精通Elasticsearch:从入门到实践教程
需积分: 10 84 浏览量
更新于2024-07-19
收藏 1.03MB PDF 举报
"Elasticsearch教程"
Elasticsearch是一个基于Lucene构建的分布式、多租户的全文搜索引擎,它提供了一个HTTP web接口和无模式的JSON文档。该技术由Java编写,遵循Apache许可证开源。Elasticsearch是企业搜索领域最受欢迎的引擎,其次是同样基于Lucene的Apache Solr。
在Elasticsearch中,可以搜索各种类型的文档,并且具有可扩展的搜索能力、接近实时的搜索速度以及对多租户的支持。其分布式特性意味着索引可以被划分为多个分片,每个分片可以有零个或多个副本。每个节点托管一个或多个分片,并作为协调器将操作委托给正确的分片。Elasticsearch自动处理重新平衡和路由。相关数据通常存储在同一索引中,由一个或多个主分片和零个或多个副本分片组成。一旦创建了索引,主分片的数量就不能更改。
本电子书提供了一系列教程,帮助你开发自己的基于Elasticsearch的应用程序。覆盖了广泛的主题,包括安装与运维、Java API集成和报告。通过这些直接明了的教程,你可以用最短的时间让自己的项目运行起来。
第1章介绍Elasticsearch,从基础到进阶,讲解了文档、索引、索引设置、映射(包括高级映射)、索引过程、国际化(i18n)、运行Elasticsearch的方式(如独立实例、集群、嵌入应用程序和容器化运行)以及Elasticsearch的应用场景。最后,章节还涵盖了如何进一步学习的建议。
第2章专注于命令行使用Elasticsearch,内容包括检查集群健康状况、管理索引、处理文档、优化映射类型、搜索时间、查询操作、从搜索到洞察以及监控集群状态等。章节末尾提供了下一步的学习路径。
第3章则深入到使用Java进行Elasticsearch开发,介绍了如何使用Java客户端API和Java REST客户端进行交互。
这个教程旨在帮助读者全面理解Elasticsearch的工作原理和实际应用,无论你是初学者还是有经验的开发者,都能从中受益,提升在搜索和数据分析领域的技能。
Elasticsearch Tutorial 4 / 54
– long_range - indexes a range of signed 64-bit integers
– double_range - indexes a range of double-precision 64-bit IEEE 754 floating point values
– date_range - indexes a range of date values represented as unsigned 64-bit integer milliseconds elapsed since system epoch
