
从从K近邻算法、距离度量谈到近邻算法、距离度量谈到KD树、树、SIFT+BBF算法算法
前言
前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章待写:1、KD树;2、神经网络;3、编程艺术第28章。你看
到,blog内的文章与你于别处所见的任何都不同。于是,等啊等,等一台电脑,只好等待..”。得益于田,借了我一台电脑(借
他电脑的时候,我连表示感谢,他说“能找到工作全靠你的博客,这点儿小忙还说,不地道”,有的时候,稍许感受到受人信任
也是一种压力,愿我不辜负大家对我的信任),于是今天开始Top 10 Algorithms in Data Mining系列第三篇文章,即本文「从
K近邻算法谈到KD树、SIFT+BBF算法」的创作。
一个人坚持自己的兴趣是比较难的,因为太多的人太容易为外界所动了,而尤其当你无法从中得到多少实际性的回报时,所
幸,我能一直坚持下来。毕达哥拉斯学派有句名言:“万物皆数”,最近读完「微积分概念发展史」后也感受到了这一点。同
时,从算法到数据挖掘、机器学习,再到数学,其中每一个领域任何一个细节都值得探索终生,或许,这就是“终生为学”的意
思。
同时,你将看到,K近邻算法同本系列的前两篇文章所讲的决策树分类贝叶斯分类,及支持向量机SVM一样,也是用于解决分
类问题的算法,
而本数据挖掘十大算法系列也会按照分类,聚类,关联分析,预测回归等问题依次展开阐述。
OK,行文仓促,本文若有任何漏洞,问题或者错误,欢迎朋友们随时不吝指正,各位的批评也是我继续写下去的动力之一。
感谢。
第一部分、K近邻算法
1.1、什么是K近邻算法
何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻
居,当K=1时,算法便成了最近邻算法,即寻找最近的那个邻居。为何要找邻居?打个比方来说,假设你来到一个陌生的村
庄,现在你要找到与你有着相似特征的人群融入他们,所谓入伙。
用官方的话来说,所谓K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个
