

CHAPTER 1. INTRODUCTION 2
given the computation pattern of deep learning and achieved higher efficiency compared with CPUs
and GPUs. The first wave of accelerators efficiently implemented the computational primitives for
neural networks [16, 18, 24]. Researchers then realized that memory access is more expensive and
critically needs optimization, so the second wave of accelerators efficiently optimized memory transfer
and data movement [19
–
23]. These two generations of accelerators have made promising progress in
improving the speed and energy efficiency of running DNNs.
However, both generations of deep learning accelerators treated the algorithm as a black box and
focused on only optimizing the hardware architecture. In fact, there is plenty of room at the top by
optimizing the algorithm. We found that DNN models can be significantly compressed and simplified
before touching the hardware; if we treat these DNN models merely as a black box and hand them
directly to hardware, there is massive redundancy in the workload. However, existing hardware
accelerators are optimized for uncompressed DNN models, resulting in huge wastes of computation
cycles and memory bandwidth compared with running on compressed DNN models. We therefore
need to co-design the algorithm and the hardware.
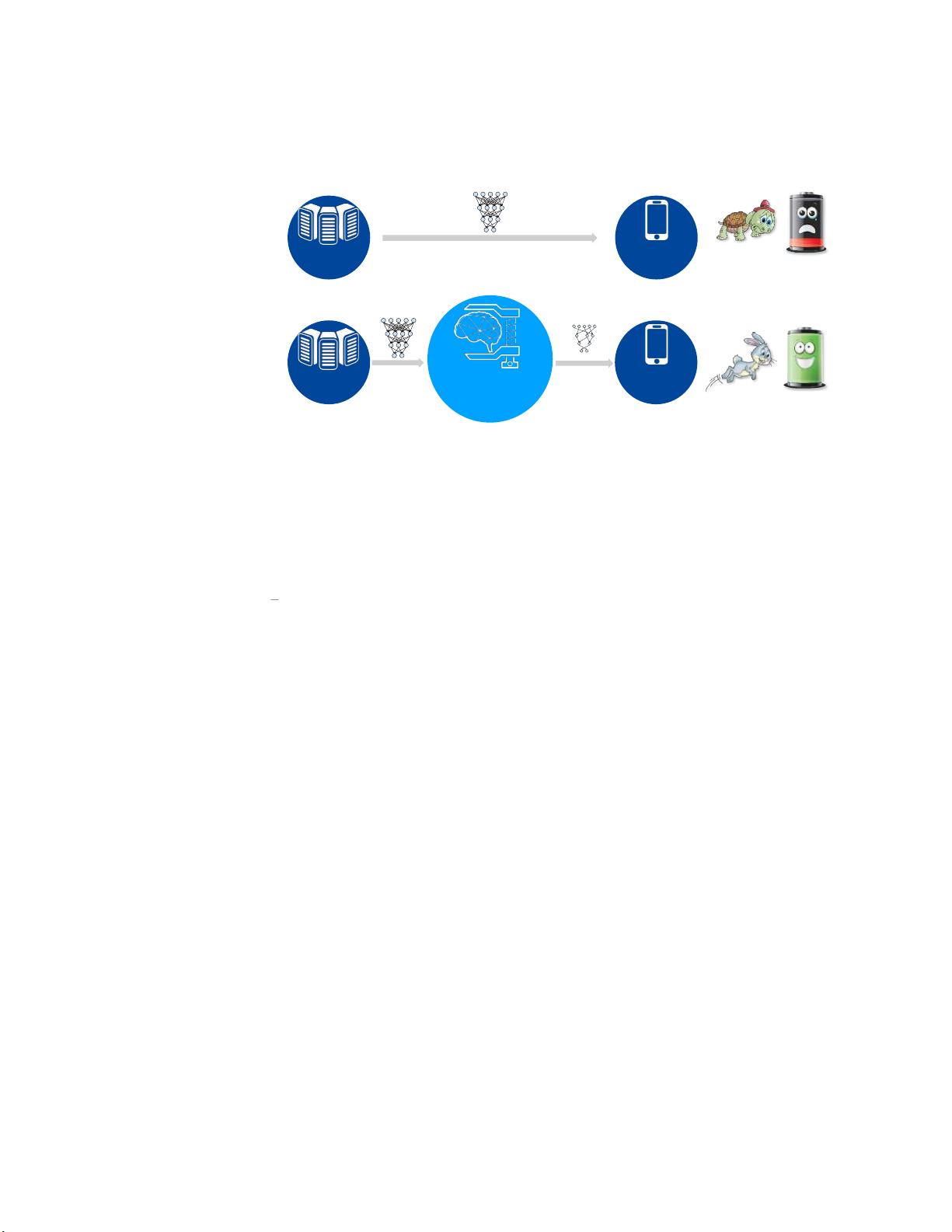
In this dissertation, we co-designed the algorithm and hardware for deep learning to make it run
faster and more energy-efficiently. We developed techniques to make the deep learning workload
more efficient and compact to begin with and then designed the hardware architecture specialized for
the optimized DNN workload. Figure 1.1 illustrates the design methodology of this thesis. Breaking
the boundary between the algorithm and the hardware stack creates a much larger design space with
many degrees of freedom that researchers have not explored before, enabling better optimization of
deep learning.
On the algorithm side, we investigated how to simplify and compress DNN models to make them
less computation and memory intensive. We aggressively compressed the DNNs by up to 49
×
without
losing prediction accuracy on ImageNet [25,26]. We also found that the model compression algorithm
removes the redundancy, prevents overfitting, and serve as a suitable regularization method [27].
From the hardware perspective, a compressed model has great potential to improve speed and
energy efficiency because it requires less computation and memory. However, the model compression
algorithm makes the computation pattern irregular and hard to parallelize. Thus we designed
customized hardware for the compressed model, tailoring the data layout and control flow to model
compression. This hardware accelerator achieved 3,400
×
better energy efficiency than GPU and an
order of magnitude better than previous accelerators [28]. The architecture has been prototyped on
FPGA and applied to accelerate speech recognition systems [29].
1.1 Motivation
"Less is more"
— Robert Browning, 1855


剩余124页未读,继续阅读

Kaige_Zhao
- 粉丝: 13
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


