例,并将其注册到文档上,以便在`appendChild`事件发生时接收通知。
### 6.1.2 复杂结构的节点操作策略
处理复杂XML结构时,节点操作可能会变得相当复杂。以下是一些策略,可以帮助你更有效地管理这些操作:
1. **递归遍历**:递归遍历树结构是处理复杂XML文档的一种常见方法。
2. **XPath查询**:使用XPath可以方便地定位和操作XML文档中的特定节点。
3. **使用命名空间**:在处理具有多个命名空间的XML时,正确使用命名空间可以避免许多问题。
```python
import xml.dom.minidom
import xml.dom.xpathtools as xpath
# 加载XML文档
doc = xml.dom.minidom.parse('example.xml')
# 使用XPath查询特定节点
query = xpath.XPathQuery("//some:element[@attribute='value']")
result = query.evaluate(doc)
# 遍历结果节点
for node in result:
# 执行操作
print(node.toxml())
```
在这个例子中,我们使用了XPath来查询特定的节点,并遍历了这些节点以执行某些操作。
## 6.2 DOM性能优化
DOM操作可能会导致性能问题,特别是在处理大型XML文档时。本节将介绍一些DOM性能优化的技术和内存管理策略。
### 6.2.1 性能分析与优化技术
性能分析是优化DOM操作的第一步。你可以使用Python的性能分析工具来确定瓶颈。以下是一些常见的性能优化技术:
1. **最小化DOM操作**:尽量减少不必要的DOM操作,比如节点的添加、删除和修改。
2. **使用DOM构建器**:一次性构建DOM树,而不是逐步插入节点,可以显著提高性能。
### 6.2.2 内存管理与DOM操作优化
在使用DOM API时,合理的内存管理也是至关重要的。以下是一些内存管理最佳实践:
1. **使用弱引用**:使用弱引用来引用DOM节点,可以防止内存泄漏。
2. **及时释放资源**:在不再需要DOM树时,及时释放资源。
```python
import weakref
# 创建一个DOM文档
doc = xml.dom.minidom.Document()
