使用Dubbo实现LoggerTrace:追踪、性能优化与集成方案
需积分: 10 109 浏览量
更新于2024-08-05
收藏 346KB PPTX 举报
"TraceLoggerSummarywithdubbo"
本文档《Trace Logger》主要探讨了在分布式系统中使用LoggerTrace进行跟踪和分析的方法,特别提到了与Dubbo的集成,以及如何利用Sleuth和Zipkin进行日志分析。作者Bond(China)详细介绍了LoggerTrace的5W,即What、Why、When&Where、Who,以及主要术语,旨在帮助运维人员和开发人员更好地理解并实施分布式追踪。
1. LoggerTrace的5W
- What?LoggerTrace是一种扩展的日志输出方式,通过添加如trace ID、span ID等特定信息,将跨多个服务的请求链路串联起来,便于问题排查、性能优化和请求流程可视化。其设计灵感源自Google的Dapper项目。
- Why?传统多节点部署的应用面临诸多挑战,如线上问题定位困难、性能瓶颈难以发现、日志功能单一以及系统扩展成本高昂。LoggerTrace能有效解决这些问题,提高问题定位效率,发现性能瓶颈,并支持更高效的服务扩展。
- When&Where?不是所有系统都需要引入LoggerTrace,通常适用于有大规模扩容需求、用户基数大、应对高并发场景以及模块间调用频繁的复杂系统。同时,当需要从日志中提取监控信息以进行系统优化时,LoggerTrace也能发挥重要作用。
- Who?LoggerTrace的实施需要全体团队成员的参与。在日志输出时应遵循原则,如详尽记录接口调用、明确标注日志Tag等。
2. LoggerTrace的主要术语
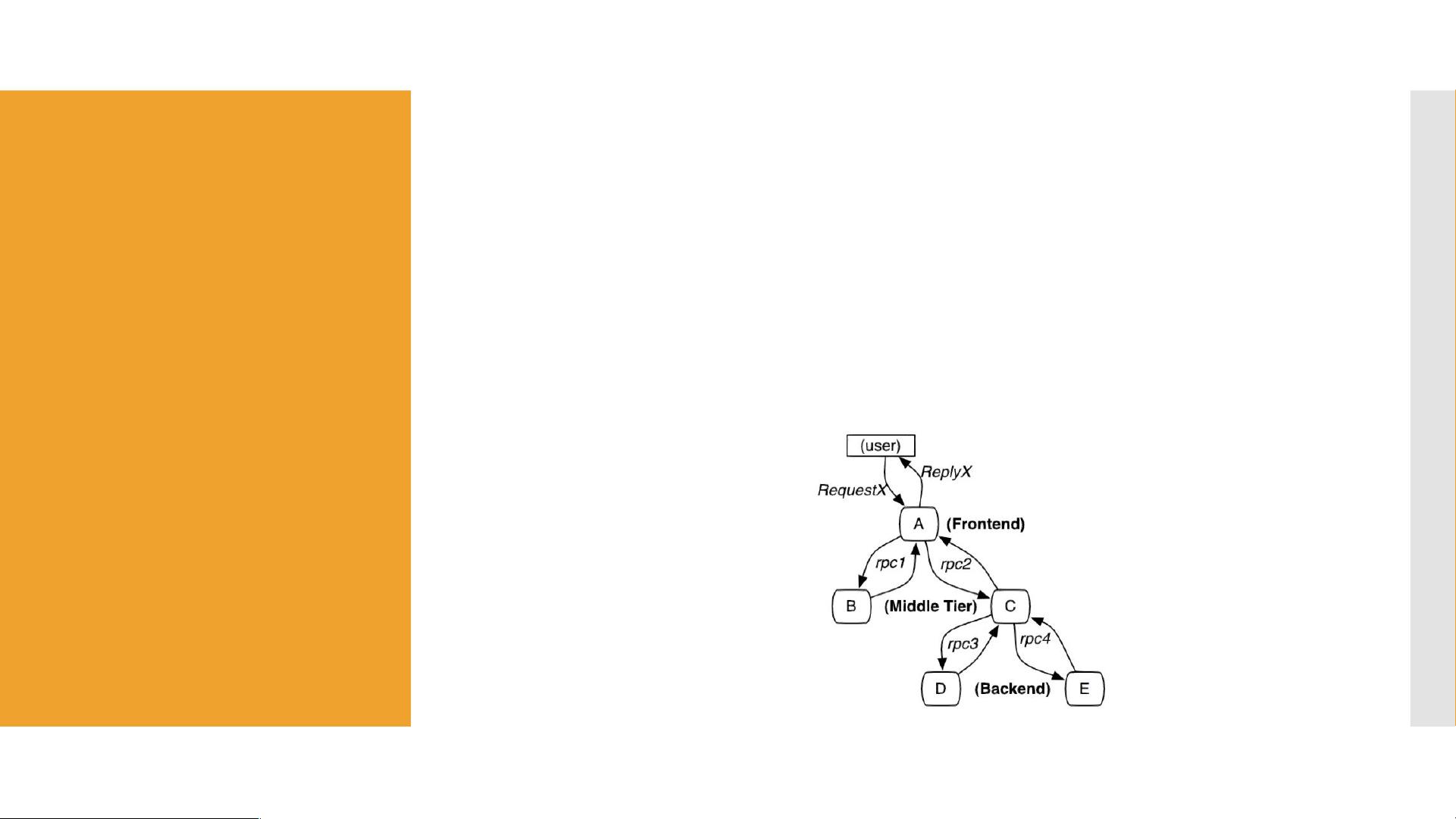
- 请求从发起至结束的完整过程被划分为多个阶段,每个阶段被称为一个span,而一系列span组成一个trace。每个span包含其开始和结束时间戳,以及可能的相关元数据,如操作名称、执行时间、异常信息等。
- Trace ID是全局唯一的标识符,用于跟踪整个请求链路。Span ID则标识了一个特定的span,每个span有一个父span ID(如果存在的话),表示其在trace中的位置。
- 在Dubbo中,可以通过拦截器或者AOP切面来注入和传播这些追踪信息,确保在整个服务调用过程中,trace和span信息能够正确传递。
3. 集成Sleuth和Zipkin
