阿里DFSMN模型:刷新全球语音识别准确率纪录,开源在GitHub
需积分: 0 145 浏览量
更新于2024-08-05
收藏 986KB PDF 举报
"阿里开源了新一代语音识别模型DFSMN,该模型在LibriSpeech数据库上达到96.04%的识别准确率,对比LSTM模型,DFSMN训练速度更快,识别准确率更高,且已在智能音响和自动售票机等场景中得到应用。著名语音识别专家谢磊教授认为,DFSMN是深度学习在语音识别领域的突破性成果。"
在深度学习领域,语音识别技术已经取得了显著的进步,其中,阿里巴巴达摩院机器智能实验室的DFSMN模型成为了一个重要的里程碑。这个模型不仅在语音识别准确率上实现了显著提升,而且在训练速度和实际应用中都表现出优越的性能。相比当前业界广泛使用的长短期记忆网络(LSTM),DFSMN模型的训练速度提高了3倍,语音识别速度提升了2倍,这无疑为智能设备的实时交互带来了更高效、更准确的体验。
DFSMN模型的优异表现在于其设计,它优化了对语音序列的学习,特别是在处理长时间依赖问题时,相比LSTM能更有效地捕捉上下文信息。这种改进对于在嘈杂环境下的语音识别至关重要,因为它能够更好地理解并过滤掉背景噪声,提高识别的准确性。
在实际应用中,DFSMN模型已经在云栖大会武汉峰会上展示过其能力,AI收银员在繁忙环境中成功识别了用户的语音订单,而在上海地铁的自动售票机上,这种技术也在提供服务。这些实例证明了DFSMN模型在真实世界复杂环境中的实用性。
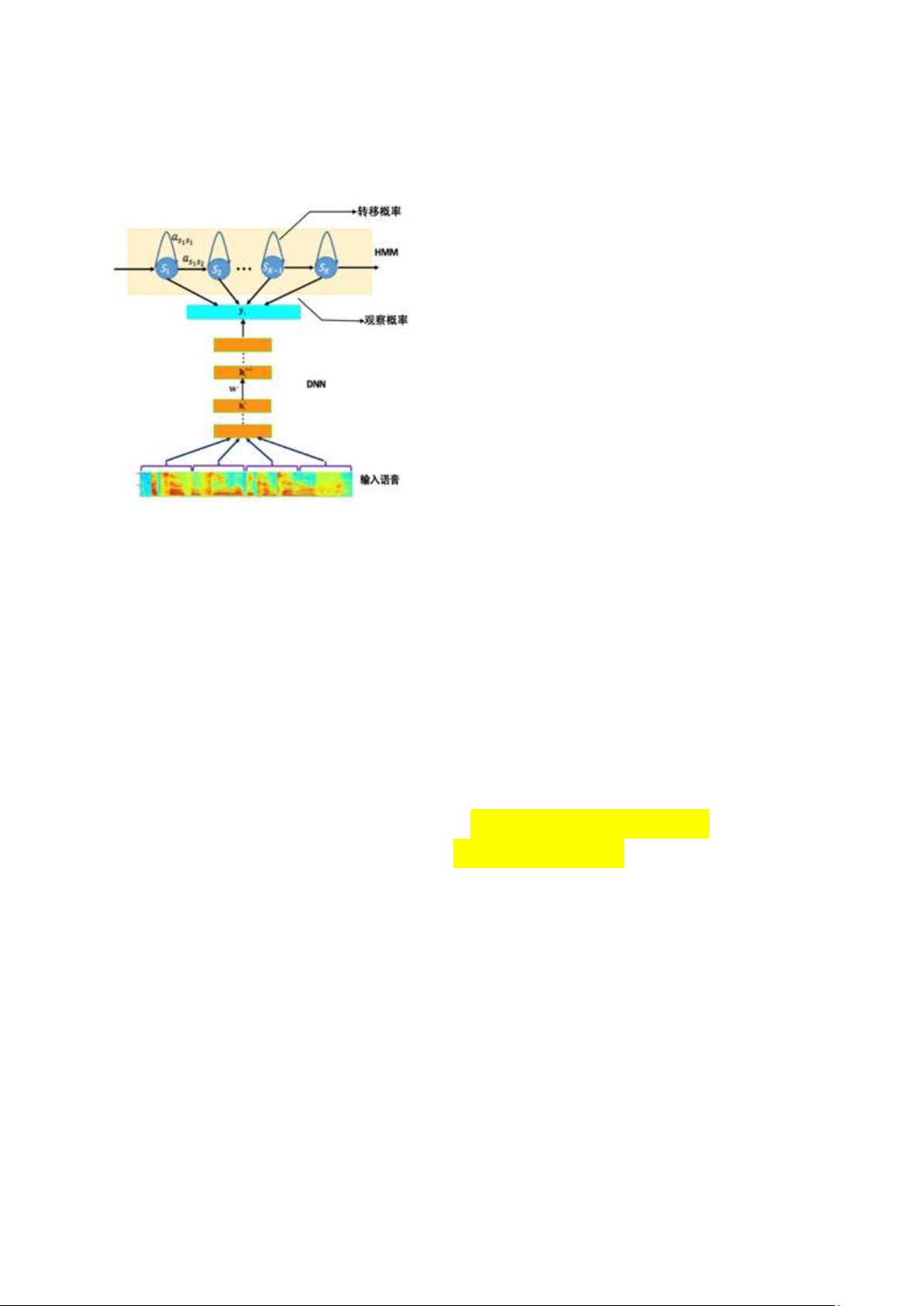
语音识别技术的基础是声学模型,通常基于深度神经网络和隐马尔可夫模型(DNN-HMM)。DFSMN模型也是在这个框架下工作,但它通过创新的网络结构提升了声学特征到输出建模单元的映射效率,从而提高了识别性能。模型的输入是经过预处理的语音特征,输出是对应的声音单位,通过HMM进行解码得到最终的识别结果。
谢磊教授的评价强调了DFSMN模型在学术界和工业界的影响,指出它是深度学习在语音识别领域的重要贡献。通过开源这一模型,阿里巴巴为全球研究者和开发者提供了探索和利用先进语音识别技术的平台,促进了人工智能领域的技术创新和应用发展。
