腾讯灯塔Impala优化探索:从挑战到实践
版权申诉
85 浏览量
更新于2024-07-05
收藏 10.99MB PDF 举报
"10-5+Impala在腾讯灯塔的优化和实践.pdf"
本文主要介绍了腾讯灯塔团队在使用Impala进行大数据分析时所遇到的挑战以及他们实施的一系列优化策略。腾讯灯塔是一个大数据分析平台,其目标是为产品、研发、运营和数据科学团队提供快速、可靠的决策支持,助力用户增长和留存。平台每天处理大量数据,包括日接入量50000亿、日查询次数40万+、集群存储量200PB+,并保持99.9%的查询成功率SLA。
在面对一系列挑战时,腾讯灯塔团队主要针对Impala进行了优化,Impala是一种高性能的MPP(大规模并行处理)查询引擎,用于实时分析存储在Hadoop生态系统中的数据。以下是一些关键的优化点:
1. **Kudu RowSet写入瓶颈**:Kudu是Impala的一个列式存储组件,负责快速写入和更新数据。腾讯灯塔团队发现了写入瓶颈,并通过修复两个社区Bug (IMPALA-9566和IMPALA-10310) 来提升性能。
2. **Parquet RowGroups和PageIndex合理性**:Parquet是一种高效的列式存储格式,RowGroups和PageIndex影响了数据读取效率。团队发现排序热谓词可能导致数据压缩比下降,他们尝试生成z-order数据以提高多字段的全局最优压缩。
3. **HDFS大扫描压力与Alluxio-SSD加速IO**:面对HDFS扫描压力,团队引入Alluxio作为内存计算层,利用SSD加速I/O操作,以提高数据读取速度。
4. **Impala KRPC在高并发下的问题**:KRPC是Impala内部通信协议,高并发查询下性能会线性衰减。团队对此进行了优化,可能涉及调整并发控制和改进协议效率。
5. **ScanRange问题导致的IOThread随机读加剧**:在高并发查询中,由于scanrange过小和大字段、多列宽表,导致了IOThread的随机读取增加,从而影响性能。团队通过调整scanrange大小和优化数据布局来改善这一状况。
6. **复杂大查询的runtime识别与拦截**:对于消耗资源的复杂查询,团队建立了性能分析中心,实现分析驱动的治理,提前识别和拦截可能影响系统性能的查询。
7. **构建查询“性能分析中心”**:这个中心支持对查询性能的深度分析和监控,帮助团队更好地理解查询行为,进行针对性优化。
通过这些深入的优化,腾讯灯塔能够持续提升Impala的处理能力和响应时间,确保大数据分析的敏捷性和准确性,从而为业务决策提供强有力的支持。
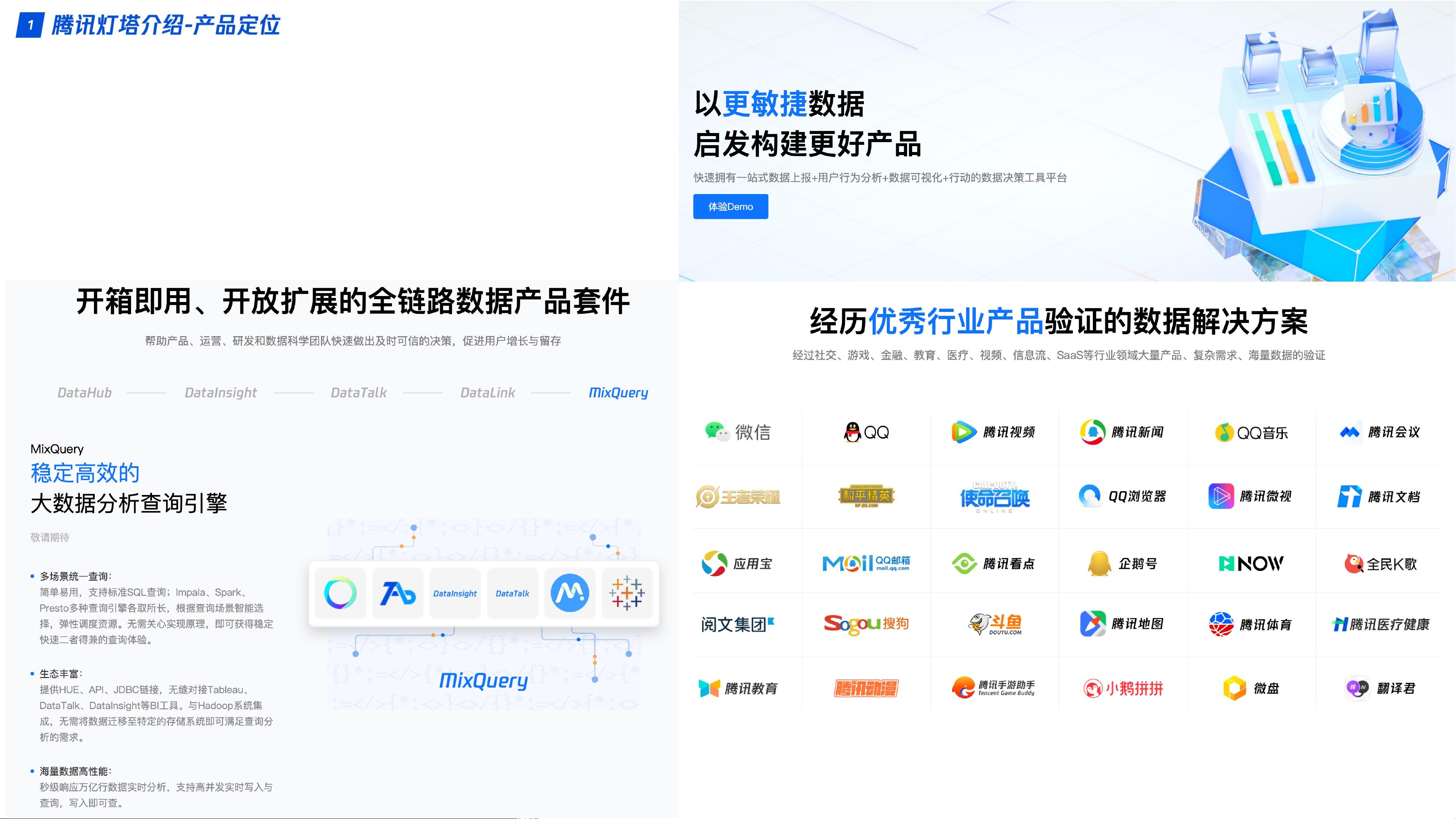
帮助产品、研发、运营和数据科学团队30分钟内
做出更可信及时的决策,促进⽤户增长和留存。
https://beacon.tencent.com
剩余21页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-03-18 上传
2022-03-18 上传
2022-03-18 上传
2019-05-09 上传
2022-03-18 上传

普通网友
- 粉丝: 13w+
- 资源: 9195
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