- Sleuth是Spring Cloud的一个组件,负责自动收集微服务间的调用链路信息,而Zipkin是一个可视化工具,用于展示这些追踪数据,帮助开发者找到延迟问题的源头。
- 结合ELK(Elasticsearch、Logstash、Kibana)或云日志分析服务,可以进一步分析和挖掘日志数据,提供更丰富的监控和诊断能力。
LoggerTrace是分布式系统中不可或缺的一部分,它能够帮助我们理解和优化复杂的系统行为,提升整体的运维效率。通过与Dubbo、Sleuth和Zipkin的集成,我们可以实现更高效的问题定位和性能优化,从而提高系统的稳定性和可维护性。
1. Logger Trace 的 5W
—— What ?
Logger Trace 是对日志输出的一个扩充,通过引入特定语义的内
容: trace, span 等额外的信息,将请求从源头到结束的所有过
程关联起来,以此方便应用运维人员、开发人员等对系统后期问
题追踪与分析、性能调优、优雅刻画请求全过程(轨迹追踪),
其设计理论来源于 Google 的 Dapper 白皮书,有兴趣的可以阅
读
Author: Bond(China)
剩余12页未读,继续阅读
2022-07-14 上传
2020-05-14 上传
2023-05-19 上传
2023-04-05 上传
2023-04-05 上传
2023-05-12 上传
2023-07-14 上传
2023-03-26 上传
2023-06-07 上传

周正德
- 粉丝: 2
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++ Qt影院票务系统源码发布,代码稳定,高分毕业设计首选
- 纯CSS3实现逼真火焰手提灯动画效果
- Java编程基础课后练习答案解析
- typescript-atomizer: Atom 插件实现 TypeScript 语言与工具支持
- 51单片机项目源码分享:课程设计与毕设实践
- Qt画图程序实战:多文档与单文档示例解析
- 全屏H5圆圈缩放矩阵动画背景特效实现
- C#实现的手机触摸板服务端应用
- 数据结构与算法学习资源压缩包介绍
- stream-notifier: 简化Node.js流错误与成功通知方案
- 网页表格选择导出Excel的jQuery实例教程
- Prj19购物车系统项目压缩包解析
- 数据结构与算法学习实践指南
- Qt5实现A*寻路算法:结合C++和GUI
- terser-brunch:现代JavaScript文件压缩工具
- 掌握Power BI导出明细数据的操作指南
