
P2/Vol.6/s&n6 Programming WinSock #30594-1 rob 11.14.94 CH01 LP #4
Chapter 1 ■ Networking and Network Programming
17
Note
The first design of a network passing a token ring is attributed to E. E. Newhall
in 1969. IBM first publicly supported a token-ring topology in March 1982,
and announced its first token-ring network product in 1984.
Data on the IBM token-ring network is transmitted at either 4 or 16 Mbps, depending
on the actual implementation. For computers to communicate with each other, all net-
work cards must be configured similarly to communicate at either 4 or 16 Mbps on the
network. Networked computers are connected by shielded and/or unshielded twisted-
pair cable to a wiring concentrator called a Media Access Unit or MAU (rhymes with
cow). Each MAU can support as many as 72 computers that use unshielded wire or up
to 260 computers using shielded wire. Each ring can have as many as 33 MAUs allow-
ing for a theoretical maximum of 8,580 computers on the network.
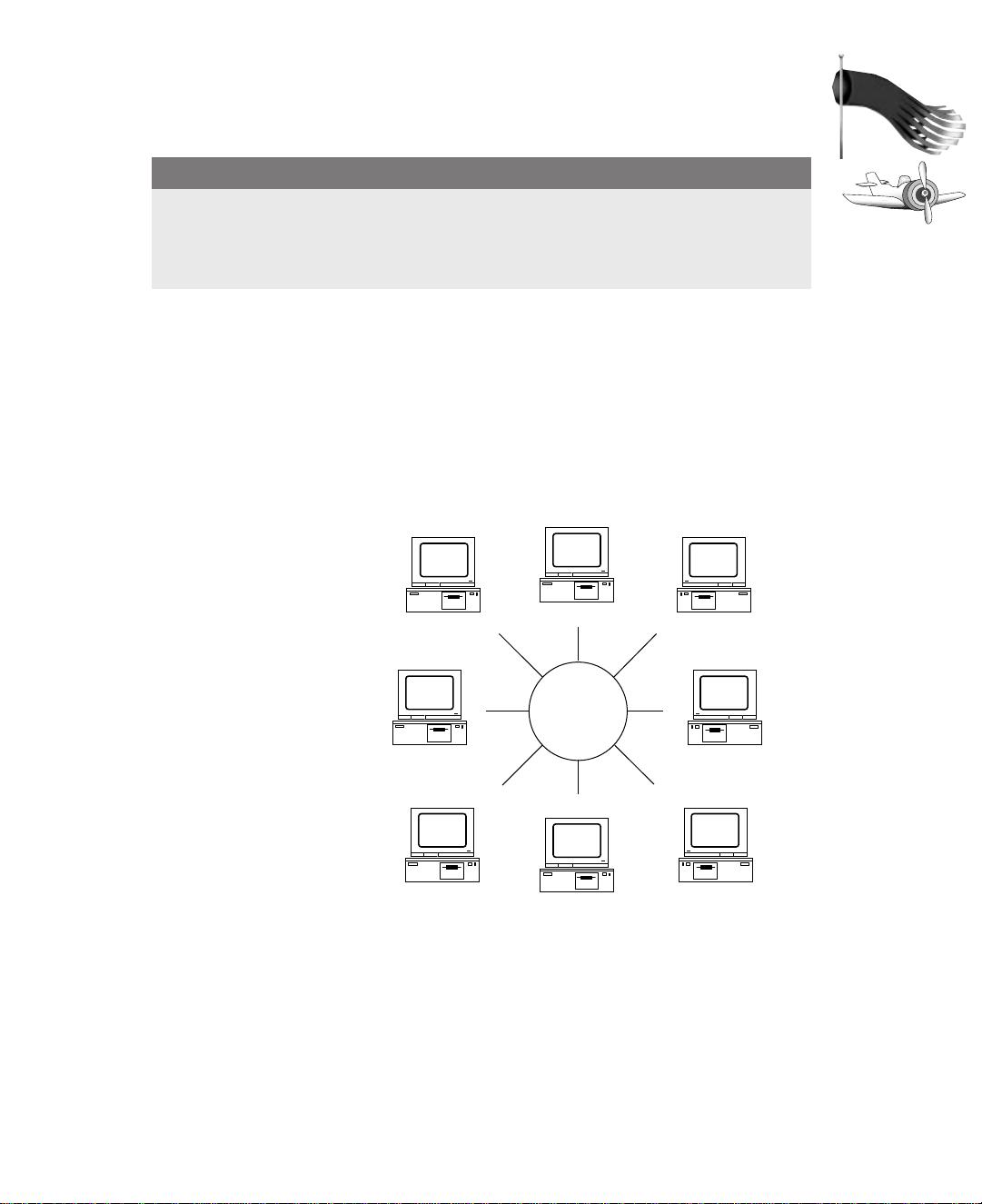
FIGURE 1.7.
Ring network.
