词语相似度计算在云计算中的应用与研究
版权申诉
115 浏览量
更新于2024-07-02
收藏 2.98MB PDF 举报
"该文档是关于云计算环境下的词语相似度计算方法的研究,主要探讨了词义相似度在自然语言处理中的重要性和应用,包括词义消歧、机器翻译、语义资源建设、信息检索、多文档文摘、自动应答系统和文本分类等多个领域。文档首先介绍了词语相似度计算的意义和背景,特别强调了词义消歧的过程,指出词语的多义性是自然语言处理的一大挑战。词义消歧分为确定词语含义和识别具体使用含义两个阶段,通常借助词典资源,并通过计算词语在特定上下文中的词义相似度来实现。文档还提到了上下文和词义之间强度关系函数的概念,这在确定正确词义时起关键作用。"
本文档深入探讨了词语相似度计算在云计算环境中的应用,尤其是在处理大规模文本数据时的重要性。云计算技术提供了强大的计算能力和存储资源,使得复杂的自然语言处理任务如词义消歧成为可能。词语相似度计算是这些任务的核心部分,它可以帮助计算机理解并处理自然语言中的复杂含义,从而在多种应用场景中提供更准确的结果。
在词义消歧方面,文档指出,确定词语在特定上下文中的正确意义是关键。这通常涉及查找词典资源,例如《知网》、《同义词词林》和《现代汉语词典》,以获取词语的不同词义。然后,通过计算词语上下文C与各个词义Si的关系强度R(Si, C),可以识别出最相关的词义,从而解决多义词的问题。
在信息检索中,词语相似度用于评估文本与查询的语义匹配度,提高搜索结果的相关性。在机器翻译中,相似度计算有助于判断源语言中的词语是否可以被目标语言中的其他词语替换,以保持原文的含义。文本分类和自动应答系统同样依赖于词语相似度,前者用于确定文本所属的类别,后者用于理解用户输入并与领域文本进行匹配。
此外,多文档文摘系统利用词语相似度来整合多个文档的主题信息,而语义资源和语料库的建设则可以通过相似度计算提升效率和质量。总体而言,词语相似度计算在云计算环境中扮演着不可或缺的角色,为自然语言处理的各种任务提供了基础支持。

