高速公路短期旅行时间预测:数据驱动方法的综述
需积分: 10 74 浏览量
更新于2024-07-16
收藏 280KB PDF 举报
"短途高速公路旅行时间预测:数据驱动方法的综述"
这篇论文"Short-term travel-time prediction on highway: a review of the data-driven approach"主要探讨了如何利用数据驱动的方法来预测高速公路的短期旅行时间。在当今信息化社会,交通管理系统需要实时、准确地预测旅行时间以优化交通流量、提升道路效率并提供给驾驶者有效的行程规划信息。
数据驱动的方法是近年来在交通工程领域发展起来的一种重要技术。它依赖于收集到的各种交通数据,如车辆速度、交通流量、路面状况等,通过高级的数据分析和机器学习算法,构建预测模型。这些模型能够处理大量的历史数据,找出隐藏的模式和趋势,并以此预测未来的旅行时间。
论文作者包括Simon Oha、Young-Ji Byon、Kitae Jang和Hwasoo Yeo,他们分别来自韩国科学技术院(KAIST)、哈利法科技大学(KUSTAR)以及Cho Chun Shik绿色交通研究生院。这些研究机构在交通技术和数据分析方面具有显著的专业背景。
文章可能涵盖了以下关键知识点:
1. **数据源**:讨论了不同类型的数据源,如交通监控摄像头、车载传感器、GPS设备、浮动车数据等,这些数据源如何用于收集实时交通信息。
2. **数据预处理**:在进行预测模型构建前,通常需要对原始数据进行清洗、整合和标准化,以消除异常值、缺失值并确保数据质量。
3. **预测模型**:介绍了多种数据驱动的预测模型,如时间序列分析、支持向量机(SVM)、随机森林、神经网络等,以及它们在旅行时间预测中的应用和优势。
4. **性能评估**:讨论了评价预测模型准确性的指标,如均方误差(MSE)、平均绝对误差(MAE)和决定系数(R²),以及如何通过交叉验证来评估模型的稳定性和泛化能力。
5. **挑战与未来方向**:论文可能还涉及数据驱动预测面临的挑战,如大数据处理的复杂性、实时性需求、模型的可解释性以及如何应对交通状况的不确定性等问题,并提出未来的研究方向。
这篇综述对于理解数据驱动的旅行时间预测方法在交通工程中的应用具有重要意义,不仅为交通管理部门提供了理论参考,也为交通领域的研究者提供了最新的研究进展和潜在的研究问题。
(3) Parametric regression (ARIMA, Kalman filter), Non-parametric regression
(Nearest neighbourhood), and NNs (Chrobok, 2005)
(4) Naı
¨
ve (Instantaneous, Historical averages, and Cluster analysis), Parametric
(Traffic flow models (Model based), Linear regression, ARIMA, Kalman filter-
ing), and Non-parametric models (NNs, k-NN, etc.) (van Hinsbergen, van
Lint, & Sanders, 2007)
(5) Regression (Linear regression), Time series (ARIMA, Kalman filter), and NNs
(Shen, 2008)
(6) Parametric (Regression models, Time series (ARIMA, Kalman Filter)) and
Non-parametric (Artificial intelligence (ANN), Pattern search (k-NN))
approaches (Yu et al., 2008)
(7) Parametric (Linear regression, Time series, Kalman filter) and Non-parametric
(NNs, Bayesian models, pattern recognition (k-NN)) methods (Fei et al., 2011)
In compliance with the previous researches’ taxonomy on the data-driven
approach, we propose a set of criteria for classifying and evaluating the data-
