"FlinkRunTime核心架构.pdf"
Apache Flink是一个流行的开源流处理框架,它在实时数据处理领域扮演着重要角色。Flink的核心运行时(Runtime)是其高效、可扩展性和容错性的基石。在Flink的Runtime中,有以下几个关键组件和概念:
1. **DataStream API和DataSet API**:
- DataStream API专门用于处理无界和有界的数据流,支持实时流处理。
- DataSet API则主要针对批处理任务,它将数据集分割成离散的块(或批),并进行迭代计算。
2. **分布式流数据流模型**:
- Flink的运行时基于分布式流数据流模型,这允许它在大规模集群上执行计算。
- 数据流被分割成数据片段(称为记录),并在网络中传输到不同的计算节点。
3. **TaskManager**:
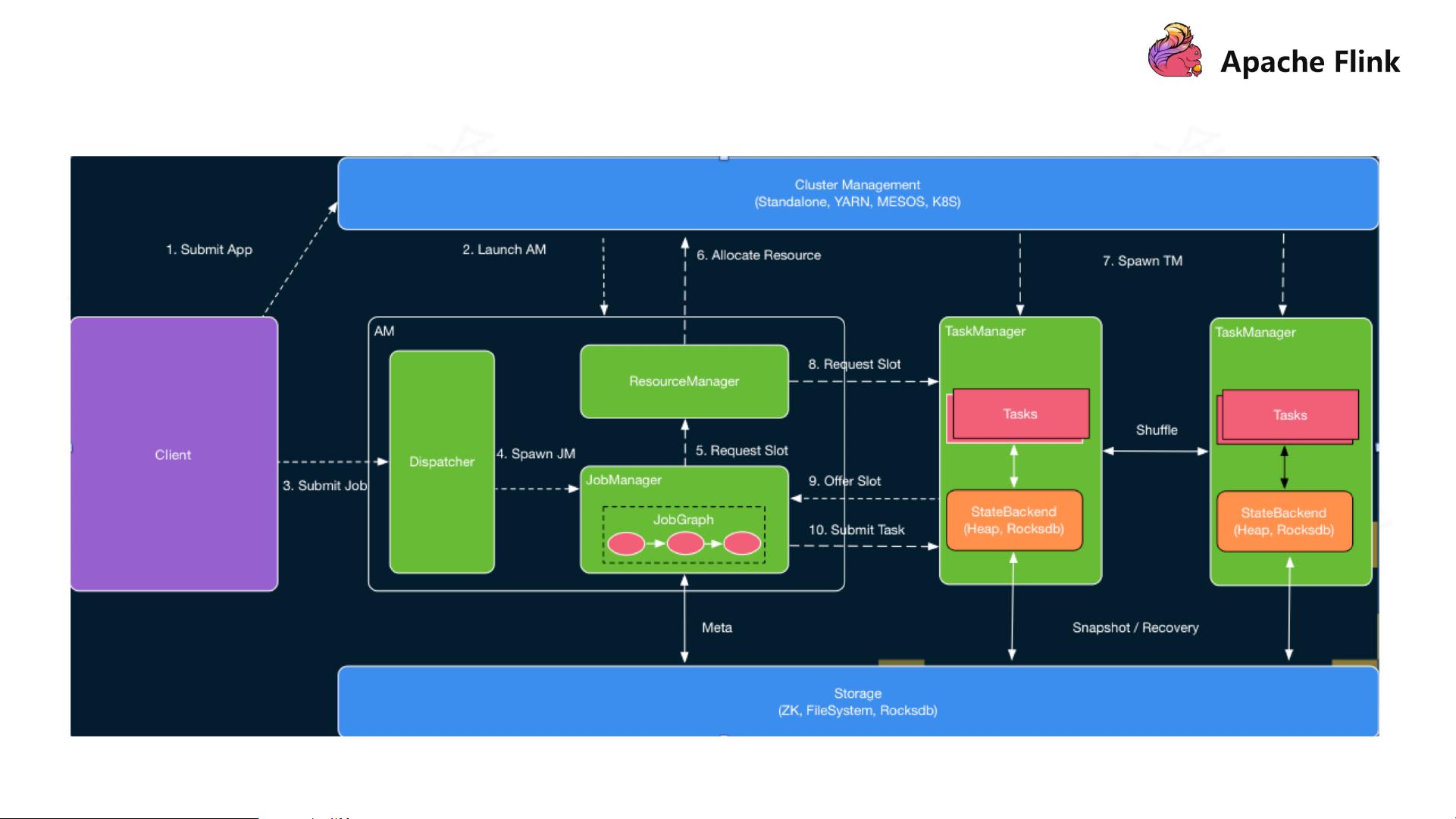
- TaskManager是Flink工作节点上的组件,负责执行任务和管理内存中的数据分区。
- 每个TaskManager包含多个Slot,每个Slot可以运行一个并行任务实例。
4. **JobManager**:
- JobManager是Flink的控制节点,负责调度任务,协调心跳检查,以及存储作业的状态。
5. **Checkpoints and Savepoints**:
- Flink支持状态检查点和保存点,用于实现容错。这些机制确保在系统故障后能够恢复到一致状态。
- 检查点是周期性创建的全局一致性快照,而保存点则允许用户在任何时间点手动保存作业状态。
6. **State Backends**:
- Flink提供了多种状态后端,如内存、 RocksDB等,用于存储和管理算子状态。
- 这些后端可以配置来提供容错性和性能之间的平衡。
7. **流处理与批处理的统一**:
- Flink的Table API和SQL接口统一了流处理和批处理,使得开发者可以使用相同的API处理实时和静态数据。
8. **Event Time and Watermarks**:
- Flink采用事件时间处理模型,允许处理乱序事件,并通过水印机制来处理延迟到达的数据。
9. **FlinkML和Gelly**:
- FlinkML是Flink的机器学习库,提供了一组算法和工具,用于构建分布式机器学习模型。
- Gelly则是图处理库,支持图分析和图算法。
10. **部署模式**:
- Flink可以在本地(SingleJVM)运行,也可以在分布式环境中部署,如独立模式(Standalone)、YARN、云环境(如GCE, EC2)。
总结起来,Apache Flink Runtime的核心架构设计旨在提供高性能、高可用的流处理能力,同时具备灵活的部署选项和强大的数据处理API。通过理解这些核心概念,开发者可以更好地利用Flink构建和优化实时数据分析应用。


 我的内容管理
展开
我的内容管理
展开









