标题:“storm与spark简介”提供了一篇针对初学者的指南,介绍了两个重要的实时大数据处理框架:Apache Storm和Apache Spark。本文将分别对这两个框架进行概述,以及它们的核心组件和工作原理。
1. Storm框架:
Storm是一个开源的分布式实时数据流处理系统,它专注于实时处理不断流入的数据,与Hadoop的批处理有所不同。主要组件包括:
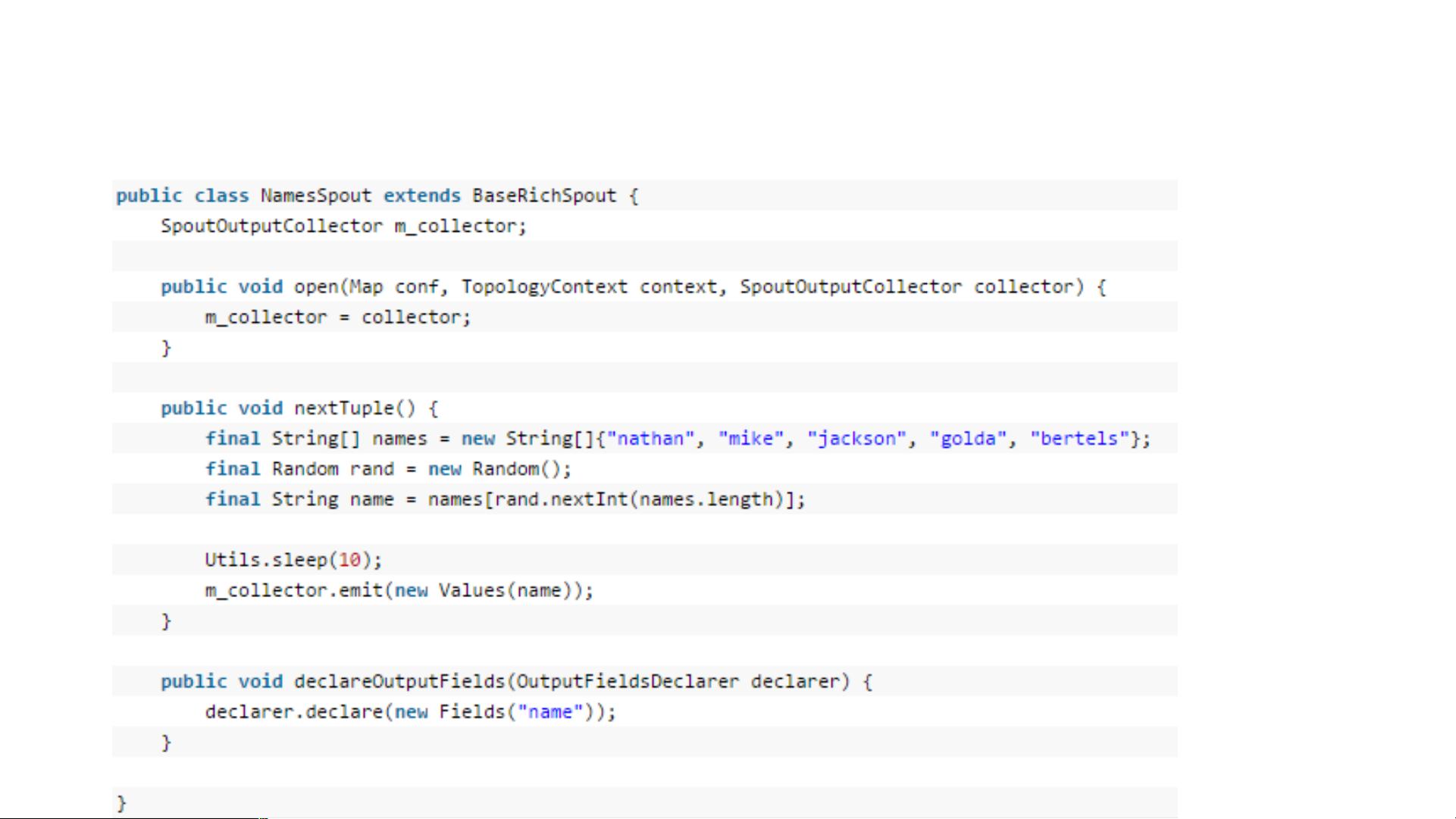
- **Spout(源头)**:Spout负责数据的输入,通常从外部数据源(如Kafka、RabbitMQ等)读取数据并产生Tuples(Storm的基本数据单元)。
- **Bolt(处理节点)**:Bolt是数据流的主要处理环节,执行过滤、业务逻辑处理、复杂运算、数据库操作等任务。Bolt允许简单的数据转换和处理。
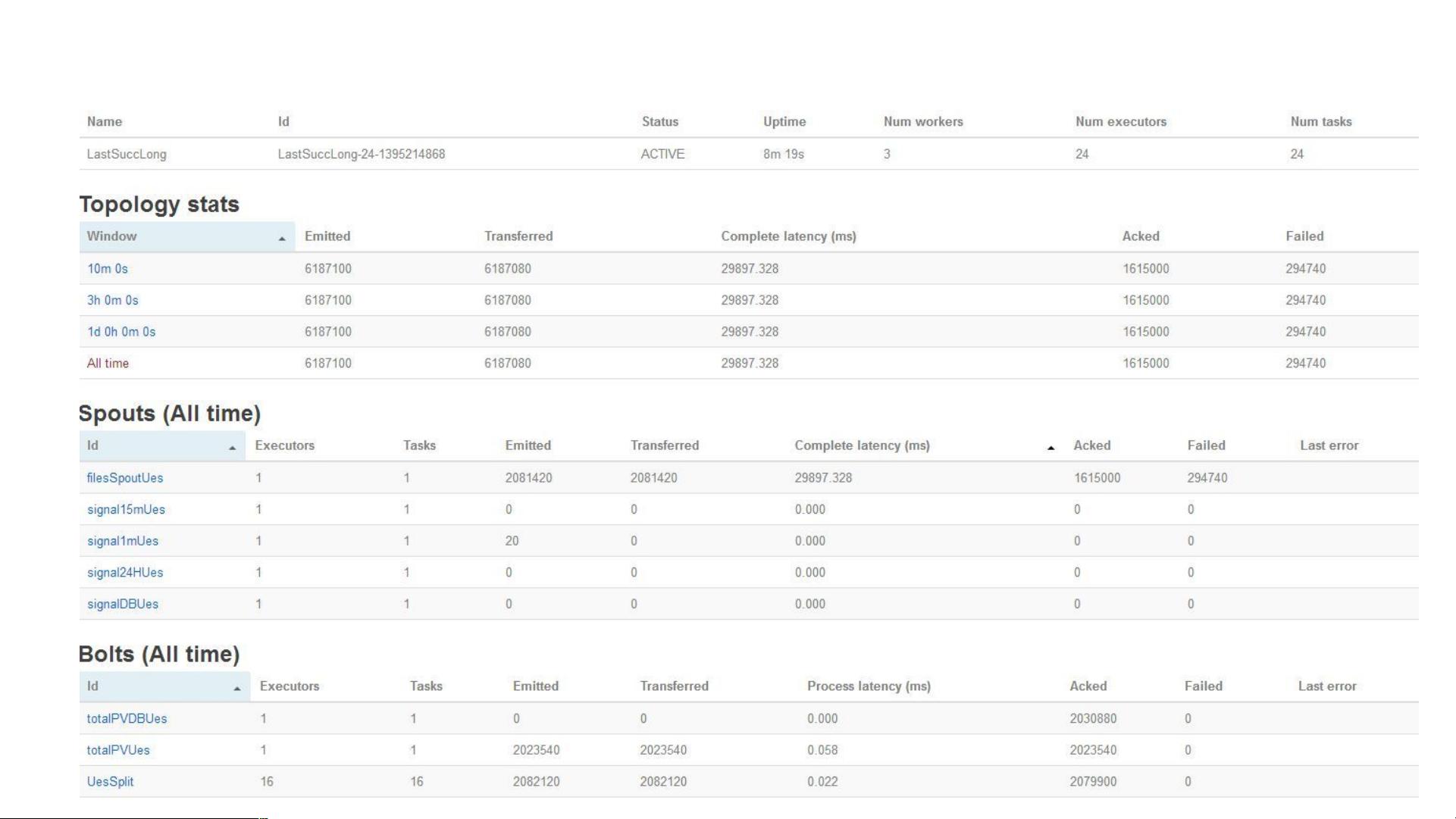
启动Storm集群时,需要设置关键步骤如下:
- 启动Zookeeper集群,确保奇数个节点,配置数据目录和IP/端口。
- 在每个节点上创建myid文件,标识节点身份。
- 配置storm.yaml,指定Zookeeper地址、Supervisor端口分配、以及Nimbus和Supervisor的临时数据位置。
- 确保防火墙设置正确,避免Zookeeper通信失败。
- 启动Nimbus(控制中心)、UI(用户界面)和Supervisor(资源管理器)。
