ChatGPT:语言预训练模型的技术原理解析
需积分: 0 71 浏览量
更新于2024-01-23
收藏 606KB DOCX 举报
ChatGPT是一个由知名人工智能研究机构OpenAI在2022年11月30日发布的大型语言预训练模型。它的核心能力在于理解人类的自然语言,并以贴近人类语言风格的方式进行回复。自发布以来,ChatGPT在人工智能领域引起了轰动,在5天内就吸引了100万用户,2个月内达到了1亿用户。而在其他非人工智能领域,一些机构也开始尝试使用ChatGPT进行智能生成,比如财通证券发布了一篇由ChatGPT生成的行业研报,表现出了一定的可读性和专业性。对于其他内容生产者来说,使用ChatGPT也能够提升个人的生产效率。
尽管ChatGPT展现出强大的能力,但对于不太熟悉人工智能领域的人来说,对这种黑盒技术还存在着担忧和不信任。因此,本文将全面剖析ChatGPT的技术原理,以期能够通过简单通俗的文字帮助读者了解ChatGPT,并解答以下问题:ChatGPT是什么?ChatGPT有哪些核心技术原理?如何保证ChatGPT的回复准确性和专业性?是如何进行语言的理解和生成?以及ChatGPT的一些应用和潜在风险。
首先,ChatGPT采用了一种称为自回归神经网络的结构,以处理自然语言。自回归神经网络是一种递归式神经网络,可以生成其输入的概率分布。ChatGPT使用了基于Transformer的神经网络结构,这种结构允许模型能够处理不同长度和顺序的输入输出序列,同时还可以并行处理不同部分的输入。这种结构的优势在于可以更好地捕捉长距离依赖关系,从而提高了模型对语言的理解和生成能力。
其次,ChatGPT还使用了大规模的语料库进行预训练,这样可以让模型学习到更多的语言知识和语言规律。通过大规模语料库的预训练,ChatGPT可以更好地理解和生成自然语言,并在回复中使用更加丰富和贴近人类语言风格的方式。
此外,为了保证ChatGPT的回复准确性和专业性,OpenAI还进行了大量的人工审核和模型微调。人工审核可以有效过滤掉模型可能生成的不合适或不准确的回复,而模型微调可以进一步提高模型的回复准确性和专业性。同时,OpenAI还利用了一种称为零样本学习的技术,在模型未曾见过的情况下,也可以进行有效的推理和回复。
在运用ChatGPT进行语言的理解和生成时,模型会先将文本输入进行编码,然后通过对编码的文本进行解码,再进行生成。这样的过程使得ChatGPT能够更好地理解输入的语言,并生成贴近人类语言风格的回复。同时,在生成回复时,ChatGPT还会利用一种称为抽样的技术,随机地从概率分布中抽取一个词,从而增加了回复的多样性和真实性。
