Hadoop大数据与云计算实战:MapReduce、HBase、Hive核心解析
需积分: 10 109 浏览量
更新于2024-09-14
收藏 67KB DOCX 举报
“大数据 云计算 分布式 hadoop 实践”
本文将深入探讨Hadoop在大数据和云计算领域的应用,以及如何通过最佳实践实现高效的数据处理和存储。Hadoop作为当前云计算大数据处理的主流框架,它的核心价值在于提供了一个分布式计算和存储的平台,使企业能够处理大规模、复杂的数据,同时保持高可靠性和可扩展性。
Hadoop的主要组成部分包括MapReduce、HDFS(Hadoop Distributed File System)和YARN(Yet Another Resource Negotiator)。MapReduce是Hadoop的并行计算模型,用于处理和生成大数据集;HDFS则提供了高容错性的分布式文件系统,支持PB级别的数据存储;YARN作为资源管理器,负责任务调度和集群资源分配。
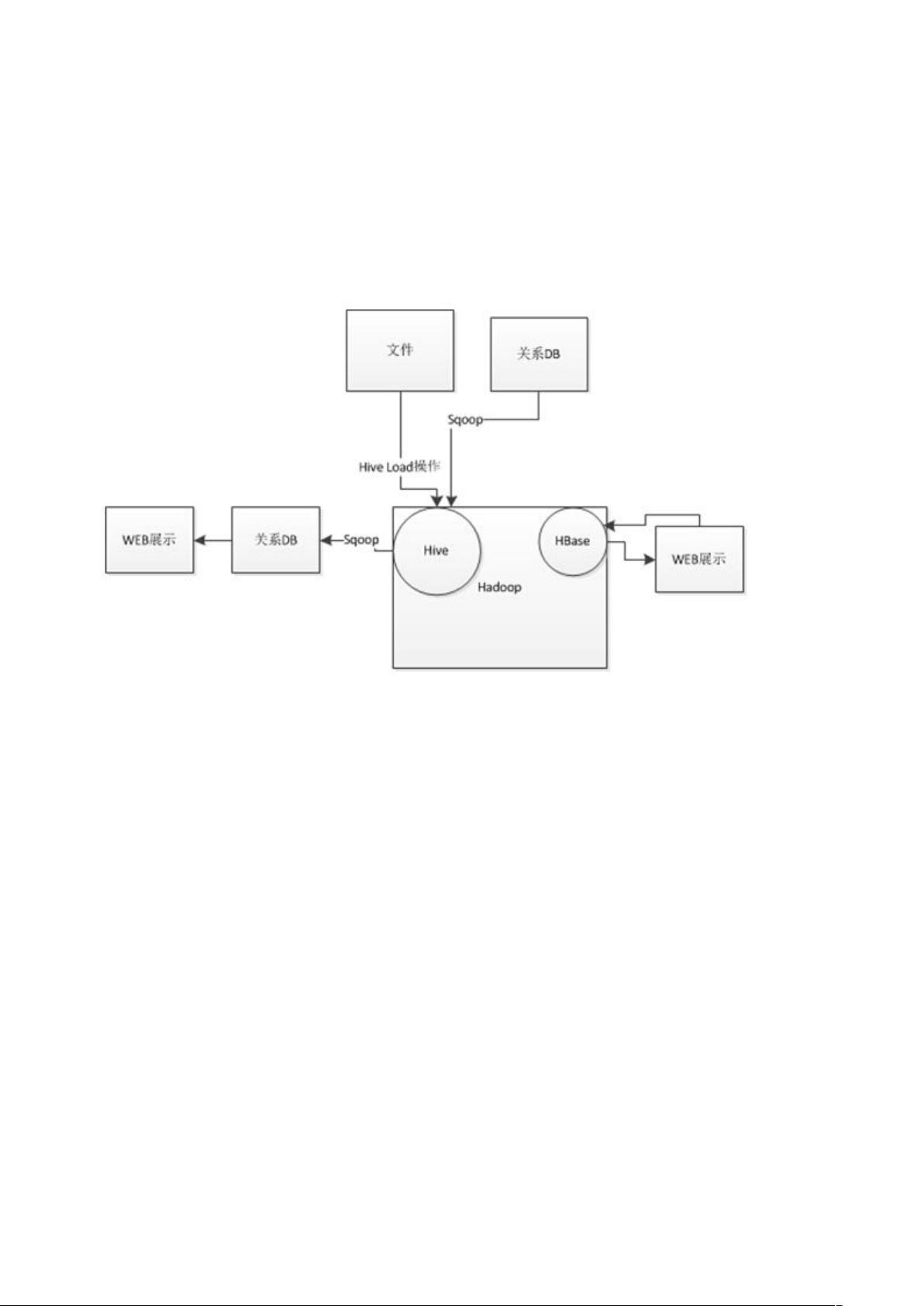
在实际应用中,Hadoop通常用于构建离线处理平台,处理海量的非结构化或半结构化数据,如日志分析、社交媒体数据挖掘等。Hive作为一个基于Hadoop的数据仓库工具,可以简化SQL-like查询,使得非Java背景的开发者也能方便地进行数据分析。而HBase,作为Hadoop生态系统中的NoSQL数据库,提供了实时读写能力,适用于需要快速访问历史数据的场景。
课程内容涵盖从Hadoop开发环境的搭建到具体应用案例的实现,例如图片服务器、WordCount示例、基于HBase的微博系统、话单查询统计、Hive数据统计等,旨在让学习者通过理论与实践相结合的方式,掌握Hadoop的核心技术。此外,课程还深入解析Hadoop源码,帮助学员理解其工作原理,提升对Hadoop框架的改造能力。
此课程特别适合已有一定Linux、网络和Java基础的云计算大数据从业者、软件工程师、数据库开发及运维人员、系统架构师等。对于那些需要处理大量数据的政府机构、金融机构、电信运营商以及互联网公司的负责人,以及高校和科研机构的相关项目负责人,也是极好的学习资源。
通过本课程的学习,学员将能够全面掌握Hadoop项目从分析、开发到部署的全过程,具备使用Hadoop解决实际问题的能力,并有可能进一步提升到改造和优化Hadoop框架的层次。这是一个深度和广度兼备的大数据处理实践课程,对于提升个人在大数据领域的专业技能有着显著的帮助。
一:课程简介:
Hadoop 是当下云计算大数据的王者。
Hadoop 不仅是一个大数据的计算框架,同时也是大数据的存储平台。
使用 Hadoop,用户可以在不了解分布式底层细节的情况下开发出分布式程序,从而可以使用
众多廉价的计算设备的集群的威力来高速的运算和存储,而且 Hadoop 的运算和存储是可靠的、高
