深度解析自然语言处理中的词嵌入与序列模型
需积分: 0 198 浏览量
更新于2024-06-30
收藏 5.47MB PDF 举报
本资源是一份关于自然语言处理(Natural Language Processing, NLP)和词嵌入技术的详细教学材料,主要涵盖第五课的内容。课程分为多个部分,从词表示(Word Representation)的基本概念开始,深入探讨了如何利用词嵌入(Word Embeddings)进行语言处理。
2.1 节中介绍了词表示,这是理解文本数据的关键,包括将文本中的每个单词转换成数值向量以便计算机处理。常见的词表示方法有基于one-hot编码的表示方式,虽然直观但维度较高,计算效率较低。
2.2 部分则讲解了如何使用词嵌入,如Word2Vec算法,它通过预测上下文单词来学习单词的分布式表示,解决了one-hot编码的局限性,使得词与词之间的语义关系在向量空间中得以体现。
2.3 重点讨论了词嵌入的一些特性,如它们能够捕捉到词的相似性和上下文相关性,这对于诸如情感分类(Sentiment Classification)这样的任务非常关键。
2.4 和2.5 部分深入讲解了词嵌入矩阵(Embedding Matrix)的概念和学习过程,展示了如何通过训练模型来动态学习和优化词向量。
2.6 Word2Vec是这里的核心技术之一,它包括连续词袋模型(CBOW)和Skip-Gram两种主要变体,每种都有其独特的训练策略。
2.7 负采样(Negative Sampling)是Word2Vec的一种优化技术,通过减少负样本的数量来加速训练,同时保持词向量的准确性。
2.8 GloVe (Global Vectors for Word Representation) 是另一种流行的预训练词嵌入模型,它通过全局统计信息来学习词向量,提供了一种不同的方法来量化词的语义。
2.9 课程还涉及了情感分类应用,展示了如何利用词嵌入技术进行文本分析,识别文本的情感倾向。
2.10 最后,2.10 节探讨了如何对词嵌入进行去偏见(Debiasing Word Embeddings),以减少性别、种族等社会偏见在词向量中的反映。
