连续语义增强提升神经机器翻译性能
98 浏览量
更新于2024-06-19
收藏 1.01MB PDF 举报
连续语义增强:神经机器翻译的新性能里程碑
神经机器翻译(Neural Machine Translation, NMT) 是深度学习领域的一个重要分支,其核心任务是通过并行的源语言和目标语言句子对学习翻译模型,使得模型能够根据给定的源文本生成目标语言的相应文本。NMT模型的性能通常受到训练数据规模的显著影响,特别是对于资源匮乏的低资源语言对,数据扩充显得尤为重要。
传统的方法,如基于规则的数据扩充或基于统计的词对翻译,往往难以生成多样且忠实的训练样本,这限制了模型的泛化能力。为了解决这一问题,研究人员提出了连续语义增强(Continuous Semantic Augmentation, CSANMT)这一创新的数据扩充范式。CSANMT的独特之处在于,它在每个训练样本周围扩展一个连续的语义区域,这个区域包含了源语言中表达同一概念的不同词汇组合,从而丰富了训练数据的多样性。
在实际应用中,CSANMT已经在诸如WMT14 英语-德语、法语等高资源语言对以及NIST中国英语和多个低资源的IWITONS翻译任务中进行了广泛的实验验证。实验结果显示,与现有增强技术相比,CSANMT显著提升了神经机器翻译的性能水平,特别是在处理有限数据时,它能够更好地捕捉到语言的细微差异和复杂语义,从而提高翻译的准确性和流畅度。
通过实验证据,CSANMT证明了其在提升NMT技术标准方面的有效性,这对于推进神经机器翻译技术的发展具有重要意义。研究人员还提供了相关的核心代码供进一步研究者参考,这表明了CSANMT不仅是一个理论上的突破,也是可实践的技术手段。
总结来说,连续语义增强是一种有力的数据增强策略,它通过模拟自然语言的多样性和复杂性,增强了神经机器翻译模型的泛化能力,为解决资源受限的翻译问题提供了一种新的解决方案,并在实际应用中展现了显著的优势。随着研究的深入,这种方法有望在未来的机器翻译领域中发挥更大的作用。
+v:mala2277获取更多论
文
R
∈
X Y
·
R {}
ǁ −ǁ
Σ
·
B
C
Σ
输出概率
Softmax
解码器
添加规范
前馈
添加规范
编码器
多头
关注
添加规范
Feed
广播
前向
一体化
添加规范
多头
注意
添加规范
屏蔽
多头
注意力
位置编
码
语义
编码
器
位置编
码
图1:CSA NMT的框架。
定义
1.
神经
机器翻译的源语言和目标语言之
间存在一个通用的语义空间,该语义空间
由
语义编码器建立。 它定义了一个前向函数
,
将离散的句子映射成连续的向量,满足:
(x
,
y)(
,
):
r
x
=
r
y
。此外,语义空间
中的邻接语义区域
ν
(
r
x
,
r
y
)
描述了以每
个观察到的句子对
(x
,
y)为中心的足够
的字面表达变体
。
在我们的场景中,我们首先从邻接语义区
域中采样一系列向量(表示为 )以增
强当前训练实例,
即
=
r
(
1
)
,
r
(
2
)
,
.
,
r
∈
(
K
)
,
其中
r
∈
(
k
)
v
(
r
x
,
r
y
)
.
K
是决定
采样向量数量的超参数。
然后
,每个
样本
r
(
k
)
通过
广播集成网络
被
集成到生成过程
o
t
=
W
1
r
t
(
k
)
+
W
2
o
t
+
b
,
(
2
)
其中
0
t
是自注意模块在位置
t
处
的输出。 最
后,
Eq
中的训练目标
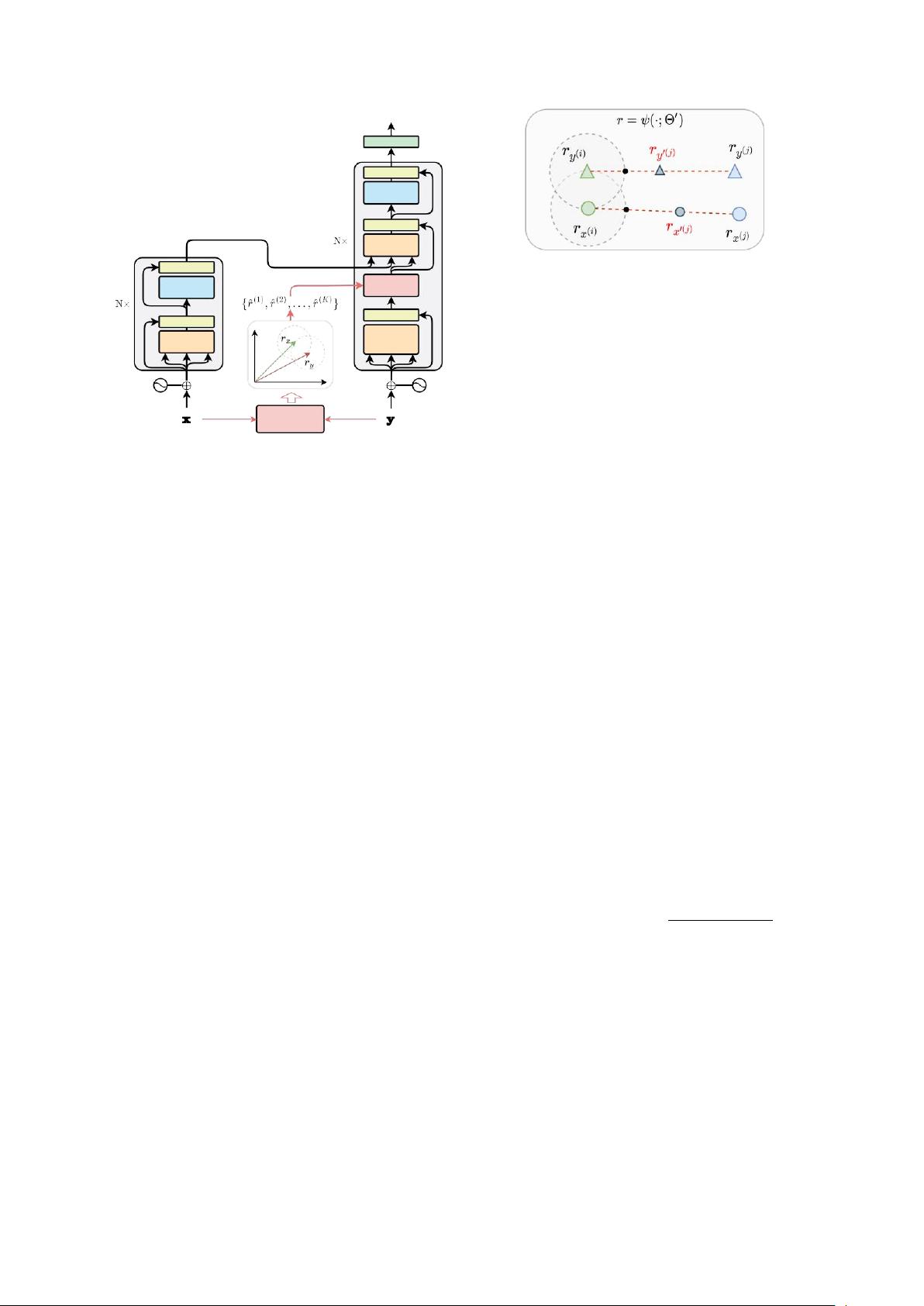
图2:为句子对(
x
(
i
)
,
y
(
i
)
)制定邻接语义区域
的示意图。
(2)
