
rest of the graph from disk.
In the early phase of our project, we explored this op-
tion, but found it difficult to find a good cache policy to
sufficiently reduce disk access. Ultimately, we rejected this
approach for two reasons. First, the performance would
be highly unpredictable, as it would depend on structural
properties of the input graph. Second, optimizing graphs
for locality is costly, and sometimes impossible, if a graph
is supplied without metadata required to efficiently cluster
it. General graph partitioners are not currently an option,
since even the state-of-the-art graph partitioner, METIS
[
27
], requires hundreds of gigabytes of memory to work
with graphs of billions of edges.
Graph compression. Compact representation of real-
world graphs is a well-studied problem, the best algorithms
can store web-graphs in only 4 bits/edge (see [
9
,
13
,
18
,
25
]). Unfortunately, while the graph structure can often
be compressed and stored in memory, we also associate
data with each of the edges and vertices, which can take
significantly more space than the graph itself.
Bulk-Synchronous Processing. For a synchronous sys-
tem, the random access problem can be solved by writing
updated edges into a scratch file, which is then sorted (us-
ing disk-sort), and used to generate input graph for next
iteration. For algorithms that modify only the vertices, not
edges, such as Pagerank, a similar solution has been used
[
15
]. However, it cannot be efficiently used to perform
asynchronous computation.
3 Parallel Sliding Windows
This section describes the Parallel Sliding Windows (PSW)
method (Algorithm 2). PSW can process a graph with
mutable edge values efficiently from disk, with only a small
number of non-sequential disk accesses, while supporting
the asynchronous model of computation. PSW processes
graphs in three stages: it 1) loads a subgraph from disk; 2)
updates the vertices and edges; and 3) writes the updated
values to disk. These stages are explained in detail below,
with a concrete example. We then present an extension to
graphs that evolve over time, and analyze the I/O costs of
the PSW method.
3.1 Loading the Graph
Under the PSW method, the vertices
V
of graph
G =
(V, E)
are split into
P
disjoint
intervals
. For each interval,
we associate a shard, which stores all the edges that have
destination in the interval. Edges are stored in the order of
their source (Figure 1). Intervals are chosen to balance the
number of edges in each shard; the number of intervals,
P
,
is chosen so that any one shard can be loaded completely
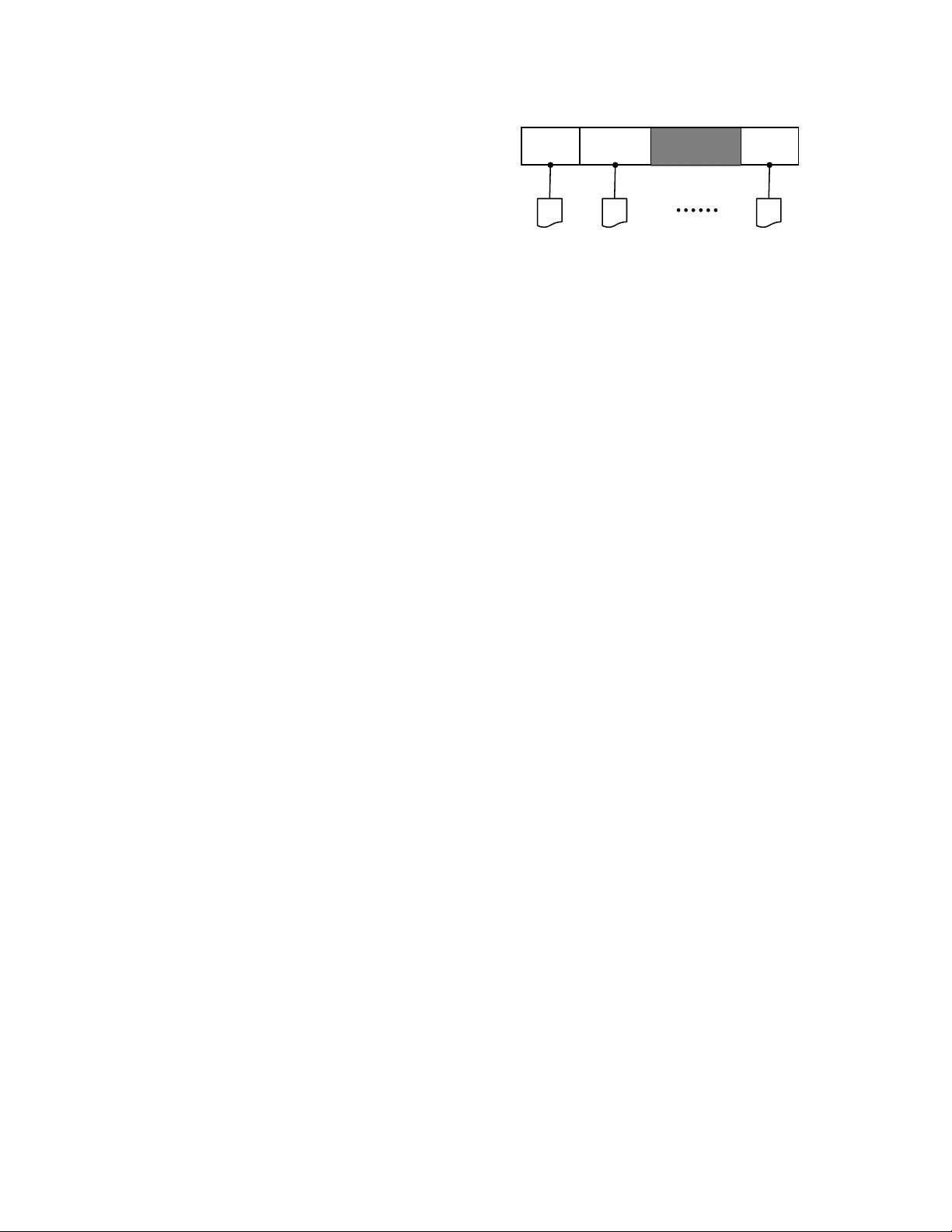
shard(1)
interval(1) interval(2) interval(P)
shard(2)
shard(P)
1 |V| v
1
v
2
Figure 1: The vertices of graph