DFSMN模型的开源标志着语音识别技术的一个新高度,它将推动相关产品和服务的智能化水平,为未来的语音交互带来更自然、更高效的体验。对于开发者来说,这是一个难得的机会,可以直接利用这一先进模型来提升自己的项目性能,同时也为深入研究和改进语音识别技术提供了宝贵的基础。
Short Term Memory,LSTM)的循环神经网络(Recurrent Neural Networks,
RNN)。LSTM-RNN通过隐层的循环反馈连接,可以将历史信息存储在隐层的节点中,从而
可以有效地利用语音信号的长时相关性。
图 1. 基于DNN-HMM的语音识别系统框图
进一步地通过使用双向循环神经网络(BidirectionalRNN),可以有效地利用语音信号历史
以及未来的信息,更有利于语音的声学建模。基于循环神经网络的语音声学模型相比于前馈全
连接神经网络可以获得显著的性能提升。但是循环神经网络相比于前馈全连接神经网络模型更
加复杂,往往包含更多的参数,这会导致模型的训练以及测试都需要更多的计算资源。
另外基于双向循环神经网络的语音声学模型,会面临很大的时延问题,对于实时的语音识别任
务不适用。现有的一些改进的模型,例如,基于时延可控的双向长短时记忆单元(Latency
Controlled LSTM,LCBLSTM )[1-2],以及前馈序列记忆神经网络(Feedforward
SequentialMemory Networks,FSMN)[3-5]。去年我们在工业界第一个上线了基于
LCBLSTM的语音识别声学模型。配合阿里的大规模计算平台和大数据,采用多机多卡、16bit
量化等训练和优化方法进行声学模型建模,取得了相比于FNN模型约17-24%的相对识别错误
率下降。
FSMN
模型的前世今生
1. FSMN
模型
剩余10页未读,继续阅读
2022-01-26 上传
2023-06-08 上传
2023-02-06 上传
2023-04-01 上传
2023-06-09 上传
2024-10-05 上传
2023-05-19 上传

王者丶君临天下
- 粉丝: 20
- 资源: 265
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