此外,教学材料还提到了RNN(循环神经网络)、GRU(门控循环单元)和LSTM(长短时记忆网络)在NLP中的应用,以及它们与词嵌入的结合,强调了深度学习在NLP领域的核心作用。
整个课程内容详实,从理论到实践,覆盖了词表示的基础到高级应用,对于理解和掌握自然语言处理中的词嵌入技术具有很高的价值。
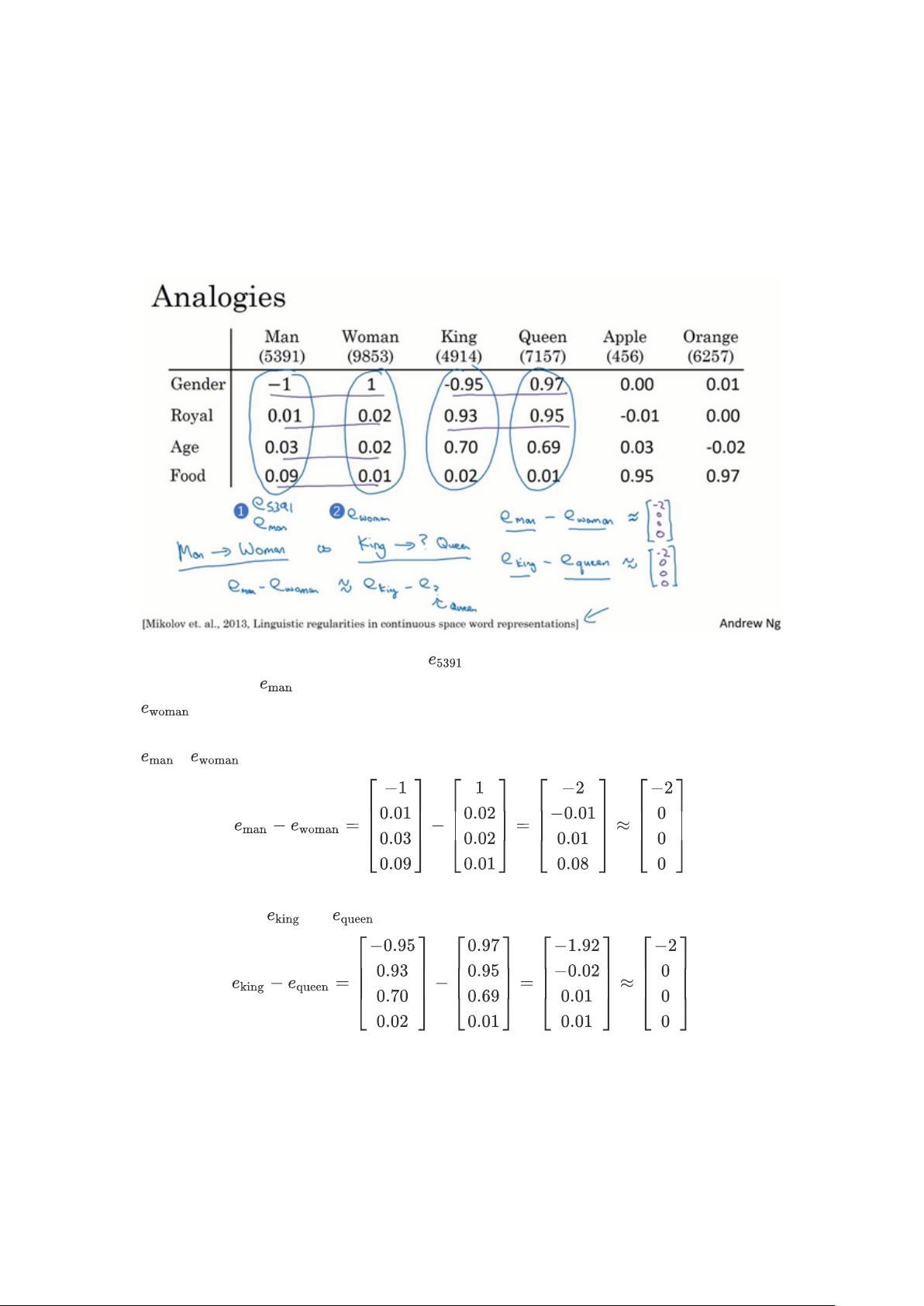
2.3 Properties of Word Embeddings
man
womankingkingqueen
man
1 2woman
kingqueen
501000
http://www.ai-start.com/dl2017/html/lesson5-week2.html 2018/4/27 下午10=47
第 7 (共 34 )
剩余33页未读,继续阅读
2022-08-04 上传
2022-08-04 上传
2023-06-06 上传
2023-06-03 上传
2024-03-07 上传
2023-06-09 上传
2023-06-08 上传
2023-04-15 上传
2023-09-08 上传

代码深渊漫步者
- 粉丝: 17
- 资源: 320
 我的内容管理
展开
我的内容管理
展开







最新资源
- Lombok 快速入门与注解详解
- SpringSecurity实战:声明式安全控制框架解析
- XML基础教程:从数据传输到存储解析
- Matlab实现图像空间平移与镜像变换示例
- Python流程控制与运算符详解
- Python基础:类型转换与循环语句
- 辰科CD-6024-4控制器说明书:LED亮度调节与触发功能解析
- AE particular插件全面解析:英汉对照与关键参数
- Shell脚本实践:创建tar包、字符串累加与简易运算器
- TMS320F28335:浮点处理器与ADC详解
- 互联网基础与结构解析:从ARPANET到多层次ISP
- Redhat系统中构建与Windows共享的Samba服务器实战
- microPython编程指南:从入门到实践
- 数据结构实验:顺序构建并遍历链表
- NVIDIA TX2系统安装与恢复指南
- C语言实现贪吃蛇游戏基础代码