实例(也就是上面所说的K个邻居),这K个实例的多数属于某个类,就把该输入实例分类到这个类中。根据这个说法,咱们
来看下引自维基百科上的一幅图:
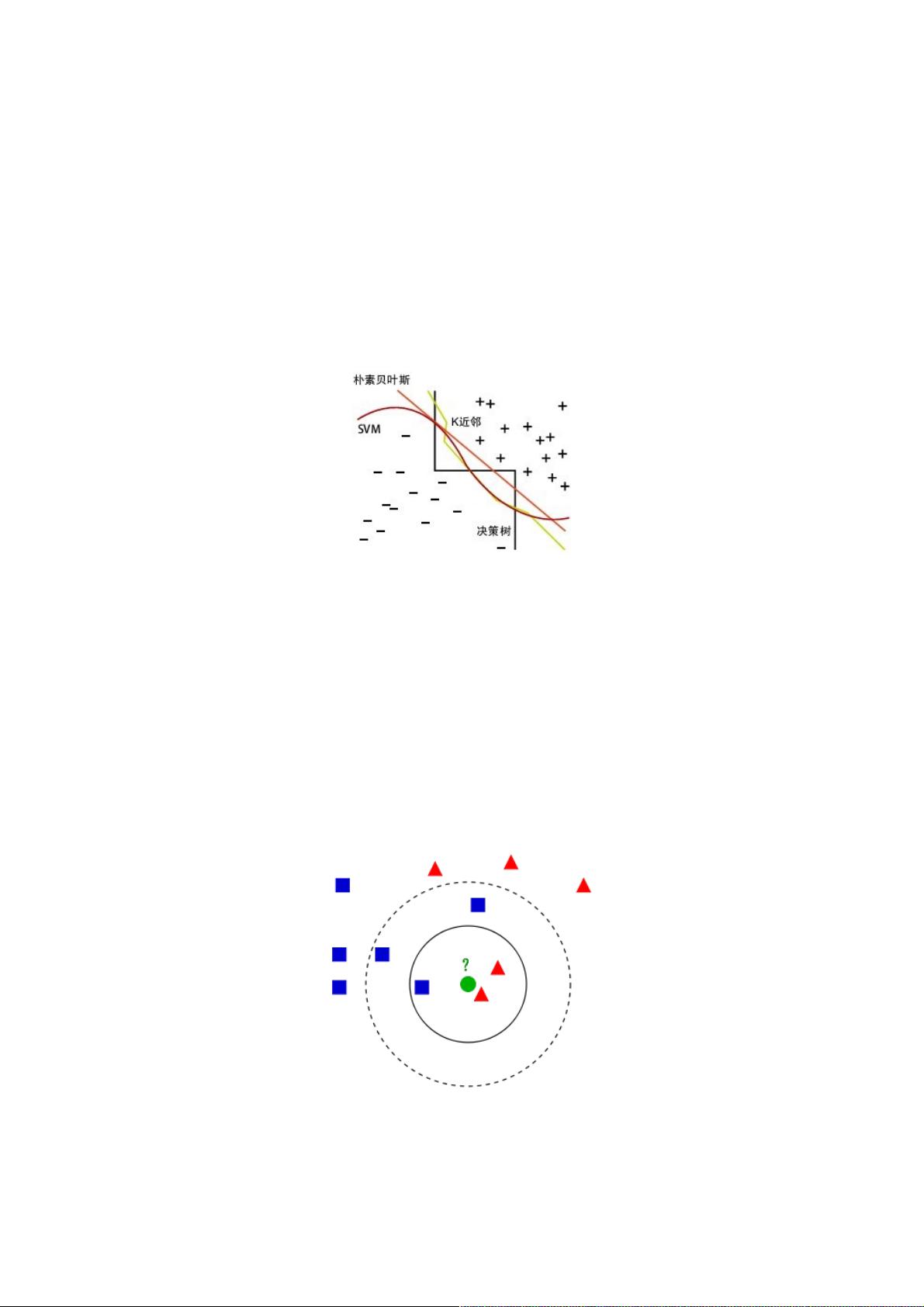
如上图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数
据则是待分类的数据。也就是说,现在,我们不知道中间那个绿色的数据是从属于哪一类(蓝色小正方形or红色小三角形),
下面,我们就要解决这个问题:给这个绿色的圆分类。
我们常说,物以类聚,人以群分,判别一个人是一个什么样品质特征的人,常常可以从他/她身边的朋友入手,所谓观其友,
而识其人。我们不是要判别上图中那个绿色的圆是属于哪一类数据么,好说,从它的邻居下手。但一次性看多少个邻居呢?从
上图中,你还能看到:
如果K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色
下载后可阅读完整内容,剩余6页未读,立即下载

weixin_38520437
- 粉丝: 5
- 资源: 920
 我的内容管理
展开
我的内容管理
展开







最新资源
- 十种常见电感线圈电感量计算公式详解
- 军用车辆:CAN总线的集成与优势
- CAN总线在汽车智能换档系统中的作用与实现
- CAN总线数据超载问题及解决策略
- 汽车车身系统CAN总线设计与应用
- SAP企业需求深度剖析:财务会计与供应链的关键流程与改进策略
- CAN总线在发动机电控系统中的通信设计实践
- Spring与iBATIS整合:快速开发与比较分析
- CAN总线驱动的整车管理系统硬件设计详解
- CAN总线通讯智能节点设计与实现
- DSP实现电动汽车CAN总线通讯技术
- CAN协议网关设计:自动位速率检测与互连
- Xcode免证书调试iPad程序开发指南
- 分布式数据库查询优化算法探讨
- Win7安装VC++6.0完全指南:解决兼容性与Office冲突
- MFC实现学生信息管理系统:登录与数据库操作
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


