观测数据因果推断在启动重置体验分析中的应用
版权申诉
"本次资料主要探讨了在数据科学领域中,如何利用观测数据进行因果推断,特别是针对启动重置类问题的分析。由腾讯高级数据研发工程师郭棋林在2021年DataFunSummit在线峰会上分享的内容,涵盖了观测数据因果推断的基本知识、准实验方法的应用案例以及启动重置类问题的通用分析方法。"
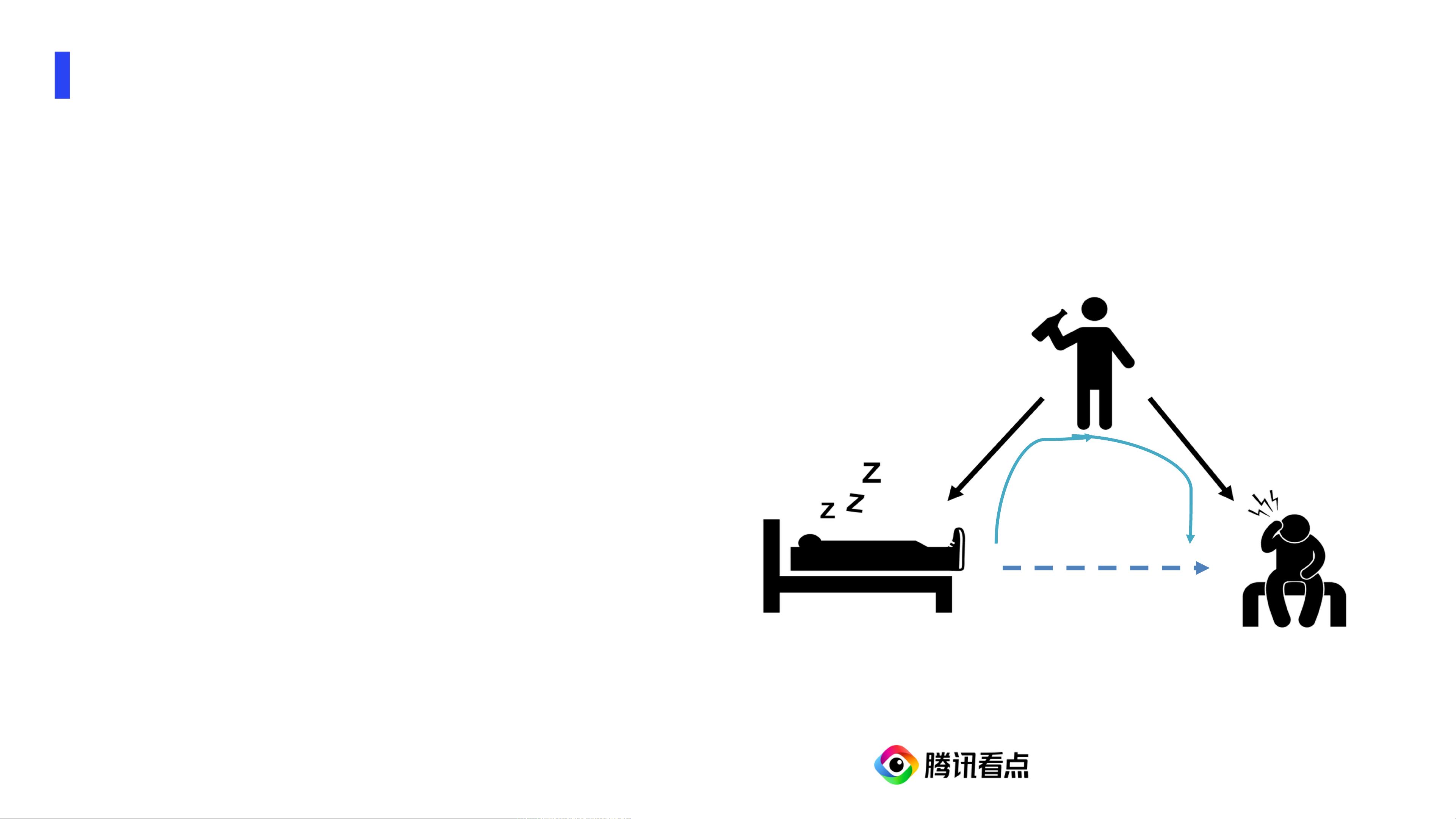
在数据科学中,因果推断是理解和解释变量之间关系的关键。观测数据因果推断旨在通过非实验性的数据来揭示变量之间的因果关系,这与相关性分析不同,因为相关性并不总是意味着因果性。郭棋林强调了混淆因子(Counfounding)的概念,即两个看似相关的现象可能由于共同的原因(如例子中的“穿鞋睡觉”和“第二天起床头疼”,共同原因是“昨晚喝酒”)而产生关联,而不是直接的因果联系。
混淆因子的处理是因果推断的重要环节,它可能导致样本选择偏差(Sample selection)。例如,"才华和相貌成反比"的假设可能因为是否在娱乐圈这个对撞因子(Collider)而产生误导,因为娱乐圈的人才貌兼备的情况更多,导致我们错误地认为两者成反比。
在因果推断中,干预(Intervention)的结果是关键。理想情况下,随机对照试验(Randomized Control Trial, RCT)能提供最直接的因果效应估计。然而,在实际中,RCT可能受到多种限制,如伦理、成本或可行性问题。因此,数据科学家常依赖于观测数据来模拟实验效果。
观测数据和实验数据的比较显示,实验数据如A/B测试能更直接地衡量因果效应,因为它可以控制混淆因子。但在某些情况下,如启动重置类问题,可能需要使用准实验方法,如工具变量法(Instrumental Variables)、回归断点设计(Regression Discontinuity Design)等来估算因果效应。
启动重置类问题通常涉及到产品或服务的重启、更新或用户重新激活等场景,分析此类问题时,需要考虑用户行为的连续性和变化性。郭棋林可能介绍了如何通过特定的分析模型和统计方法,如倾向得分匹配(Propensity Score Matching)或差异-in-differences(DiD)来识别并量化这些干预的效果。
这份资料深入浅出地阐述了在无法进行RCT的情况下,如何通过观测数据进行因果推断,并提供了启动重置类问题的分析策略。这对于产品优化、用户体验改进和业务决策具有重要的实践指导意义。
Counfounding
DataFunSummit|
“穿鞋睡觉”和“第⼆天起床头疼”相关性很⾼
共同原因(混淆因⼦):昨晚喝酒
Causalassociation
Counfounding association
剩余33页未读,继续阅读
2021-09-09 上传
2022-03-18 上传
点击了解资源详情
2023-05-10 上传
2023-05-25 上传
2023-11-28 上传
2023-06-06 上传
2023-05-19 上传
2023-06-06 上传

普通网友
- 粉丝: 12w+
- 资源: 9195
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