(V, E)
are divided into
P
intervals. Each interval is associated with a shard, which
stores all edges that have destination vertex in that interval.
into memory. Similar data layout for sparse graphs was
used previously, for example, to implement I/O efficient
Pagerank and SpMV [5, 22].
PSW does graph computation in
execution intervals
,
by processing vertices one interval at a time. To create the
subgraph for the vertices in interval
p
, their edges (with
their associated values) must be loaded from disk. First,
Shard(p)
, which contains the in-edges for the vertices
in interval(p), is loaded fully into memory. We call thus
shard(p) the
memory-shard
. Second, because the edges
are ordered by their source, the out-edges for the vertices
are stored in consecutive chunks in the other shards, requir-
ing additional
P − 1
block reads. Importantly, edges for
interval(p+1) are stored immediately after the edges for
interval(p). Intuitively, when PSW moves from an interval
to the next, it slides a
window
over each of the shards. We
call the other shards the
sliding shards
. Note, that if the
degree distribution of a graph is not uniform, the window
length is variable. In total, PSW requires only
P
sequential
disk reads to process each interval. A high-level illustration
of the process is given in Figure 2, and the pseudo-code of
the subgraph loading is provided in Algorithm 3.
3.2 Parallel Updates
After the subgraph for interval
p
has been fully loaded from
disk, PSW executes the user-defined
update-function
for
each vertex in parallel. As update-functions can modify the
edge values, to prevent adjacent vertices from accessing
edges concurrently (race conditions), we enforce external
determinism, which guarantees that each execution of PSW
produces exactly the same result. This guarantee is straight-
forward to implement: vertices that have edges with both
end-points in the same interval are flagged as critical, and
are updated in sequential order. Non-critical vertices do
not share edges with other vertices in the interval, and
can be updated safely in parallel. Note, that the update of
a critical vertex will observe changes in edges done by
4
剩余16页未读,继续阅读

「已注销」
- 粉丝: 139
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- AirKiss技术详解:无线传递信息与智能家居连接
- Hibernate主键生成策略详解
- 操作系统实验:位示图法管理磁盘空闲空间
- JSON详解:数据交换的主流格式
- Win7安装Ubuntu双系统详细指南
- FPGA内部结构与工作原理探索
- 信用评分模型解析:WOE、IV与ROC
- 使用LVS+Keepalived构建高可用负载均衡集群
- 微信小程序驱动餐饮与服装业创新转型:便捷管理与低成本优势
- 机器学习入门指南:从基础到进阶
- 解决Win7 IIS配置错误500.22与0x80070032
- SQL-DFS:优化HDFS小文件存储的解决方案
- Hadoop、Hbase、Spark环境部署与主机配置详解
- Kisso:加密会话Cookie实现的单点登录SSO
- OpenCV读取与拼接多幅图像教程
- QT实战:轻松生成与解析JSON数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


