HBase核心架构解析:HRegionServer与数据存储
148 浏览量
更新于2024-09-01
收藏 671KB PDF 举报
"HBase是一个分布式、版本化的NoSQL数据库,主要设计用于处理大规模数据集。其核心架构由多个关键模块组成,包括HRegionServer、Client、Zookeeper和Master。HBase利用Hadoop的HDFS作为底层存储系统,保证数据的高可用性和可扩展性。在HBase的工作流程中,数据的写入和读取通过特定的机制进行,如MemStore和StoreFile的管理,以及Zookeeper的角色等。"
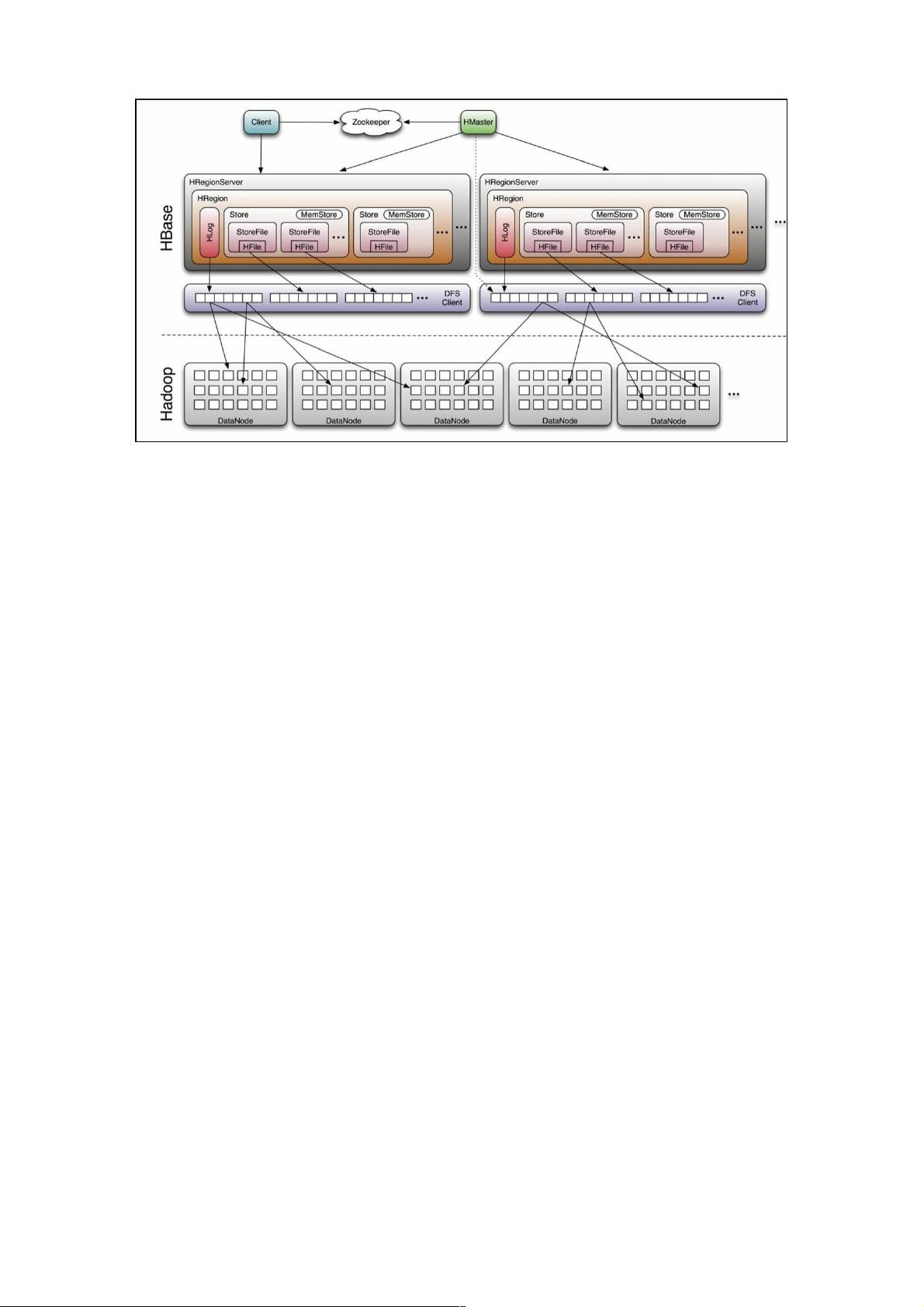
在HBase架构中,HRegionServer扮演了核心角色,它负责管理和存储数据。每个HRegionServer会打开并管理多个HRegion,这些Region是HBase数据存储的基本单位。对于每个表的HColumnFamily,HRegionServer会创建一个Store实例,Store又包含了多个StoreFile,它们是对HFile的轻量级封装,实际存储数据。写入数据时,首先会被写入HLog,确保数据的持久化,然后进入内存中的MemStore。由于MemStore的空间有限,当达到一定阈值时,MemStore会触发flush操作,将数据写入新的StoreFile中,这些文件最终被保存到HDFS上。
Client是用户与HBase交互的接口,它聚合了整个集群的信息,通过HBase RPC机制与HMaster和HRegionServer通信。Client还维护了一些缓存,如Region的位置信息,以加速访问。Zookeeper在HBase中起到关键的协调作用,确保只有一个活跃的HMaster,存储Region的寻址信息,监控RegionServer状态,并存储HBase的元数据。
Master是HBase的控制中心,它管理表格的生命周期,执行Region的分裂和重新分配,以及负载均衡。当RegionServer故障时,Master负责恢复操作,确保服务的连续性。然而,如果HMaster失效,虽然元数据的修改会暂停,但数据的读写仍能继续进行。
RegionServer是数据处理的前线,它负责维护Region,处理针对这些Region的I/O请求,包括读写操作。在Region过大或负载不平衡时,RegionServer会执行RegionSplit操作,将大Region分割为两个小Region,以优化性能。
HBase的架构设计使其能够高效地处理大规模数据,通过RegionServer、Client、Zookeeper和Master的协同工作,实现了数据的高可用性、可伸缩性和高性能。同时,其内存数据结构如MemStore和文件系统如StoreFile的管理策略,确保了数据的快速访问和稳定存储。
