"深度学习与多模态技术综述:模态介绍、架构探究与资源利用"
需积分: 2 154 浏览量
更新于2024-04-10
收藏 39.16MB PDF 举报
Multimodal Deep Learning is a cutting-edge technology that combines multiple modalities such as natural language processing (NLP) and computer vision (CV) to improve the performance of various tasks. This booklet serves as a comprehensive overview of the current state-of-the-art in NLP, CV, and multimodal architectures.
The introduction provides a brief overview of Multimodal Deep Learning, highlighting its importance and applications in various fields. The outline of the booklet is also presented, setting the stage for the subsequent discussions on different modalities.
The section on modalities delves into the latest advancements in NLP and CV. It showcases the state-of-the-art techniques and models used in these domains, highlighting their strengths and limitations. Additionally, it discusses the resources and benchmarks available for NLP, CV, and multimodal tasks, providing a holistic view of the field.
The core of the booklet focuses on multimodal architectures, specifically Image2Text models. These architectures leverage the strengths of both NLP and CV to perform complex tasks such as image captioning, visual question answering, and multimodal sentiment analysis. The section explores the various architectures and frameworks used in Multimodal Deep Learning, providing insights into their design principles and performance metrics.
Overall, this booklet serves as a valuable resource for researchers, practitioners, and enthusiasts interested in Multimodal Deep Learning. It offers a comprehensive overview of the current trends and advancements in the field, showcasing the potential of combining multiple modalities to enhance the performance of AI systems. With its in-depth analysis and insightful discussions, this booklet lays the foundation for future research and innovation in the exciting field of Multimodal Deep Learning.

10 2 Introducing the modalities
2.1.1 Introduction
Natural Language Processing (NLP) exists for about 50 years, but it is more
relevant than ever. There have been several breakthroughs in this branch
of machine learning that is concerned with spoken and written language. In
this work, the most influential ones of the last decade are going to be pre-
sented. Starting with word embeddings, which efficiently model word semantics.
Encoder-decoder architectures represent another step forward by making mini-
mal assumptions about the sequence structure. Next, the attention mechanism
allows human-like focus shifting to put more emphasis on more relevant parts.
Then, the transformer applies attention in its architecture to process the
data non-sequentially, which boosts the performance on language tasks to
exceptional levels. At last, the most influential transformer architectures are
recognized before a few current topics in natural language processing are
discussed.
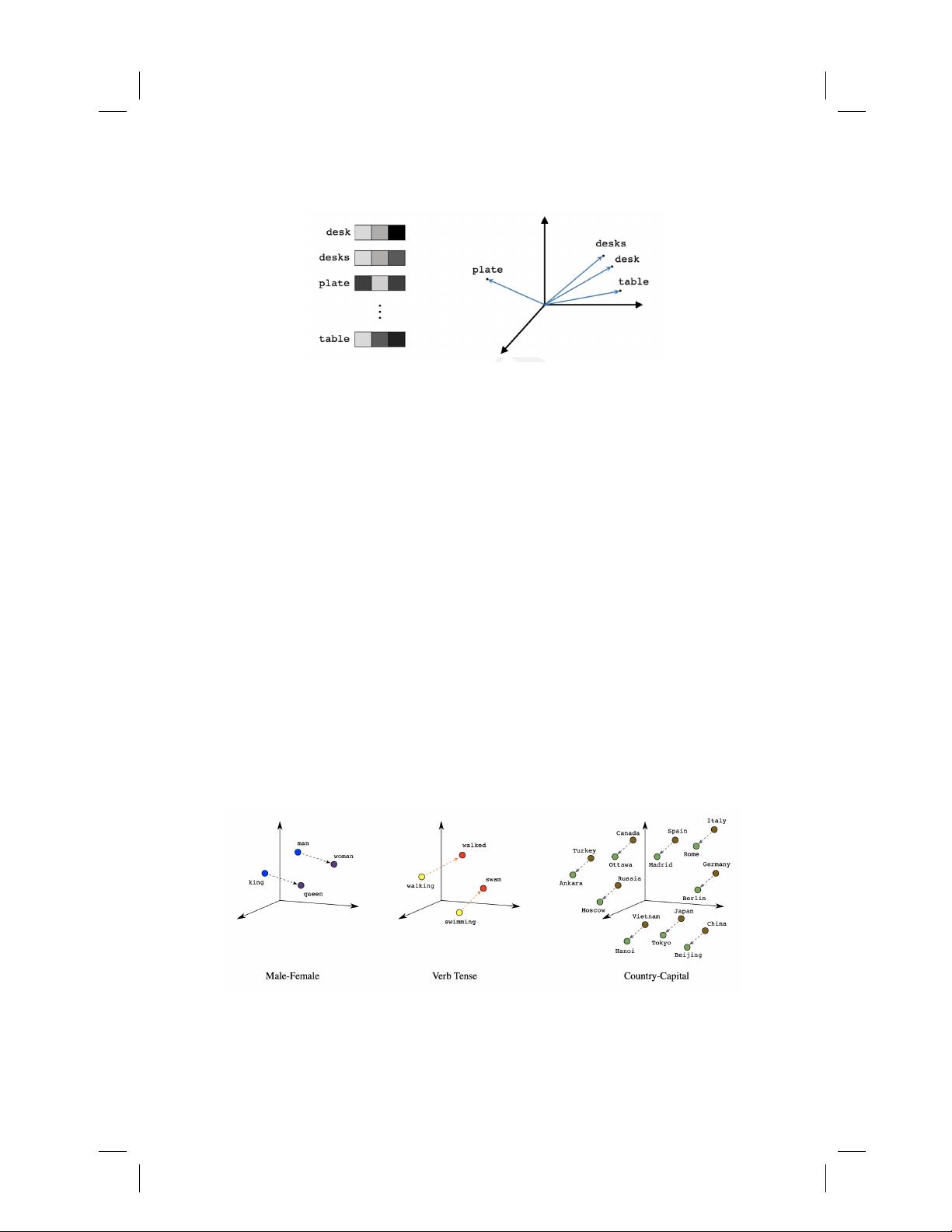
2.1.2 Word Embeddings
As mentioned in the introduction, one of the earlier advances in NLP is
learning word internal representations. Before that, a big problem with text
modelling was its messiness, while machine learning algorithms undoubtedly
prefer structured and well-defined fixed-length inputs. On a granular level, the
models rather work with numerical than textual data. Thus, by using very
basic techniques like one-hot encoding or bag-of-words, a text is converted
into its equivalent vector of numbers without losing information.
In the example depicting one-hot encoding (see Figure 2.1), there are ten
simple words and the dark squares indicate the only index with a non-zero
value.
FIGURE 2.1:
Ten one-hot encoded words (Source: Pilehvar and Camacho-
Collados (2021))
In contrast, there are multiple non-zero values while using bag-of-words, which
is another way of extracting features from text to use in modelling where we
measure if a word is present from a vocabulary of known words. It is called


剩余271页未读,继续阅读
2018-11-23 上传
2021-09-23 上传
2023-10-12 上传
2018-01-07 上传
2021-02-09 上传
2023-09-05 上传
2020-02-24 上传
2023-08-11 上传


T1.Faker
- 粉丝: 2w+
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
