

10
类中心的类 C
j
从而得到 D 的一个聚类 C={c
1
, … ,c
k
}
5) 重复步骤 2)~ 4)若干次 以得到较为稳定的聚类结果
平面划分法特点是速度快 但种子选取难 k 要预先确定 而且这类方法
中大多数都是基于模型的算法 其中非常典型的就是 k-平均算法 它以 k 为参
数 把 n 个对象分为 k 个簇 以使簇内具有较高的相似度 而簇间的相似度较
低 相似度的计算根据一个簇中对象的平均值 被看作簇的中心 来进行 它
的处理流程如下 首先 随机选择 k 个对象 每个对象初始代表了一个簇的平
均值或者中心 对剩余的每个对象 根据其与各个簇中心的距离 将它赋给最
近的簇 然后重新计算每个簇的平均值 这个过程不断重复 直到准则函数收
敛 该算法的复杂度是 O(nkt) 其中 n 是所有对象的数目 k 是簇的数目 t 是
迭代的次数 通常 k<<n 且 t<<n 该算法对于 噪声 和孤立点
[20]
数据是
敏感的 该类中另外一种典型的算法是一次通过法 single-pass methods 它
只扫描数据库一次 就可完成分类 过程如下
1) 从数据库中读取一条记录 判断他距哪个类的距离最近
2) 如果即使到最近的类的距离比我们设定的距离相比还远 那么建立一
个新的类 把此记录放到此类中去
3) 如果数据库中还有记录转 1)
问题 数据库中记录的输入顺序和类内最大距离的设定 对分类的结果影响很
大
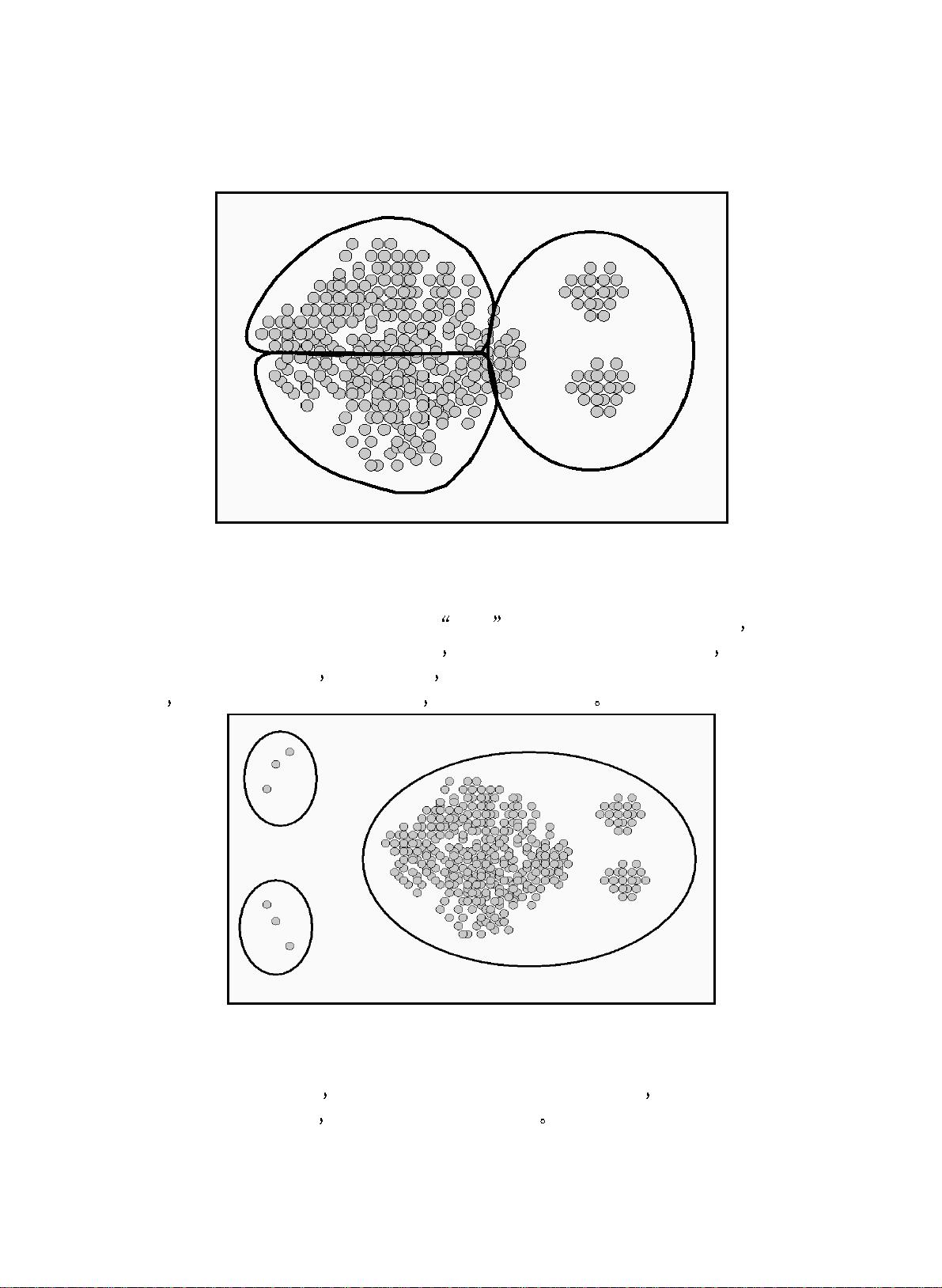
3.3 以往的聚类算法失败举例
前面谈到的聚类算法中大多数都产生球状
[21]
等尺寸的簇 因而都有其局
限性 下面举例加以说明 比如平均连通算法 完全连通算法 HAC 算法 k-
平均算法和一次通过算法 当处理的数据不符合其给定的模型时 这些算法就
很难执行 如图 3.1 所示 很多点分散在一个二维的空间平面中,各点之间的几
何距离代表它们的相似度 如果用平均连通算法, 完全连通算法, k-平均算法或
者一次通过法来对这些数据进行聚类 聚类的结果就会像图中所示的那样 其
中大簇会被分为两半 而这两半实际上却聚集在一起 说明用平均连通算法
完全连通算法, k-平均算法和一次通过算法来把数据分成三个簇时 它们会试
图产生球状的 等尺寸的簇 但是图中的数据点并不适合它们预先设定的模型
剩余53页未读,继续阅读