driven approaches considering underlying mechanisms and theoretical prin-
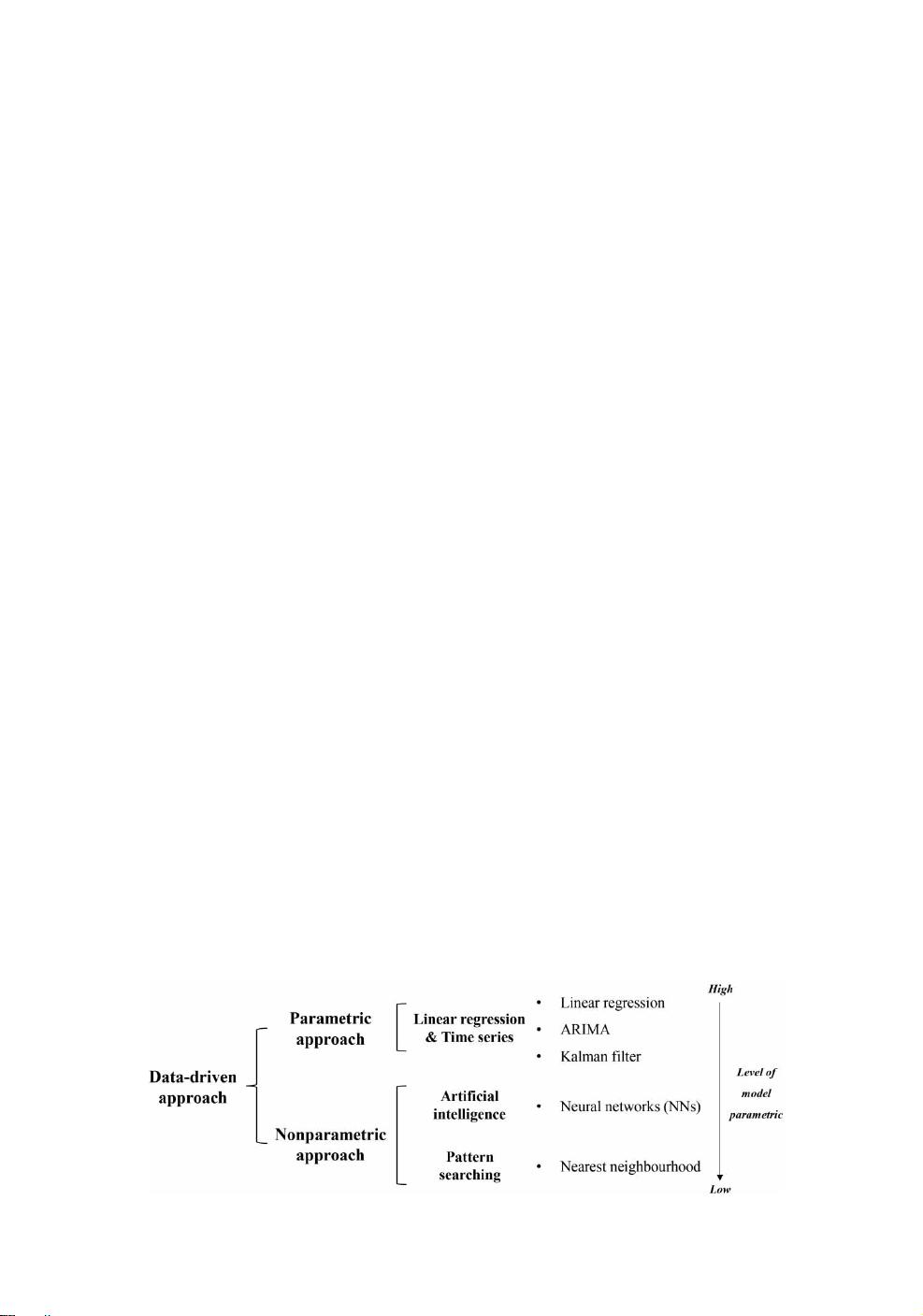
ciples. Figure 1 shows the taxonomy of data-driven approaches.
In the parametric approach the functional relationship between the explanatory
and response variables is known, and some unknown parameters may be esti-
mated from the training set. Selecting input variables and estimating coefficients
minimizing errors are the key issues for this approach. The parametric statistical
approaches are known to perform quite accurately despite their simple formu-
lations provided that they have well-established theoretical and mathematical
backgrounds and are validated by transportation engineers. The main drawback
of this approach is that coefficients are site-specific and it is difficult to implement
in large-scale networks.
NNs are non-parametric models that predict travel-times by training them-
selves with historical data which mimic the mechanisms of a human brain. The
parameters (e.g. weights) have no physical meaning in regard to the problems
to which they are applied. The main advantage of using NNs in transportation
applications is that they can handle complex and non-linear properties that are
inherently embedded in the nature of many transportation engineering problems.
The method has been validated by many researchers with acceptable accuracy.
Complex training with site-specific limitations and black-box procedures
involved are the main demerits of artificial NNs (ANNs). Poor logical descriptions
with regards to traffic mechanisms may be questioned by various audiences who
Figure 1. Taxonomy of a data-driven approach to travel-time prediction.
Short-term Travel-time Prediction on Highway 7
Downloaded by [University of Nebraska, Lincoln] at 07:32 08 April 2015

剩余30页未读,继续阅读
2018-06-05 上传
2020-08-31 上传
2019-07-31 上传
2023-04-20 上传
2023-05-03 上传
2023-08-08 上传
2023-03-31 上传
2023-05-18 上传
2023-06-06 上传

qq_24890901
- 粉丝: 19
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