在应用方面,ChatGPT可以用于多种智能生成的场景,比如自动化写作、智能对话系统、在线客服等。另一方面,也要注意到使用ChatGPT可能存在的风险,比如生成不准确或不合适的回复,以及滥用ChatGPT等问题。
总而言之,ChatGPT作为一个大型语言预训练模型,具有强大的语言理解和生成能力,其技术原理主要包括自回归神经网络结构、大规模语料库的预训练、人工审核和模型微调、零样本学习技术等。尽管ChatGPT的技术原理复杂,但通过本文的解析,希望读者能够更好地理解ChatGPT,并对其应用和潜在风险有所把握。(ChatGPT的技术原理.docx)
大家从 BERT 和 GPT 的对比中可以看到,BERT 在语言理解上似乎更具优势,那为何
现在 ChatGPT 的模型基座是 GPT 呢?这就涉及到最近两年逐渐清晰的 NLP 任务大一
统趋势了。
三、NLP 任务大一统
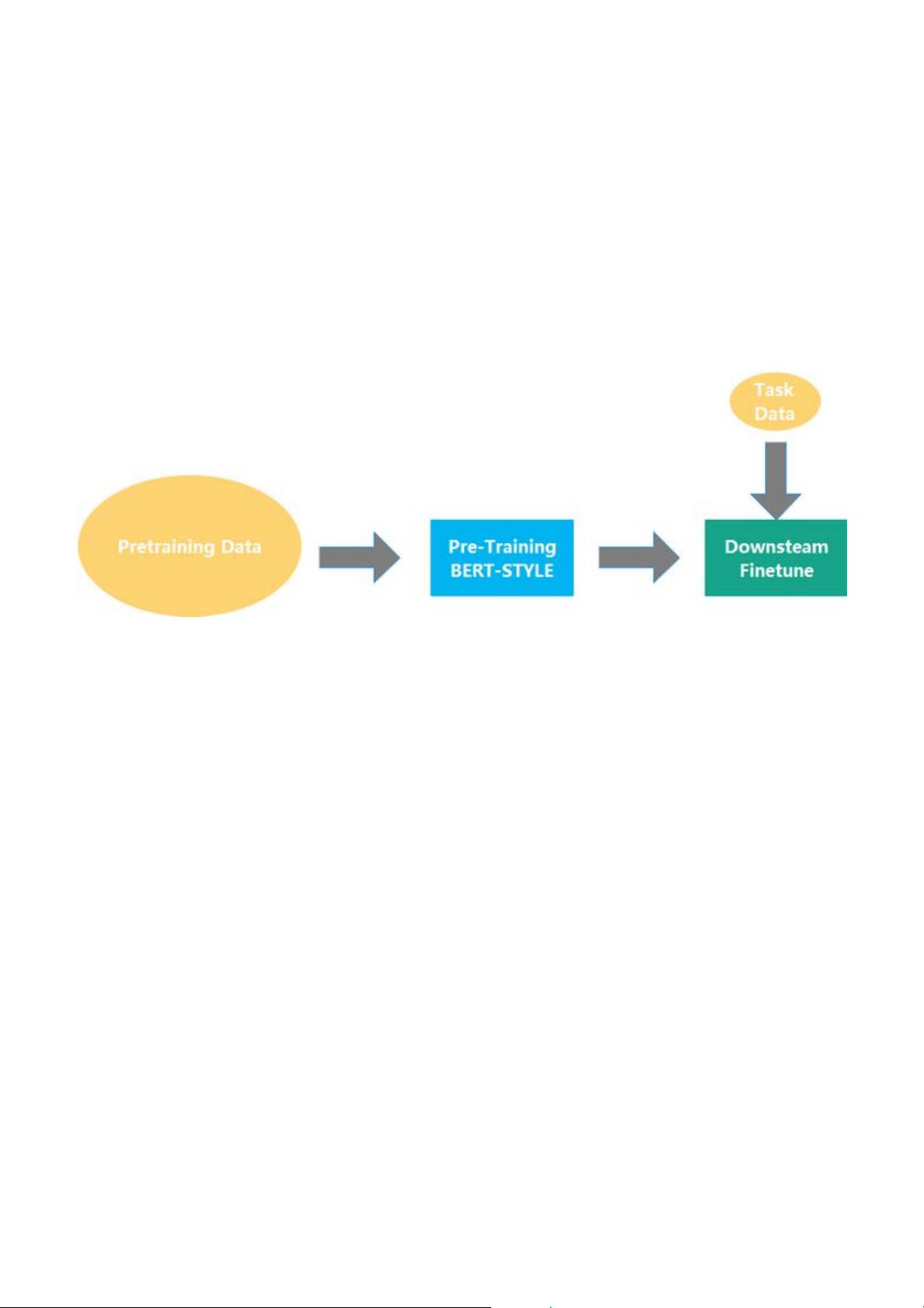
基于 MLM 训练范式得到的 BERT 模型虽然在很多语言理解类任务上有不错的效果下游
任务,之后整个业界在处理 NLP 任务的时候通常会遵循预训练模型→下游任务 finetune
的流程:
这种方式与传统的 training from scratch 相比,对下游任务数据的需求量更少,得到的效
果也更优。不过,上述方式还是存在一些问题:
1. 处理一个新的任务就需要标注新的语料,对语料的需求比较大,之前已经做过的任务
语料无法高效利用。即使是信息抽取下面的不同任务(如实体识别和关系抽取两个任务)
也无法通用化。
2. 处理一个新的任务需要针对任务特性设计整体模型方案,虽然 BERT 模型的底座已经
确定,但还是需要一定的设计工作量。例如文本分类的任务和信息抽取的任务的模型方
案就完全不同。
对于要走向通用人工智能方向的人类来说,这种范式很难达到通用,对每个不同任务都
用单独的模型方案和数据来训练显然也是低效的。因此,为了让一个模型能够尽量涵盖
更多的任务,业界尝试了几种不同的路径来实现这个目标。
· 对 BERT 中的 MLM 进行改造,如引入一些特殊的 Mask 机制,使其能够同时支持多种
不同任务,典型的模型如 UniLM https://arxiv.org/abs/1905.03197
剩余22页未读,继续阅读
2023-04-20 上传
2023-07-23 上传
2023-04-20 上传
2023-04-23 上传
2023-04-21 上传

阿星先森
- 粉丝: 203
- 资源: 1451
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
