

vation is made by Mellish & Dale, 1998, p.351). A fundamental contribution
in this context is by E l had ad et al. (1997), who describe a unification-based
approach, unifying conceptual representations (i.e., preverbal messages) with
grammar rules encoding lexical as well as syntactic choices.
2.5 Referring expression generation
Referring Expression Generation (reg) is characterised by Reiter and Dale
(1997, p.11) as “the task of selec t i ng words or phrases to identify domain en-
tities”. This characterisation suggests a close similarity to lexicalisation, but
Reiter and Dale (2000) point out that the essential di↵erence is that referring
expression generation is a “discrimination task, where the system needs to com-
municate sufficient information to distinguish one domain entity from other
domain entities”. reg is among the tasks within the field of automated text
generation that has received most attention in recent years (Mellish et al., 2006;
Siddharthan et al., 2011) . Since it can be separated relatively easily from a
specific application domain and studied in its own right, various ‘standalone’
solutions for the reg problem exist.
In our running example, the three bradycardia events shown in Figure 1b
are later represented as a set of thre e entities under the theme argument of be,
following lex i cal i sat i on (Figure 1c). How the system refers to them will depend,
among ot he r things, on whether they’ve already been mentioned (in which case,
a pronoun or de fin i t e description might work) and if so, whether they need to
be distinguished from any other sim il ar entities (in which case, they might need
to be distinguished by some properties, such as the time when they occurred).
The first choice is therefore related to referential form:whetherentities
are referred to using a pronoun, a proper name or an (in)definite description,
for example. This depends partly on the extent to which the entity is ‘in fo-
cus’ or ‘salient’ (see e.g., Poesio et al., 2004) and in de ed such notions under l ie
many computational accounts of pr onoun generation (e.g., McCoy & S tr u be,
1999; Callaway & Lester, 2002; Kibble & Power, 2004). Choosi n g referential
forms has recently been the topic of a series of share d tasks on the Genera-
tion of Referring Expressions i n Context (grec; Belz et al., 2010), using data
from Wikipedia articles, which included choices such as reflexive pronouns and
proper names. Many systems participating in this challenge framed the prob-
lem in terms of classification among these many opti on s. Still, it is probably
fair to say that much work on referential form has focussed on when to use
pronouns. Forms such as proper names remain understudied, although recently
various researchers have highlighted the problems of proper name generation
(Siddharthan et al., 2011; van Deemter, 2016; Castro Ferreira et al., 2017).
Determining the referential content usually comes into play w he n the chosen
form is a descrip ti on . Typically, there are multiple entities wh ich have the same
referential category or type in a domain (more than one player, for example, or
several bradycardias). As a result, other properties of the entity will need to be
mentioned if it is to be identified by the reader or hearer . Earlier reg research
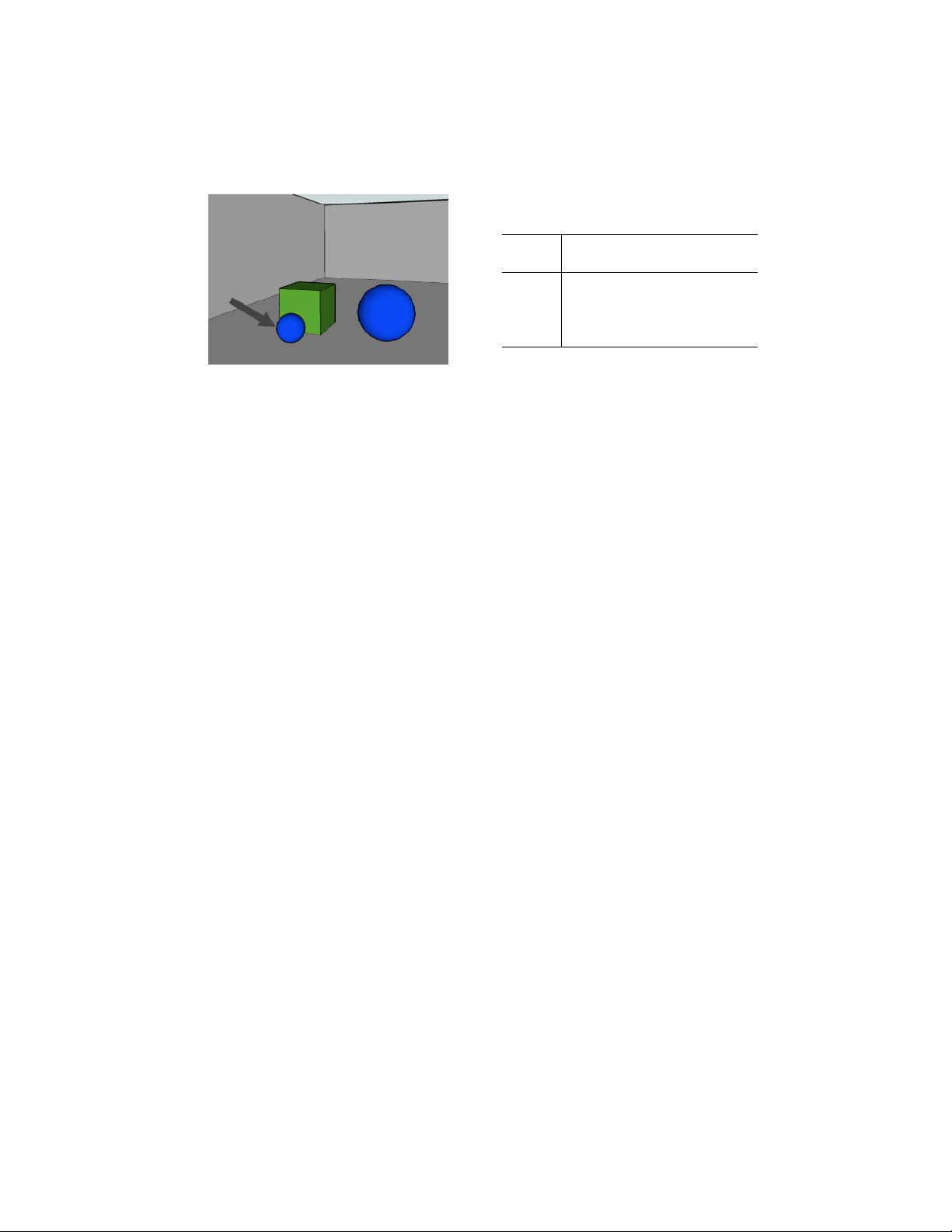
often worked with simple visual domains, such as Figure 2a or its corresponding
16



剩余117页未读,继续阅读

GreyWarden
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Lombok 快速入门与注解详解
- SpringSecurity实战:声明式安全控制框架解析
- XML基础教程:从数据传输到存储解析
- Matlab实现图像空间平移与镜像变换示例
- Python流程控制与运算符详解
- Python基础:类型转换与循环语句
- 辰科CD-6024-4控制器说明书:LED亮度调节与触发功能解析
- AE particular插件全面解析:英汉对照与关键参数
- Shell脚本实践:创建tar包、字符串累加与简易运算器
- TMS320F28335:浮点处理器与ADC详解
- 互联网基础与结构解析:从ARPANET到多层次ISP
- Redhat系统中构建与Windows共享的Samba服务器实战
- microPython编程指南:从入门到实践
- 数据结构实验:顺序构建并遍历链表
- NVIDIA TX2系统安装与恢复指南
- C语言实现贪吃蛇游戏基础代码
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