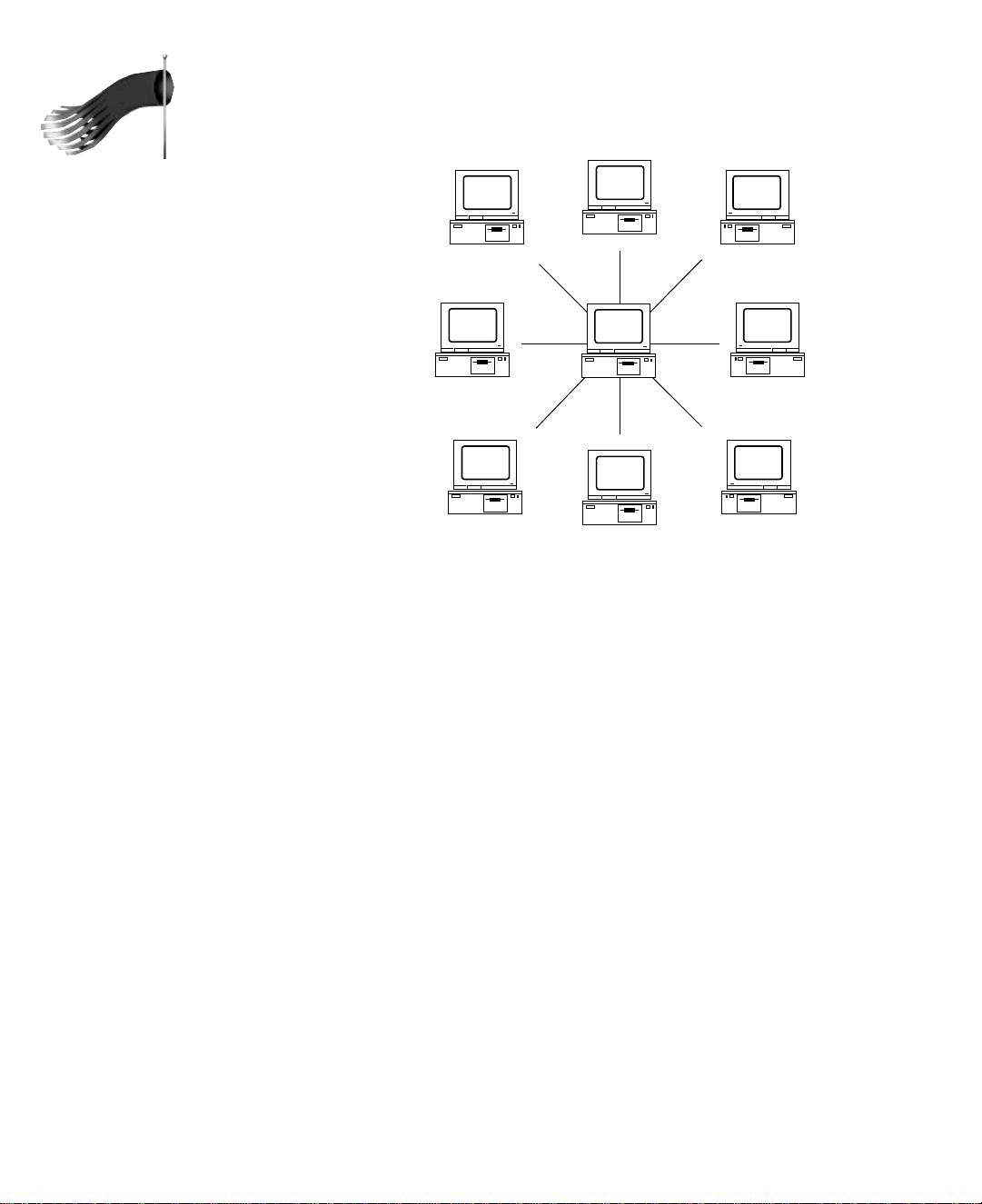
Star Network
To transmit data between any two computers in a star network, shown in Figure 1.8,
requires that data be sent via the centrally located computer, called a hub. The hub
provides a common connection so that all the computers can communicate with one
another. To extend the star network, hubs can be connected to one another. The major
problem with star networks is that if the centrally located hub isn’t operating, the entire
network becomes unusable. A benefit of a star network is that no computer, other than
the centrally located hub, can interrupt network traffic.

剩余327页未读,继续阅读

k300021
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- AirKiss技术详解:无线传递信息与智能家居连接
- Hibernate主键生成策略详解
- 操作系统实验:位示图法管理磁盘空闲空间
- JSON详解:数据交换的主流格式
- Win7安装Ubuntu双系统详细指南
- FPGA内部结构与工作原理探索
- 信用评分模型解析:WOE、IV与ROC
- 使用LVS+Keepalived构建高可用负载均衡集群
- 微信小程序驱动餐饮与服装业创新转型:便捷管理与低成本优势
- 机器学习入门指南:从基础到进阶
- 解决Win7 IIS配置错误500.22与0x80070032
- SQL-DFS:优化HDFS小文件存储的解决方案
- Hadoop、Hbase、Spark环境部署与主机配置详解
- Kisso:加密会话Cookie实现的单点登录SSO
- OpenCV读取与拼接多幅图像教程
- QT实战:轻松生成与解析JSON数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