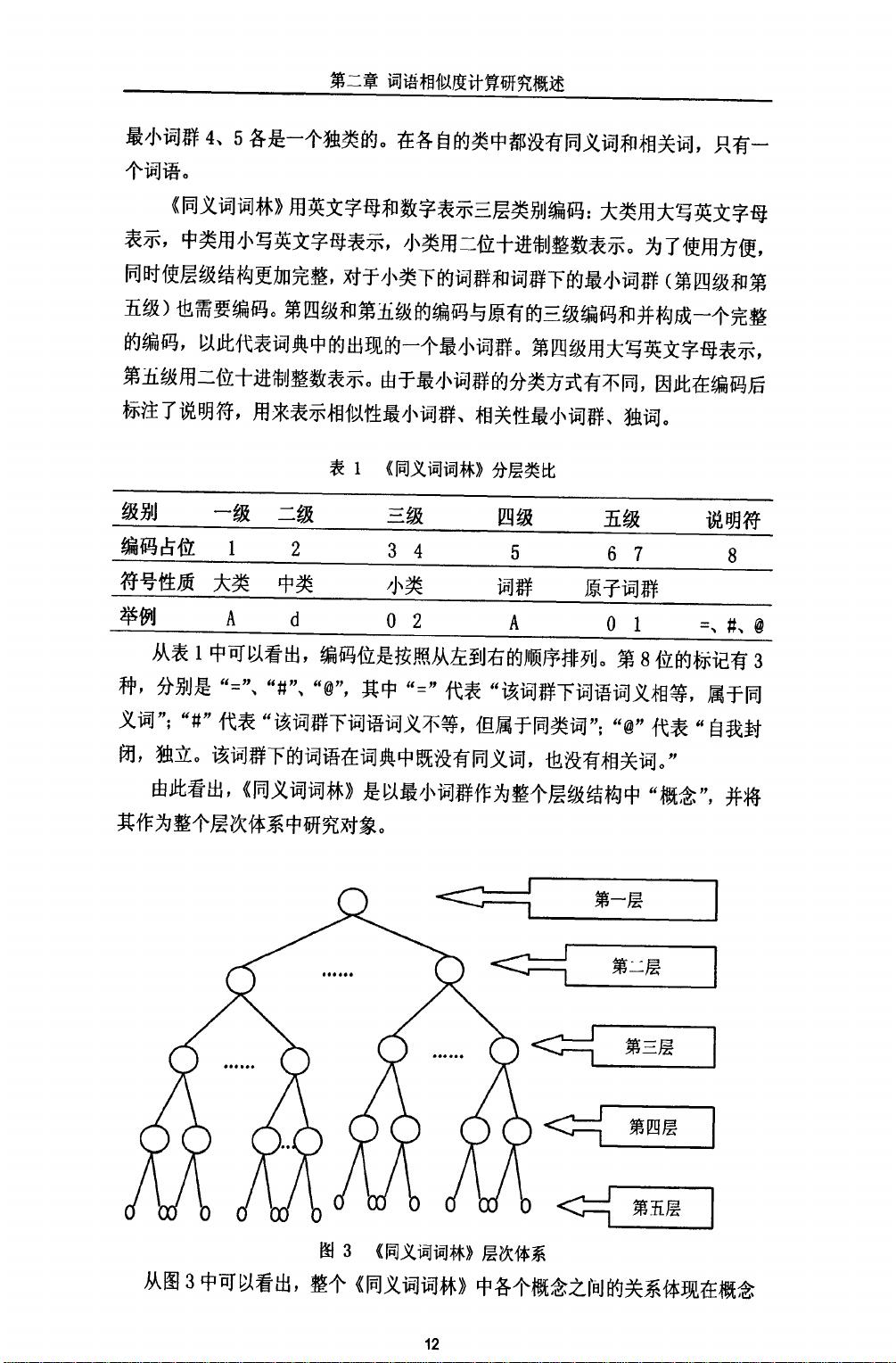
第二章词语相似度计算研究概述
事件、entity{实体、attribute
I属性、aValue
I属性值、quantity
I数量、qValue
I
数量值、SecondaryFeature次要特征、syntaxl语法、EventRoleI动态角色和
EventFeatures
f动态属性。图2是义原“Event
J事件"和“entity
l实体"两个
大类中的层次分类示意。从图2中可以看出义原“Event
I事件’’分为“static
静态"和“actI行动"两类,而这两个类中又可以继续在分为小类。“attributeI
属性”同样也分为若干类别,因此可以看出每一大类义原是一种层次的树状关系。
除此之外,各个义原之间的又有8种关系:上下位关系、同义关系、反义关系、
对义关系、属性一宿主关系、部件一整体关系、材料一成品关系、事件一角色关系。
义原之间的上下位关系和层次关系相互交织,组成的是一个复杂的网状结构,而
不是一个单纯的树状结构。
《知网》中的组织结构为:NO.为概念编号,W
C,G
C,E
C分别是汉语
的词语、词性和例子,W—E、G—E、E—E分别是英语的词语、词性和例子,DEF
是《知网》对于该概念的定义,也称之为一个语义表达式,其中DEF是《知网》
的核心。DEF并不是简单的义原集合,而是用专门“知识性描述语言”来表述
语义表达式。以词语“案’’为例,“案”有多个词义,选取其中主要的三个,因
而有三个“概念”描述:
i.词义:案卷;记录;提出计划.办法或者建议的文件
NO.=001860
旺C=案
£C=IV[en4J
E.C=有“霹查.簧1。教1.记录在“t
1卷。无W47,文’
W
E=document
G
E=N
巨庐
OEF={documeu
t/flE-移]
上例“案”的一个词义是“案卷;记录;提出计划、办法或者建议的文件",
在《知网》中的编号是“001860”,例子是“有’可查,备’,教’,记录在’,’
卷,无’可寻,文 ̄“,而DEF则是“案”在该词义表达式,是对该词义用义原来
描述。
2.词义:案件.案子
NO.=001867
WC=gi苣
C_C=N
ean43
E』=凶杀1,情杀‘.贪污1。盗窃“.受贿1。杀人1.窃1。办1。1铡.破1。犯1.1情。1子。
10

剩余55页未读,继续阅读
2021-02-22 上传
论文
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-05-15 上传

programxh
- 粉丝: 17
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- AirKiss技术详解:无线传递信息与智能家居连接
- Hibernate主键生成策略详解
- 操作系统实验:位示图法管理磁盘空闲空间
- JSON详解:数据交换的主流格式
- Win7安装Ubuntu双系统详细指南
- FPGA内部结构与工作原理探索
- 信用评分模型解析:WOE、IV与ROC
- 使用LVS+Keepalived构建高可用负载均衡集群
- 微信小程序驱动餐饮与服装业创新转型:便捷管理与低成本优势
- 机器学习入门指南:从基础到进阶
- 解决Win7 IIS配置错误500.22与0x80070032
- SQL-DFS:优化HDFS小文件存储的解决方案
- Hadoop、Hbase、Spark环境部署与主机配置详解
- Kisso:加密会话Cookie实现的单点登录SSO
- OpenCV读取与拼接多幅图像教程
- QT实战:轻松生成与解析JSON数据
