

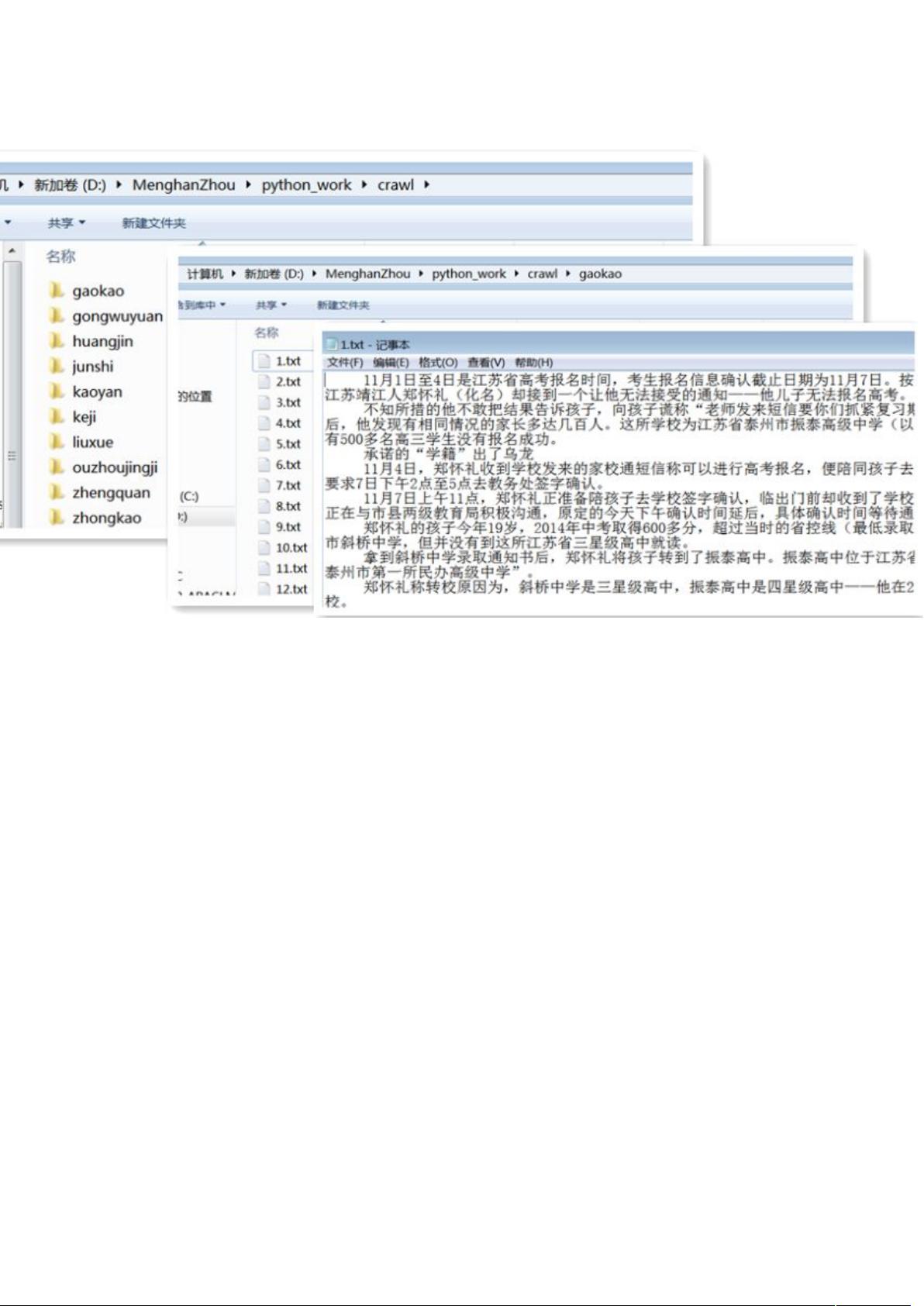
图 '%3考研资讯正文内容页面网页源代码
这里需要注意,我在写好程序爬数据的时候出现了程序报错这种情况,发现在某
篇文章处,根据标题链接 ,通过 "#&"#读取正文内容的时候报错。
其他都运行正常,为什么到这篇文章的时候读取不到了呢?定位到这篇文章,发现这
篇文章并不存在,即可能后台删除了正文文章但没有删除主页面的标题链接。所以在
这里我进行了 )&1H 异常处理,以便跳过这种文章情形。
依照这种爬取网页内容的方式,分析网页结构,我分别对新浪教育的考研资讯、
公务员资讯、高考资讯、留学资讯、中考资讯,新浪财经的黄金资讯、证券资讯、欧
洲经济资讯,新浪科技、新浪军事共 类新闻网页内容进行了抓取,各类别中文章数
目如表 ' 所示。
表 '3抓取文章类别及数目表
类别 考研 公务员 高考 留学 中考 黄金 证券 欧洲经济 科技 军事 总计
文章
数目
% % %%% +'% ' ' ' +
剩余51页未读,继续阅读

mini猿要成长QAQ
- 粉丝: 754
- 资源: 4
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 电力电子系统建模与控制入门
- SQL数据库基础入门:发展历程与关键概念
- DC/DC变换器动态建模与控制方法解析
- 市***专有云IaaS服务:云主机与数据库解决方案
- 紫鸟数据魔方:跨境电商选品神器,助力爆款打造
- 电力电子技术:DC-DC变换器动态模型与控制
- 视觉与实用并重:跨境电商产品开发的六重价值策略
- VB.NET三层架构下的数据库应用程序开发
- 跨境电商产品开发:关键词策略与用户痛点挖掘
- VC-MFC数据库编程技巧与实现
- 亚马逊新品开发策略:选品与市场研究
- 数据库基础知识:从数据到Visual FoxPro应用
- 计算机专业实习经验与项目总结
- Sparkle家族轻量级加密与哈希:提升IoT设备数据安全性
- SQL数据库期末考试精选题与答案解析
- H3C规模数据融合:技术探讨与应用案例解析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


