淘宝分布式数据层的发展与演进
需积分: 9 97 浏览量
更新于2024-07-28
收藏 898KB PDF 举报
"淘宝分布式数据层的发展历程及关键技术"
淘宝作为中国最大的电商平台,其背后的技术架构是支撑海量交易的关键。其中,分布式数据层是淘宝技术体系的重要组成部分,它旨在解决随着业务发展而带来的数据量巨大、访问压力增大的问题。本摘要将详细探讨淘宝分布式数据层的发展历程以及关键的技术实践。
在2005年前,淘宝主要采用的是传统的单体架构,数据存储在ORACLE数据库上,配合IBM小型机和EMC高端存储。随着业务增长,数据水平拆分成为必要,以缓解单一数据库的压力。为此,淘宝引入了`common-dao`,这是一种基于数据库标识或用户ID进行路由的方案,尽管对开发人员来说并不完全透明,但已初步实现了数据分片。
2007年,淘宝开始进行服务化改造,将业务逻辑拆分成多个服务中心,这有效地解决了数据库连接数的问题并提升了业务稳定性。然而,服务化也带来了新的挑战,即重复的逻辑分散在不同的应用中,对分布式数据管理提出了更高要求。
2008年,淘宝面临读写比例严重失衡的问题,读请求远大于写请求。为解决这一问题,淘宝引入了读写分离策略,采用非对称数据复制,主库(Master)处理写操作,从库(Slave)处理读操作,降低了主库的压力。为了实现这一架构,淘宝团队开发了自己的数据复制解决方案,通过解析主库日志或拦截SQL操作进行数据同步,确保从库与主库之间的数据一致性。
随着时间的推移,淘宝分布式数据层不断演进,支持更多的从库(Slave),构建了复杂的主从复制网络。同时,为了提高系统的可扩展性和容错性,淘宝还可能采用了如分片、负载均衡、故障切换等技术,以确保在大规模并发环境下,数据能够高效、稳定地被处理和访问。
淘宝分布式数据层的发展历程展示了从简单的数据拆分到复杂的服务化和读写分离,再到高效的数据复制和容错机制的逐步构建。这些技术实践不仅为淘宝提供了强大的数据处理能力,也为其他大型互联网公司提供了宝贵的参考经验。
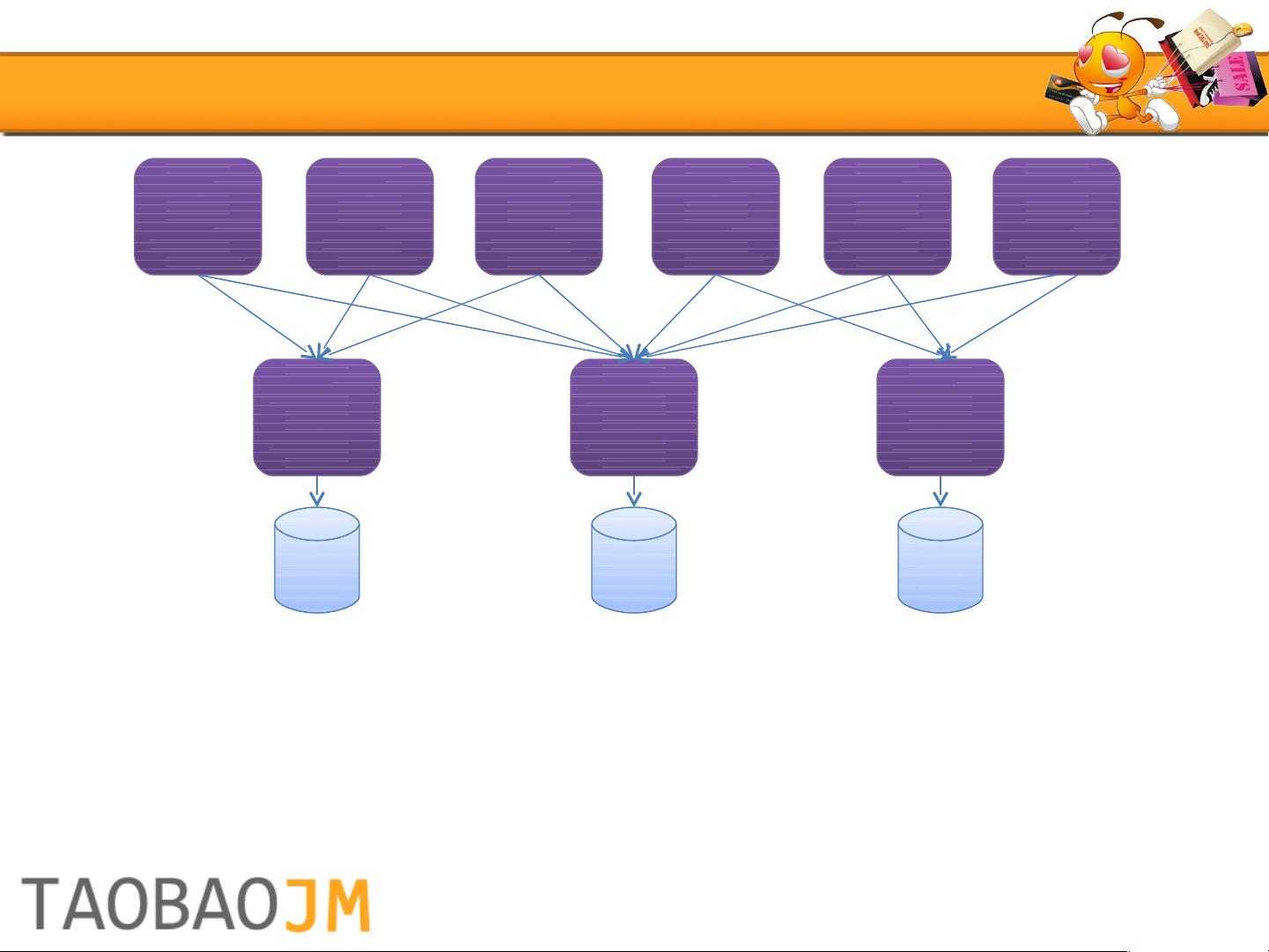
2007
业务
中心 1
业务
中心 2
业务
中心 3
服务化
解决了业务核心的稳定和一致的问题
解决了重要数据库的连接数的问题
也影响了淘宝分布式数据层的诞生和发展
前台
应用 1
前台
应用 1
前台
应用 1
前台
应用 2
前台
应用 2
前台
应用 2

剩余41页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

骇客归来
- 粉丝: 1
- 资源: 12
 我的内容管理
展开
我的内容管理
展开







最新资源
- pawiis_pet_service
- misc.ka-开源
- rabbitmq 3.8.14版本可以用的延时插件
- EDSR(增强型深度超高分辨率)Matlab端口:EDSR(增强型深度超高分辨率)Matlab单图像超分辨率-matlab开发
- ICT-in-de-Wolken:ICT的信息库,位于沃尔肯(Wolken)
- valorant:圭亚那勇士
- FlutterCTipApp_03_实现滚动渐变的AppBar
- 媒体广告中的市场研究方法PPT
- MyFirstRep-Broadcast-Receiver-with-Vibrate-Alert-
- cursoAngular4:使用CodeSandbox创建
- SKIN_GCN:皮肤检测(使用GCN)
- grooming:美容网站 - Ignacio Prados
- constellation:适用于C ++的高性能线性代数库
- 元旦晚会策划案
- haxm-7.5.6.tar.gz
- nybble_core:使用Deployer创建的ARK.io区块链