# 使用弱引用
weak_doc = weakref.ref(doc)
# 在适当的时候释放资源
del doc
print(weak_doc()) # None
```
在这个例子中,我们使用了弱引用来引用DOM文档,并在不再需要时释放了它。
通过上述章节内容,我们可以看到xml.dom.Node接口在高级应用和最佳实践中的重要性和应用方法。这些技术可以帮助开发者更高效地处理XML文档,优化性能,并确保良好的内存管理。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Python库深度解析:xml.dom.Node》专栏深入探讨了xml.dom.Node库,揭示了其20大奥秘和实践技巧。文章涵盖了高级技巧、最佳实践、性能优化、源码解读、实战案例、大型文件处理、库比较、企业应用、错误处理、多线程并发、Web开发、JSON互转、大数据处理和物联网数据处理等方面。通过深入的分析和丰富的案例,该专栏旨在帮助读者全面掌握xml.dom.Node库,高效处理XML数据,解决复杂XML解析问题,并应对企业级应用中的挑战。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【行存储数据分布的管理】:平衡负载,提高效率的策略与实现
# 1. 行存储数据分布的基本概念
## 理解行存储
行存储,也称为行式存储或行主序存储,是一种数据存储格式,它将数据表中的一条记录(一行)的所有字段值连续存储在一块儿。这种存储方式适合OLTP(在线事务处理)系统,因为这些系统中的查询常常是针对单个或者少数几条记录进行的。与之相对的,列存储(列式存储或列主序存储)则更适合OLAP(在线分析处理)系统,这些系统中查询会涉及到大量行,但仅涉及少数几个字
【HDFS副本放置策略】:优化数据恢复与读取性能的关键
# 1. HDFS副本放置策略概述
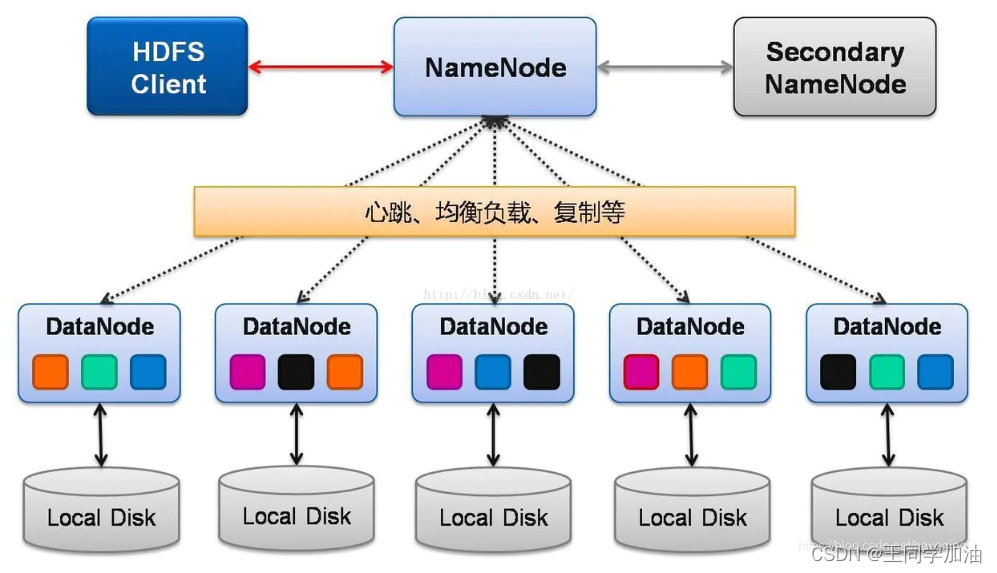
随着大数据时代的到来,Hadoop分布式文件系统(HDFS)作为大数据存储与处理的核心组件,其副本放置策略对于系统的稳定性和性能至关重要。副本放置策略旨在确保数据的可靠性和高效的读取性能。本章将简要介绍HDFS副本放置策略的基本概念,并概述其在大数据环境中的应用场景和重要性。
