王立威教授解析机器学习理论:从泛化到深度学习算法
需积分: 10 8 浏览量
更新于2024-07-19
收藏 1.51MB PDF 举报
"王立威教授在2017年的山西大学大数据夏令营中分享了关于机器学习理论的深入见解。报告以"Learning Theory: Retrospect and Prospect"为主题,涵盖了机器学习的核心概念,包括问题的正式化、学习的可解性、数据需求、理论基础方法(如VC理论和正则化)以及算法稳定性。讲座特别关注了模型的泛化能力,强调模型在未知数据上的表现而非仅限于训练数据。
首先,讲座引导听众理解机器学习的基本理论,如何将问题形式化,可以采用统计、在线或分布式等多种框架。核心议题是判断一个问题是否“可学习”,即能否通过有限的数据达到一定的预测精度。学习理论探讨了数据量对学习质量的影响,以及如何基于理论构建稳健的学习算法。
讲座中举了一个具体的例子,如Hook's Law,用来直观地阐述模型泛化的重要性。通过这个例子,王立威教授可能解释了如何利用历史数据(比如物理学家Hook的观察)来建立一个模型,然后验证该模型能否适用于新的、未见过的情况,即未知的力与伸长关系。
接下来,讲座深入剖析了VC理论,这是衡量函数类复杂度的重要工具,它在理解和控制过拟合现象中起着关键作用。正则化方法被介绍为一种防止过拟合的策略,通过对模型复杂度的约束,提升模型在新数据上的泛化性能。
此外,算法稳定性作为另一个核心概念,探讨了算法对于输入微小变化的敏感程度,这对于理解深度学习算法的鲁棒性和改进设计至关重要。王立威教授可能会讨论不同类型的深度学习算法(如神经网络),以及它们在理论框架下的优缺点和未来发展趋势。
报告的最后部分,王立威教授对深度学习算法进行了深入讨论,可能涉及了当时最新的研究成果,如深度学习在大规模数据和计算能力增强下的优势,以及面临的挑战,如梯度消失和爆炸等问题。
王立威教授的报告为参会者提供了一个全面而深入的视角,帮助他们理解机器学习理论的基石,以及如何将其应用于实践,尤其是在深度学习领域的前沿进展。通过这些讲解,听众不仅可以掌握基本的理论工具,还能了解到如何在实际项目中应用这些理论以实现更好的模型泛化和性能优化。"
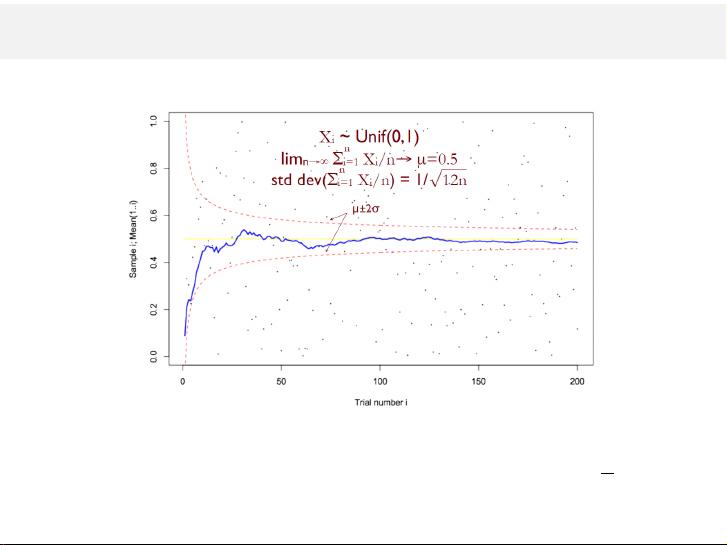
Law of large numbers
Suppose X
1
, X
2
, ··· are i.i.d. random variables
µ = E[X
i
] < ∞, σ
2
= Var[X
i
] < ∞
Let
¯
X
n
=
1
n
n
i=1
X
i
The weak law of large numbers (i.i.d. case)
For any ϵ > 0, as n → ∞
Pr
|
¯
X
n
− µ| > ϵ
−→ 0
11

剩余68页未读,继续阅读
2021-01-06 上传
2019-03-24 上传
2021-08-03 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

duhangyuan
- 粉丝: 2
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
