实时数据流:构建实时分析管道详解
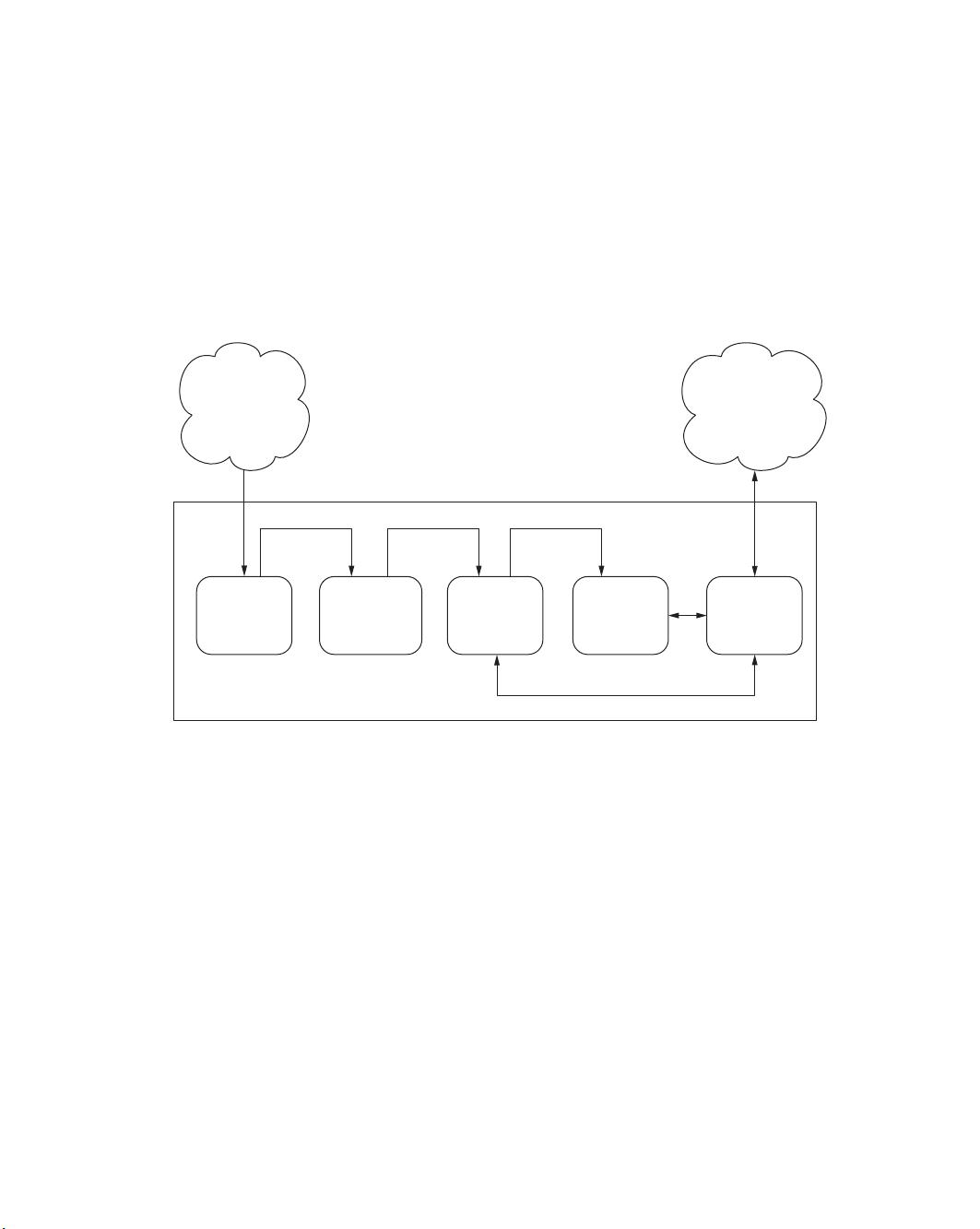
《实时数据流:理解实时管道》是一本深入讲解实时数据处理架构的书籍,作者是Andrew G. Psaltis。该书专注于介绍实时数据处理中的关键组件和工作流程,旨在帮助读者理解和构建高效、可扩展的实时数据管道。实时数据管道(Streaming Data Pipeline)通常包括以下几个主要阶段:
1. **数据收集**(Collection tier): 这是数据流的第一步,涉及从各种来源捕获数据,如浏览器、设备或自动售货机等。这些数据可能是用户行为、传感器读数或其他实时事件。
2. **消息队列**(Message queuing tier): 在这个阶段,收集到的数据被发送到一个消息队列系统,如Kafka或RabbitMQ,确保数据在处理过程中按顺序传递,并且能够处理高并发流量。这有助于解耦数据生产者和消费者,提高系统的弹性和容错性。
3. **内存数据存储**(In-memory datastore): 数据被暂存于内存中,以便于快速访问和分析。内存数据库,如Redis或Memcached,用于存储热点数据,以减少延迟并提高处理速度。
4. **分析处理**(Analysis tier): 实时数据在内存中被进一步处理,通过实时分析工具(如Apache Storm、Flink或Spark Streaming)进行计算,执行复杂的查询和机器学习算法,以便即时生成见解。
5. **长期存储**(Long-term storage): 部分分析结果可能需要长期保存,即使不再需要实时更新。这通常涉及到将数据转移到持久化存储,如Hadoop HDFS或NoSQL数据库,以便后续查询和数据分析。
6. **数据访问**(Data access tier): 结果数据可能通过API接口提供给最终用户或应用程序,允许实时查看分析结果,或者作为服务的一部分被其他系统调用。
值得注意的是,尽管书中没有详细介绍持久化策略,但提到有时需要回溯已分析的数据,这表明实时管道的设计不仅要关注实时性能,还要考虑到数据的持久化和可访问性。此外,本书提供了一个全面的视角,但并非每个部分都详细讨论,对于特定的技术细节,读者可能需要参考更专业的资料进行深入研究。
《实时数据流:理解实时管道》这本书适合IT专业人士,特别是那些对实时数据处理和实时分析感兴趣的开发人员、数据工程师和数据科学家,它可以帮助他们构建和优化实时数据处理环境,满足不断增长的实时业务需求。如果你希望深入了解这一领域,这本书将为你提供坚实的基础和实用的指导。

ACKNOWLEDGMENTS
xiv
John Guthrie, Kosmas Chatzimichalis, Giuliano Bertoti, Carlos Curotto, Andy Kirsch,
Douglas Duncan, Jeff Smith, and Sergio Fernández González, Jaromir D.B. Nemec,
Jose Samonte, Jan Nonnen, Romit Singhai, Chris Allan, Jonathan Thoms, Steven Jenkins,
Lee Gilbert, Amandeep Khurana, Charlie Gaines. Without all of you, this book wouldn’t
be what it is today.
Many others contributed in various different ways. I can’t mention everyone by
name because the acknowledgments would just roll on and on, but a big thank you
goes out to everyone else who had a hand in helping make this possible!



剩余218页未读,继续阅读
2017-09-28 上传
2024-01-15 上传
2023-04-06 上传
2023-06-06 上传
2023-07-27 上传
2023-03-16 上传
2023-04-12 上传
2023-03-16 上传

ALo54
- 粉丝: 5
- 资源: 111
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