HBase架构核心模块架构核心模块
Hbase物理模型架构体系
hbase工作流程
HRegionServer负责打开region,并创建HRegion实例,它会为每个表的HColumnFamily(用户创建表时定义的)创建一个
Store实例,每个Store实例包含一个或多个StoreFile实例。是实际数据存储文件HFile的轻量级封装,每个Store会对应一个
MemStore。写入数据时数据会先写入Hlog中成功后在写入MemStore中。Memstore中的数据因为空间有限,所以需要定期
flush到文件StoreFile中,每次flush都是生成新的StoreFile。HRegionServer在处理Flush请求时,将数据写成HFile文件永久存
储到HDFS上,并且存储最后写入的数据序列号。
Client
(1)整合HBase集群的入口
(1)使用HBase RPC机制与HMaster和HRegionserver通信
(1)与HMaster通信进行管理类的操作
(1)与HRegionserver通信进行读写类操作
(1)包含访问hbase 的接口,client 维护着一些cache 来加快对hbase 的访问,比如regione 的位置信息
Zookeeper
保证任何时候,集群中只有一个running master,Master与RegionServers启动时会向ZooKeeper注册默认情况下,HBase 管
理ZooKeeper 实例,比如,启动或者停止ZooKeeperZookeeper的引入使得Master不再是单点故障
存贮所有Region 的寻址入口
实时监控RegionServer 的状态,将Regionserver 的上线和下线信息,实时通知给Master
存储Hbase的schema和table元数据
Master
管理用户对Table的增删改查操作
在RegionSplit后,分配新region的分配
负责regionserver的负载均衡,调整region分布
在RegionServer停机后,负责失效Regionserver上region的重新分配
HMaster失效仅会导致所有元数据无法修改,表达数据读写还是可以正常运行
Region Server
下载后可阅读完整内容,剩余7页未读,立即下载
点击了解资源详情
点击了解资源详情
2018-11-28 上传
2017-10-18 上传
2018-04-14 上传
2020-05-03 上传

weixin_38536841
- 粉丝: 3
- 资源: 946
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