效的、可伸缩的,能够使用普通的社区服务器出来 PB 级别的数据,是分布式大数据处理的存储的理
想选择
使用 Hadoop 可以主要完成:
1,构建离线处理平台,完成海量离线数据的存储分析,相对于传统的关系型数据库而言 ,
Hadoop 可以处理规模更大,处理逻辑更加复杂的内容,现在企业内部多使用以 Hive 为中心的
处理模式;
2,基于 Hadoop 的子项目 HBase 可以完成准实时的数据处理;
“云计算分布式大数据 Hadoop 最佳实践”基于实务经验萃取而成,从 Hadoop 开发环境的搭建
到到图片服务器、WordCount 实现、HBase 微博系统、话单查询与统计、Hive 数据统计案例、电
商业日志流量分析项目理论结合实际案例,祝你轻松驾驭 Hadoop 以满足大数据的分布式处理与存
储。
课程以 MapReduce、HBase、Hive 为主轴,想理解和使用 Hadoop,就必须掌握这三大核心。
尤其值得注意的是,在该课程的最新版本中加入了很多 Hadoop 框架本身的源码内核解析,这
直接为成为 Hadoop 奠定坚实的基础。
二:课程特色
Hadoop 领域 4 个开创先河
1,全程覆盖 Hadoop 的所有核心内容
2,全程注重动手实作,循序渐进中掌握 Hadoop 企业级实战技术
3,在授课的过程中会对 Hadoop 的核心源码进行深度剖析,使得学员具有改造 Hadoop 框架的能
力
4,具备掌握 Hadoop 完整项目的分析、开发、部署的全过程的能力
下载后可阅读完整内容,剩余6页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-09-29 上传
2021-09-05 上传
2021-09-29 上传
2021-09-05 上传
2021-09-05 上传
2021-09-29 上传

Lucosax-Yang
- 粉丝: 7
- 资源: 23
 我的内容管理
展开
我的内容管理
展开







最新资源
- 以Delphi Package架構多人開發應用程式環境.pdf
- 什么是基于实例的机器翻译系统?
- 空时码在相关快衰落瑞利信道下的性能
- 全面剖析C#正则表达式
- TMS320F2812中断系统分析及其C语言编程
- Oracle Database 10g for Windows安装 图文教程
- C#技巧集,里面有很多例子
- 本文提出了一种基于FPGA的通信...基于FPGA的通信系统基带验证平台的设计49784
- Linux下C语言编程入门(不是特别详细)
- 水晶报表的各种设计方法,水晶报表教程
- 计算机英语,完全英文版,英语好的可以尝试!
- Tomcat通过JNDI方式连接SqlServer数据库
- 很不错的汇编教材来下载把
- Hibernate需要注意的问题
- linux中职大赛企业网及园区网辅助练习题
- JavaScript使用技巧精萃