HDFS通过在多个数据节点上存储数据副本,来保障数据的可靠性。每个数据块默认有三个副本,
HDFS副本机制的安全性保障:防止数据被恶意破坏的策略
# 1. HDFS副本机制基础
## 简介
Hadoop Distributed File System(HDFS)是大数据生态系统中用于存储大规模数据集的分布式文件系统。其设计的主要目标是容错、高吞吐量以及适应于各种硬件设备的存储。副本机制是HDFS可靠性和性能的关键因素之一。副本存储多个数据副本来确保数据的安全性与可用性,即使在部分节点失效的情况下,系统依然能够维持正常运
【Hadoop网络拓扑】:DataNode选择中的网络考量与优化方法

# 1. Hadoop网络拓扑简介
Hadoop网络拓扑是分布式计算框架中一个关键的组成部分,它负责数据的存储和处理任务的分配。本章将简要介绍Hadoop网络拓扑的基础知识,为深入理解后续内容打下基础。Hadoop的网络拓扑不仅决定了数据在集群中的流动路径,而且对整体性能有着直接的影响。
## 2.1 Hadoop网络拓
NameNode故障转移机制:内部工作原理全解析
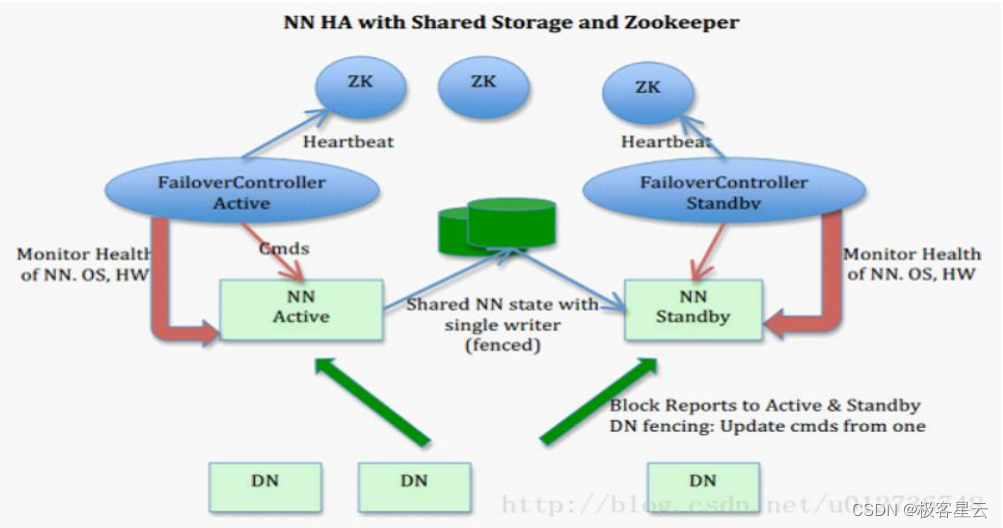
# 1. HDFS与NameNode概述
Hadoop分布式文件系统(HDFS)是Hadoop的核心组件,支持大量数据的存储与访问,是大数据分析的基石。本章将简述HDFS的基本概念,包括其分布式存储系统的特性以及体系结构,并将详细探讨NameNode在HDFS中的核心角色。
## 1.1 HDFS的基本概念
### 1.1.1 分布式存储系统简介
分布式存储系统是设计用来存储和管理大规模数据的系统,它
【低成本高效能存储】:HDFS副本放置策略实现指南
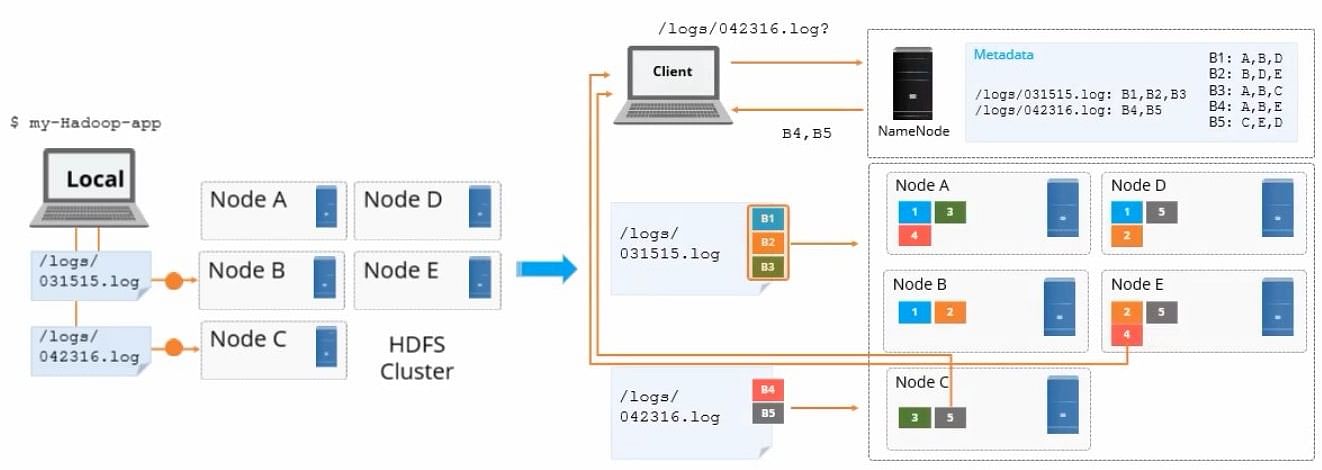
# 1. HDFS存储基础概念
## 1.1 Hadoop分布式文件系统概述
Hadoop分布式文件系统(HDFS)是一种分布式存储解决方案,专为大规模数据集的存储和处理而设计。它是Apache Hadoop项目的核心组件,提供高吞吐量的数据访问,适合运行在廉价的商用硬件上。
## 1.2 HDFS的结构与组件
HDFS采用了主从(Maste
Hadoop文件传输实战:构建高效pull与get数据传输管道的详细指南