重新平衡Storm Topology(处理流程)可以通过Storm Web UI或命令行工具进行。
2. Spark框架:
Spark则以Resilient Distributed Dataset (RDD)为核心概念,它是Spark处理数据的基础。RDD是弹性分布式内存抽象,允许以本地集合操作的方式处理分布式数据,提供了高度容错性和可扩展性。Spark的运行架构涉及以下关键组件:
- **Driver(驱动程序)**:接收用户的命令,调度任务到Worker节点。
- **Executor(执行器)**:在Worker节点上运行计算任务,维护多个线程执行任务。
- **Resilient Distributed Dataset(RDD)**:存储和操作数据的基本单位,支持多种算子(map、reduce、filter等)实现分布式计算。
Spark的典型应用包括但不限于批处理、交互式查询和流处理。运行Spark应用程序时,需要配置资源管理和调度策略,并通过Spark Shell、PySpark或Spark-submit等工具提交作业。
总结来说,Storm和Spark都是大数据处理的重要工具,但它们的重点不同:Storm强调实时处理,适合处理持续不断的数据流;而Spark的强项在于其强大的数据处理能力和广泛的应用场景,包括批处理、交互式查询和流处理。两者各有优势,根据实际需求选择合适的框架进行数据处理是关键。


 我的内容管理
展开
我的内容管理
展开









