SparkSQL与大数据平台实战
需积分: 35 191 浏览量
更新于2024-07-20
收藏 3.21MB PDF 举报
"SparkSQL原理和实践 - 炼数成金讲义"
本文将深入探讨SparkSQL的原理和实践应用,它是Apache Spark项目中的一个组件,允许用户通过使用SQL语句来处理和分析数据。SparkSQL是Apache Spark的一个重要部分,它结合了Spark的核心计算能力与SQL的便利性,使得数据科学家和分析师可以更加便捷地操作大规模数据。
首先,我们需要回顾一下Spark的运行架构。Spark的核心是弹性分布式数据集(RDD),这是一种容错的、可并行操作的数据集合。Spark的工作流程由调度器负责,包括TaskScheduler和不同的ClusterScheduler(如YarnClusterScheduler和YarnClientClusterScheduler)。这些调度器确保任务在集群中的有效分配和执行。
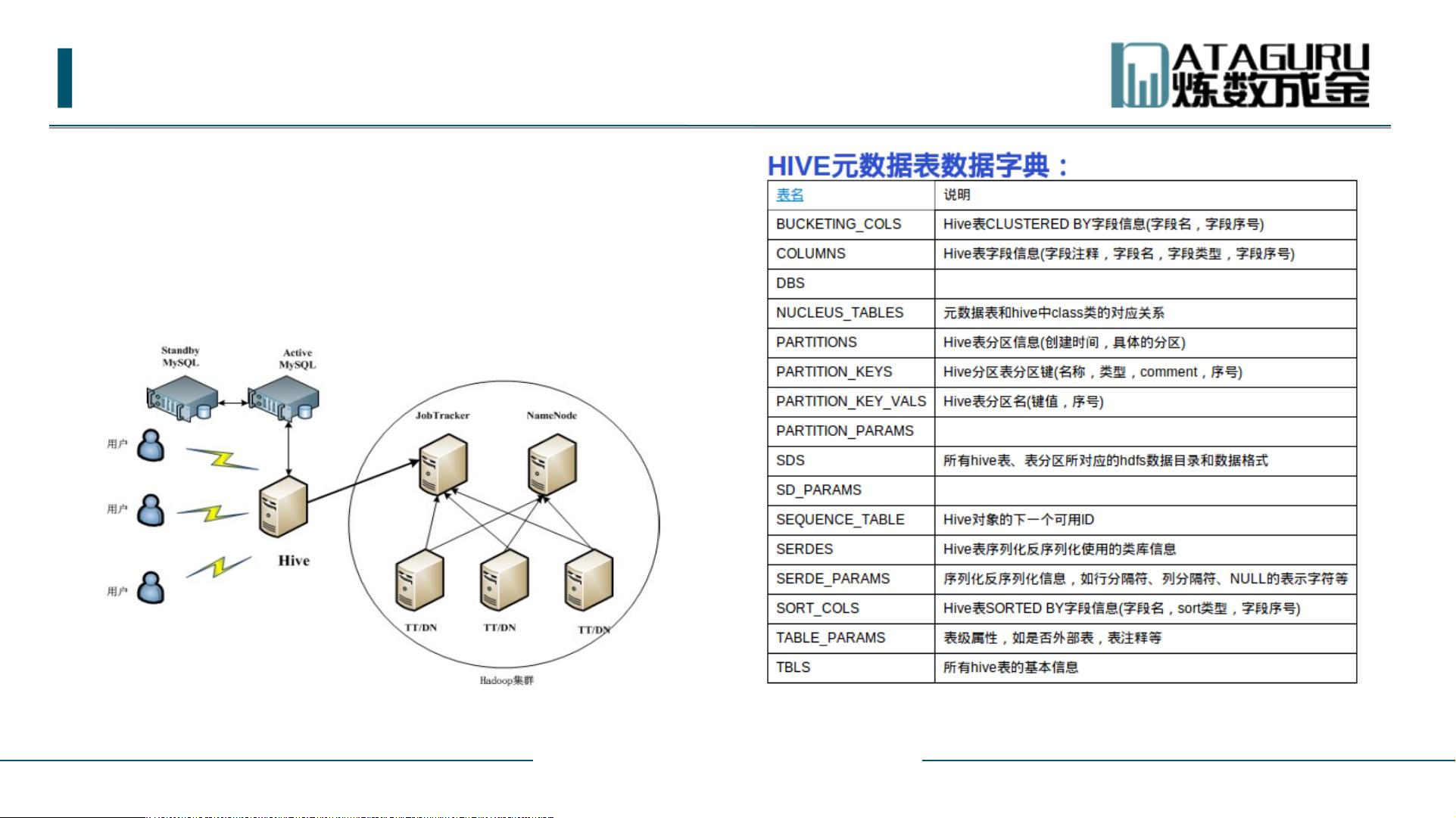
接下来,我们提到了Hive,一个由Facebook开源的用于处理大量结构化日志数据的工具。Hive基于Hadoop的HDFS和MapReduce,提供了SQL-like的查询接口(HQL)和数据仓库功能,适合对结构化和非结构化数据进行管理和查询。Hive的设计目标是使不熟悉Java的分析师也能高效地查询大规模数据。
然后,我们提到了Shark,它是Hive的一个早期分支,旨在提供更快的查询性能。Shark利用Spark的计算引擎,但在当时并未能完全替代Hive,因为它的兼容性和功能有所限制。
而SparkSQL正是在这样的背景下应运而生,它吸收了Shark的优点,同时改进了性能和兼容性。SparkSQL通过DataFrame API,允许用户以一种类型安全的方式操作数据,并且支持多种数据源,如HDFS、Hive、Cassandra等。DataFrame API能够透明地处理不同数据源的数据,提供了一致的编程接口。
SparkSQL的架构设计基于Spark Core,它将SQL查询转化为DataFrame操作,DataFrame进一步转化为RDD操作执行。这种转换使得SparkSQL能够利用Spark的内存计算能力,实现快速的数据处理。此外,SparkSQL还支持Hive metastore,这意味着用户可以直接在SparkSQL中查询和使用已经在Hive中定义的表,增强了Spark与Hadoop生态系统的集成。