Cannot stress it enough, choosing the proper data type for the fields (properties) of your documents is a key for fast, effective
search which delivers really relevant results. There is one catch though: the fields in each mapping type are not entirely indepen-
dent of each other. The fields with the same name and within the same index but in different mapping types must have the
same mapping definition. The reason is that internally those fields are mapped to the same field.
Getting back to our application data model, let us try to define the simplest mapping type for books collections, utilizing our
just acquired knowledge about data types.
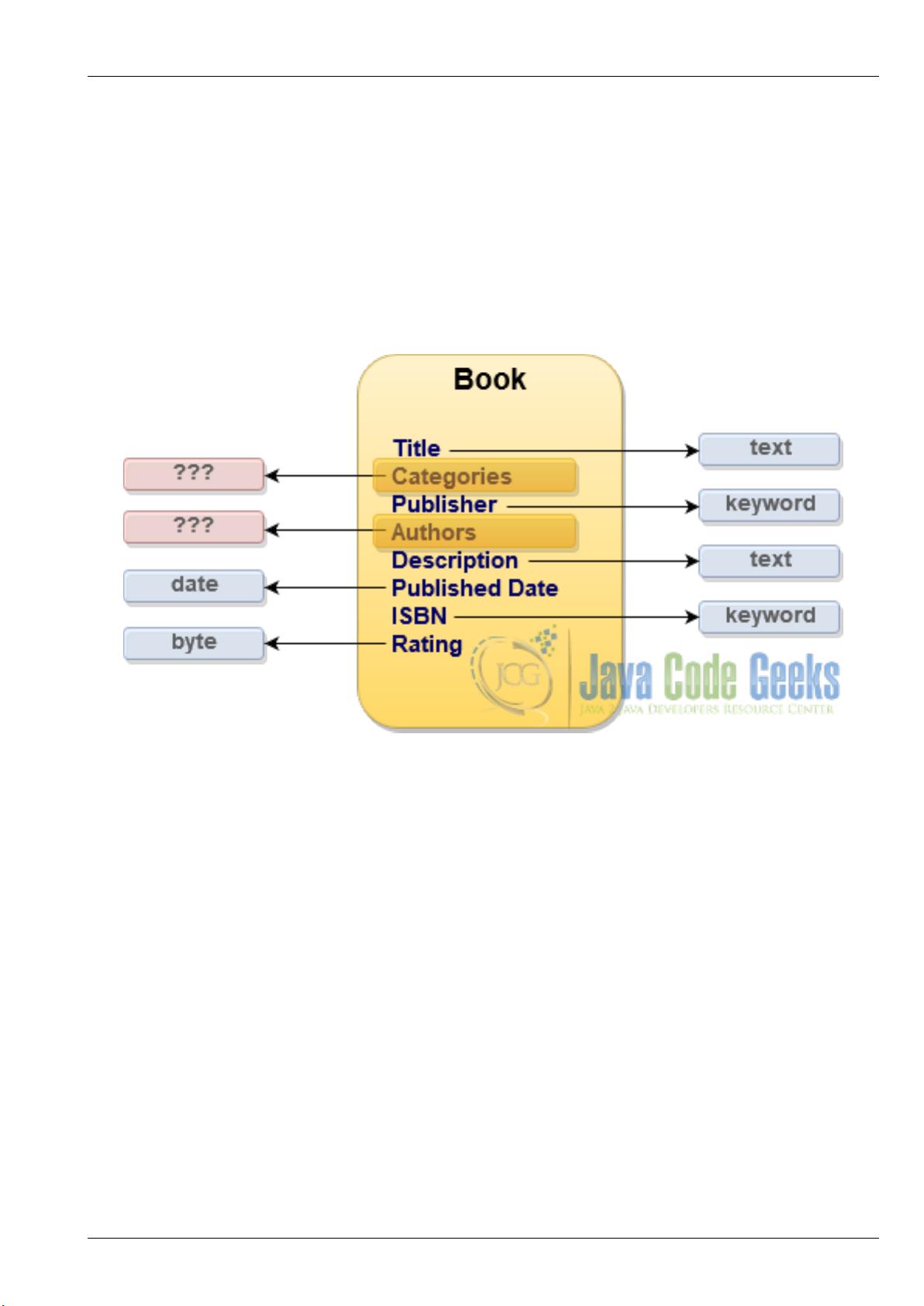
Figure 1.2: Mapping Book Catalog: first attempt
For most of the book properties the mapping data types are pretty straightforward but what about authors and categories?
Those properties essentially contain the collection of values for which Elasticsearch has no direct data type yet, . . . or has it?
1.2.5 Advanced Mappings
Interestingly, indeed Elasticsearch has no dedicated array or collection type but by default, any field may contain zero or more
values (of its data type).
