淘宝分布式数据层:从水平分库到读写分离的发展历程
需积分: 9 21 浏览量
更新于2024-07-28
收藏 898KB PDF 举报
"淘宝分布式数据层的发展历程及关键技术"
淘宝作为中国最大的电商平台,其背后的数据架构经历了从简单到复杂的演变,以应对日益增长的业务需求和海量数据的处理。淘宝的分布式数据层是这一发展历程中的关键组成部分,它旨在提供高效、稳定的数据库服务,并解决了在高并发环境下的连接数问题。
在早期,淘宝的数据架构基于ORACLE数据库和IBM小型机,配合EMC高端存储。为了应对数据量的增长,淘宝开始尝试水平分库策略,通过`common-dao`实现基于数据库标识或用户ID的路由,但这种方法并未完全透明地对开发人员隐藏数据库分片细节。例如,URL中还包含了数据库标识,如`http://auction1.taobao.com/auction/item_detail-0db1-a0c6773727d2e1184badbcf9cdc54c07.jhtml`。
随着业务的发展,服务化的理念在2007年被引入,将重复的逻辑集中在服务中心,解决了数据库连接数问题,同时也推动了淘宝分布式数据层的进一步发展。服务化使得应用可以更专注于业务逻辑,而不再直接与特定数据库交互。
2008年,淘宝面临读写严重不成比例的问题(约18:1),因此引入了读写分离策略。通过非对称数据复制,将主库(Master)与多个从库(Slave)进行配对,主库负责写操作,从库负责读操作,有效缓解了数据库压力。实现读写分离的方式包括解析主库日志进行复制以及拦截SQL操作进行同步。这种结构允许低成本地扩展读取能力,同时尽量减少对开发者的影响。
随着时间的推移,淘宝的分布式数据层不断演进,从最初的水平分库、服务化到读写分离,再到更复杂的复制机制,这些关键技术共同构建了一个强大且灵活的数据处理平台,支撑了淘宝业务的快速发展和高可用性。通过这样的分布式数据层设计,淘宝能够处理大规模并发请求,确保了系统的稳定性和用户体验。
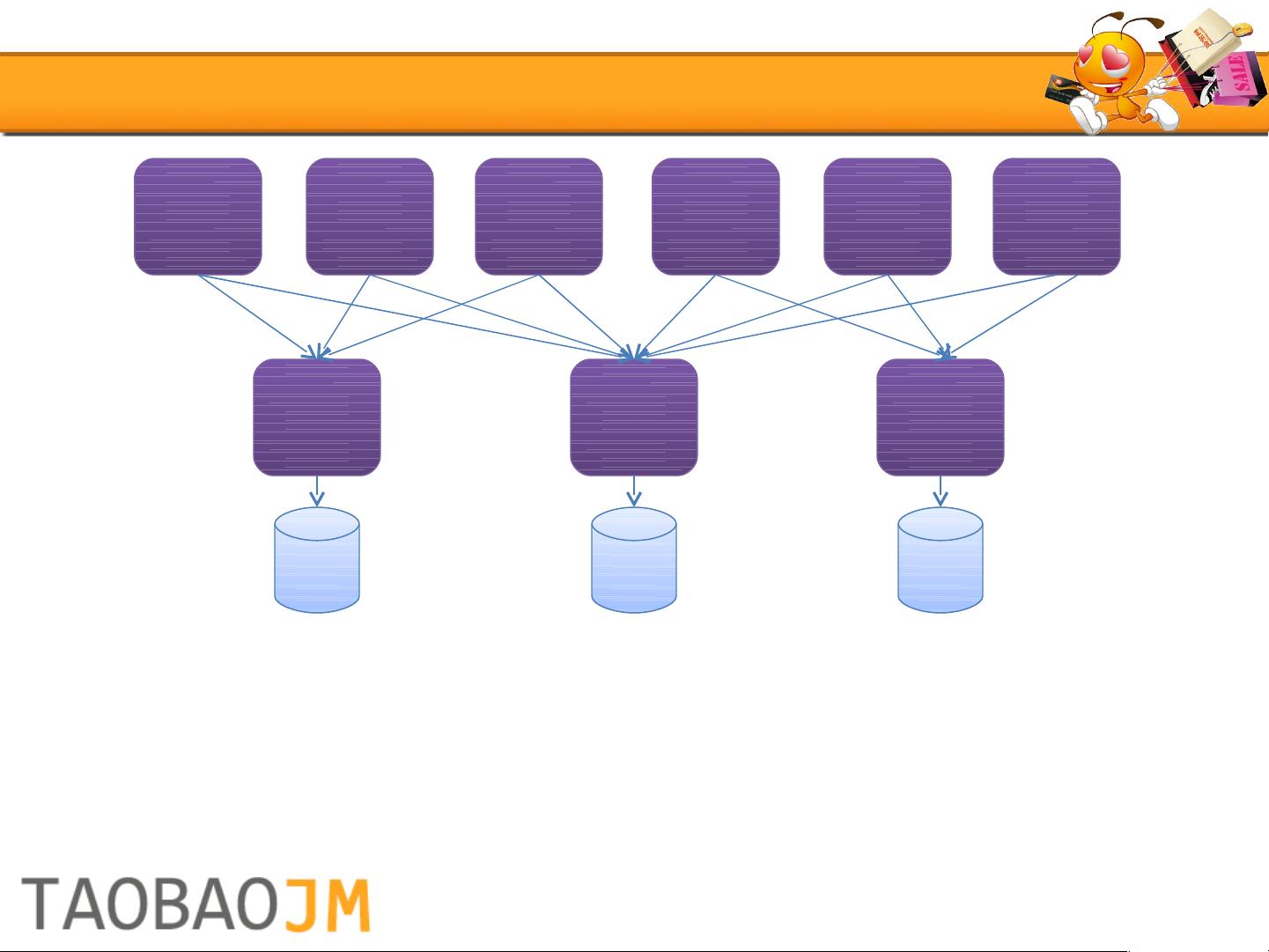
2007
业务
中心 1
业务
中心 2
业务
中心 3
服务化
解决了业务核心的稳定和一致的问题
解决了重要数据库的连接数的问题
也影响了淘宝分布式数据层的诞生和发展
前台
应用 1
前台
应用 1
前台
应用 1
前台
应用 2
前台
应用 2
前台
应用 2

剩余41页未读,继续阅读
2011-07-18 上传
108 浏览量
160 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

justyzy
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高质量C_C++编程指南
- Simplified_SD_Host_Controller_Spec.pdf
- more effective C++
- forward与redirect区别
- javascript教程
- MCTS Self-Paced Training Kit(Microsoft .NET Framework 2.0)
- 全国计算机等级考试二级C语言笔试试题及答案
- pc上安装MAC os
- cisco CCNP WOLF笔记
- 二级c重点知识详解与分析
- 常见的50条SQL语句,基本包含了SQL的基础
- tcxgrid的用法
- Scrum Process
- 思科网络工程师认证完全手册
- MATLAB-------数字滤波器设计与仿真
- java NIO原理和使用