如何快速有效地从相邻序列区域中获取样
本。
在本节的其余部分,我们分别介绍了这两
个问题的解决方案。
切线对比学习我们从分析邻接语义区域的几
何 解 释 开 始 。 示 意 图 如 图
2
所 示 。 令 ( x
(
i
)
,
y
(
i
)
)和(x
(
j
)
,
y
(
j
)
)是从训练语料
库中随机采样的两个实例。对于(x
(
i
)
,
y
(
i
)
),
ad-
jacency
语义区域
v(
rx
(i )
,
ry
( i)
)
被定义
为分别
以
rx
(i)
和
ry
(i)
为中心的两个闭球的
并集
.
两者的半径
balls
是
d
=r
x
(
i
)
ry
(
i
)
2
,也被认为是
-
作为确定语义等价的松弛变量。潜在的解释
是,
与
rx
(i)
(或
ry
(i)
)的距离
不超过
d
的向量在
语义上等同于
rx
(
i
)
和
ry
(
i
)
。 使
ν
(
r
x
(
i
)
,
r
y
(
i
)
)符合
解释,我们采用类似的方法,
在(Zheng et al. ,2019; Wei et al. ,2021)以利
用切向对比度来优化语义编码器。具体来说,
我们通过在当前实例和同一训练批中的其他实
例之间应用凸插值来和切点(即,边界上的
点)被认为是语义等价的临界状态。
培训目标如下:
我
的
天
r
(
i
)
,
r
(
i
)
,
(1)
能够提高
J
ctl
(Θ
′
)
=E
(
x
㈠
)
,
y
(i)
)
日
志
是
的
。
R
X
x
(i
)
y
、
,
r
y
(
i
)
公司
简
介
J
mle
(Θ)
=E
(
x
,
y
)
<$C
,
r
<$
(
k
)
.
log
P(
y
|
x
,
r
(
k
)
;
Θ
)
.
(三)
|B|
=
.
是
的
。
R
y
(
i
)
,
r
y
'
(
j
)
+
e
s
。
rx
(
i
)
,
rx
'
(
j
)
但是
,
通过用来自邻接语义区域的不同样本来扩充训
练实例(x
,
y)
jj
/
=
i
(四
)
该模型有望推广到更多不可见的实例。为此,
我们必须考虑这样两个问题:(1)
如何优化
语义编码器,使其为每个观察到的训练对产
生有意义的邻接语义区域。
其中表示从训练语料库中随机选择的一批句子
对,
s
()是计算两个向量之间负样本
rx
′
(
j
)
和
ry
′
(
j
)
被设计为如下形式:
∈R
剩余14页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
论文
论文
论文
论文
论文

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- AirKiss技术详解:无线传递信息与智能家居连接
- Hibernate主键生成策略详解
- 操作系统实验:位示图法管理磁盘空闲空间
- JSON详解:数据交换的主流格式
- Win7安装Ubuntu双系统详细指南
- FPGA内部结构与工作原理探索
- 信用评分模型解析:WOE、IV与ROC
- 使用LVS+Keepalived构建高可用负载均衡集群
- 微信小程序驱动餐饮与服装业创新转型:便捷管理与低成本优势
- 机器学习入门指南:从基础到进阶
- 解决Win7 IIS配置错误500.22与0x80070032
- SQL-DFS:优化HDFS小文件存储的解决方案
- Hadoop、Hbase、Spark环境部署与主机配置详解
- Kisso:加密会话Cookie实现的单点登录SSO
- OpenCV读取与拼接多幅图像教程
- QT实战:轻松生成与解析JSON数据