在实践中,SparkSQL提供了DataFrame API和SQL接口,使得开发人员可以选择更熟悉的编程方式。DataFrame API允许使用Scala、Java、Python和R进行编程,而SQL接口则直接支持标准的SQL语法,简化了复杂查询的编写。
总结来说,SparkSQL是Spark项目中用于结构化数据处理的重要组成部分,它融合了SQL的便利性和Spark的高性能计算能力。通过DataFrame和Spark Core的结合,SparkSQL在大数据分析领域提供了高效、灵活的数据操作解决方案。无论是对于数据科学家还是开发人员,SparkSQL都是处理大规模数据时的理想工具,它简化了数据处理流程,提升了数据处理效率,从而在大数据时代发挥了重要作用。



点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-03-19 上传
2024-03-06 上传
2022-07-01 上传
2018-03-28 上传
点击了解资源详情
点击了解资源详情

xiao9903
- 粉丝: 3
- 资源: 20
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入浅出:自定义 Grunt 任务的实践指南
- 网络物理突变工具的多点路径规划实现与分析
- multifeed: 实现多作者间的超核心共享与同步技术
- C++商品交易系统实习项目详细要求
- macOS系统Python模块whl包安装教程
- 掌握fullstackJS:构建React框架与快速开发应用
- React-Purify: 实现React组件纯净方法的工具介绍
- deck.js:构建现代HTML演示的JavaScript库
- nunn:现代C++17实现的机器学习库开源项目
- Python安装包 Acquisition-4.12-cp35-cp35m-win_amd64.whl.zip 使用说明
- Amaranthus-tuberculatus基因组分析脚本集
- Ubuntu 12.04下Realtek RTL8821AE驱动的向后移植指南
- 掌握Jest环境下的最新jsdom功能
- CAGI Toolkit:开源Asterisk PBX的AGI应用开发
- MyDropDemo: 体验QGraphicsView的拖放功能
- 远程FPGA平台上的Quartus II17.1 LCD色块闪烁现象解析