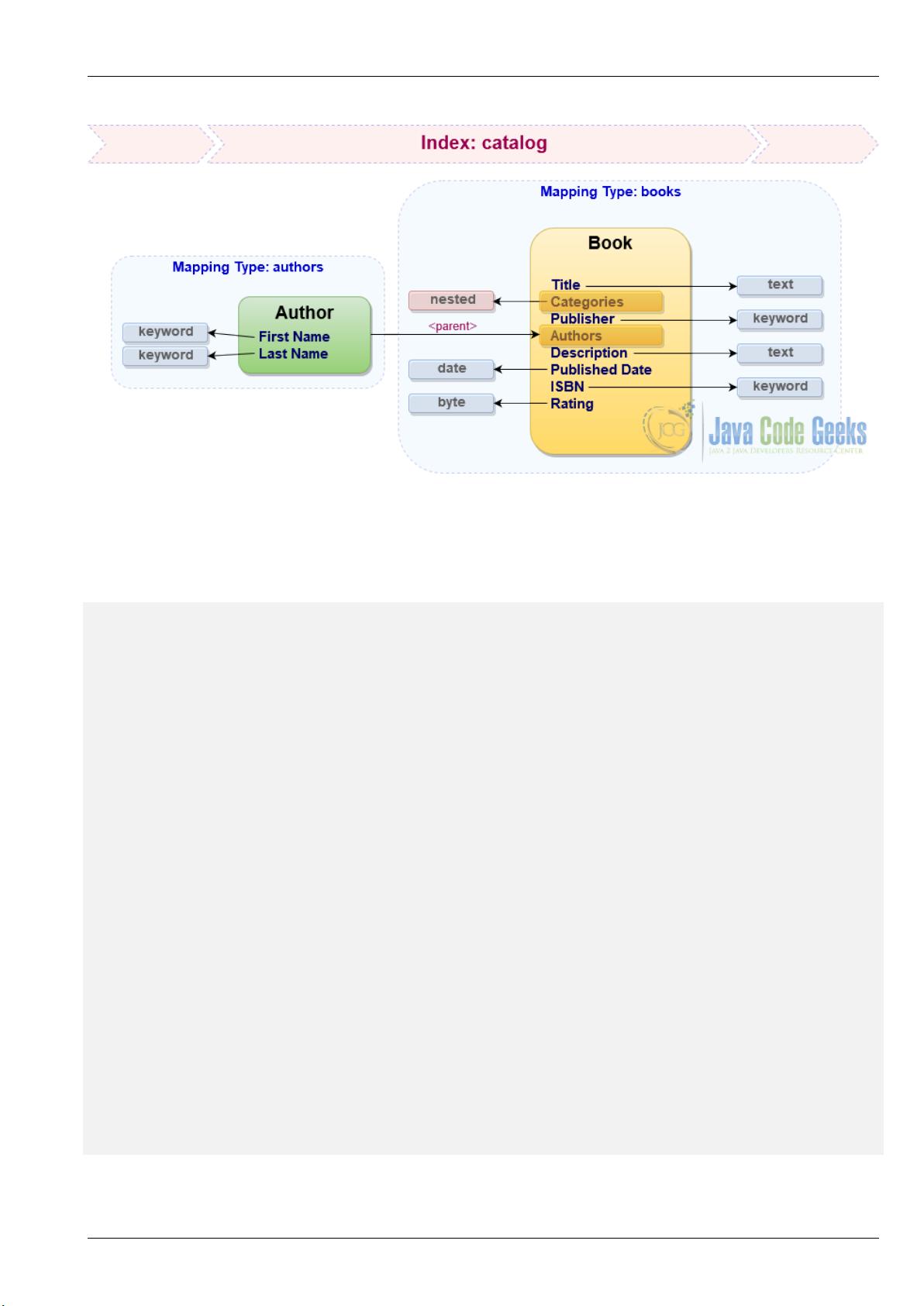
In case of complex data structures, Elasticsearch supports mapping using object and nested data types as well as establishing
parent/child relationships between documents within the same index. There are pros and cons of each approach but in order to
learn how to use those techniques let us store categories as nested property of the books mapping type, while authors
are going to be represented as a dedicated mapping which refers to books as parent.
剩余60页未读,继续阅读
2013-04-10 上传
2024-06-30 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-06-03 上传
2023-08-16 上传

ricoyu2009
- 粉丝: 0
- 资源: 19
 我的内容管理
展开
我的内容管理
展开







最新资源
- AirKiss技术详解:无线传递信息与智能家居连接
- Hibernate主键生成策略详解
- 操作系统实验:位示图法管理磁盘空闲空间
- JSON详解:数据交换的主流格式
- Win7安装Ubuntu双系统详细指南
- FPGA内部结构与工作原理探索
- 信用评分模型解析:WOE、IV与ROC
- 使用LVS+Keepalived构建高可用负载均衡集群
- 微信小程序驱动餐饮与服装业创新转型:便捷管理与低成本优势
- 机器学习入门指南:从基础到进阶
- 解决Win7 IIS配置错误500.22与0x80070032
- SQL-DFS:优化HDFS小文件存储的解决方案
- Hadoop、Hbase、Spark环境部署与主机配置详解
- Kisso:加密会话Cookie实现的单点登录SSO
- OpenCV读取与拼接多幅图像教程
- QT实战:轻松生成与解析JSON数据