# 1. Hadoop文件传输基础知识
## 1.1 Hadoop分布式文件系统简介
Hadoop作为一个开源框架,支持数据密集型分布式应用,并通过其核心组件Hadoop分布式文件系统(HDFS)提供了存储超大文件集的能力。HDFS设计为能够跨大量廉价硬件运行,同时能够提供高吞吐量的数据访问,这对于大规模数据集的应用程序来说至关重要。
## 1.2 文件传输在Hadoop
升级无烦恼:HDFS列式存储版本升级路径与迁移指南
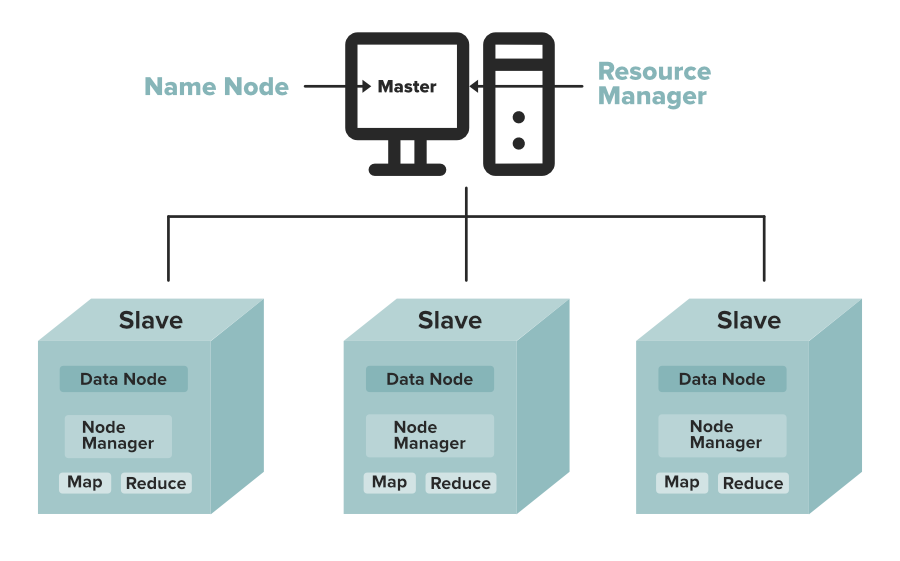
# 1. HDFS列式存储概述
## 1.1 HDFS列式存储的概念
HDFS(Hadoop Distributed File System)是Hadoop项目的核心组件之一,它是一个高度容错的系统,设计用来运行在低廉的硬件上。列式存储是一种与传统行式存储不同的数据存储方式,它将表中的数据按列而非按行存储。在列式存储中,同一列的数据被物理地放
HDFS数据备份与恢复:5步走策略确保灾难恢复与数据安全
# 1. HDFS数据备份与恢复概述
随着大数据技术的日益普及,数据的可靠性与安全性成为企业关注的焦点。HDFS(Hadoop Distributed File System)作为大数据存储的核心组件,其数据备份与恢复机制显得尤为重要。本章首先概述HDFS数据备份与恢复的重要性,随后将深入探讨HDFS备份的理论基础、实践操作以及灾难恢复计划的制定
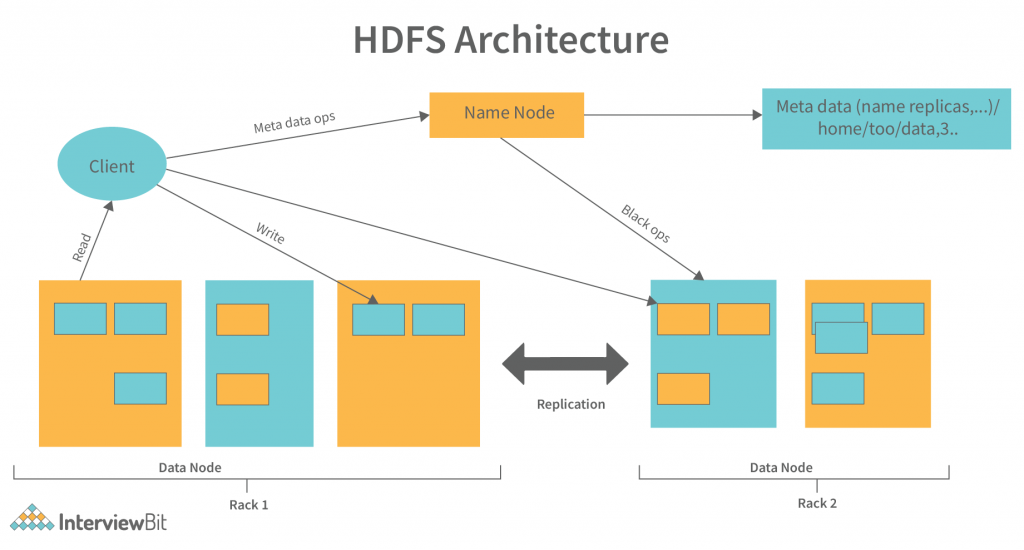
【HDFS数据格式详解】:Map-Side Join的最佳实践,探索数据格式与性能的关系
# 1. HDFS数据格式基础知识
在分布式计算领域,Hadoop Distributed File System(HDFS)扮演了数据存储的关键角色。HDFS通过其独特的设计,如数据块的分布式存储和复制机制,保障了大数据的高可用性和伸缩性。在深入探讨HDFS数据格式之前,理解其基本概念和架构是必不可少的。
## HDFS的基本概念和架构
HDFS采用了主/从(Master/Slave)架构,其中包括一个NameNode(主节点)和多个DataNode(数据节点)。Nam
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )