系统设计深度解析:从分布式ID到搜索引擎
需积分: 9 68 浏览量
更新于2024-07-17
收藏 1.34MB PDF 举报
"系统设计资料包括了众多关键的IT知识点,涵盖了从基础的系统设计到复杂的分布式系统构建。这份资料适合高级工程师和架构师学习,提供了深入讲解的系统设计题目和解决方案,帮助读者掌握系统设计的核心技能。"
在系统设计中,首先我们需要理解的是分布式ID生成器的设计。分布式ID生成器的目标是保证在分布式环境下生成的ID全局唯一,并且通常要求这些ID能够按照时间顺序大致排序。例如,在用户ID、微博ID、订单ID等场景中,这样的ID系统是非常必要的。设计时,可以考虑使用Twitter的Snowflake算法或者基于数据库自增ID的分布式方案。
接下来,短网址系统(TinyURL)是一个常见的系统设计问题,其目标是将长URL转化为短链接,同时保证短链接的唯一性和可解析性。设计中通常涉及到哈希算法、数据库存储以及URL编码解码。
信息流(NewsFeed)的实现则需要处理大量的用户动态和个性化推荐。这涉及到数据结构优化(如使用Trie树或Bloom Filter减少重复)、时间窗口算法以及推荐算法(如协同过滤或基于内容的推荐)。
定时任务调度器的设计是一个关键的后台服务,它需要处理任务的调度、执行、重试以及故障恢复策略。常见的实现方式有基于CRON表达式或者基于队列的调度模型。
API限速是保护系统免受恶意请求攻击的重要手段,可以使用滑动窗口算法或令牌桶算法来限制请求速率。
线程安全的HashMap在多线程环境中保证数据一致性,可以使用Java的ConcurrentHashMap或者自定义锁机制实现。
在流量监控中,如何找出最近一小时内访问频率最高的10个IP,可能需要用到最小堆或者TTL缓存来实时维护热点IP列表。
负载均衡是分布式系统的基础,常见的算法有轮询、随机、权重轮询等,也可以结合DNS、硬件负载均衡器或软件负载均衡器如Nginx来实现。
Key-Value存储引擎设计,比如Redis或Memcached,需要考虑数据持久化、内存管理以及一致性策略。
网络爬虫涉及网页抓取、URL调度、反爬策略及HTML解析,通常使用多线程、异步IO或者Scrapy框架。
PageRank是搜索引擎排名算法之一,用于评估网页的重要性,涉及到图论和迭代计算。
搜索引擎的设计涵盖全文检索、倒排索引、TF-IDF算法、布尔模型以及查询优化。
大数据处理包括Hadoop、Spark等技术,处理海量数据的存储、计算和分析。
数据流采样、基数估计、频率估计和TopK问题常常出现在实时数据分析中,可以使用布隆过滤器、HyperLogLog等数据结构。
范围查询和成员查询在数据库系统中常见,涉及索引设计和查询优化。
跳表(SkipList)是一种高效的数据结构,用于快速查找和插入操作,常用于数据库索引。
Raft是一种简单易懂的分布式一致性算法,适用于分布式系统中的领导者选举。
这些系统设计知识点覆盖了软件开发的多个方面,通过学习和实践,能帮助工程师提升解决复杂系统问题的能力。
如果你手痒想要手工设计这个存储,那就是另一个话题了,你需要完整地造一个KV存储引擎轮子。当前流行的KV存储引擎
有LevelDB何RockDB,去读它们的源码吧:D
301还是302重定向
这也是一个有意思的问题。这个问题主要是考察你对301和302的理解,以及浏览器缓存机制的理解。
301是永久重定向,302是临时重定向。短地址一经生成就不会变化,所以用301是符合http语义的。但是如果用了301,
Google,百度等搜索引擎,搜索的时候会直接展示真实地址,那我们就无法统计到短地址被点击的次数了,也无法收集用户
的Cookie,UserAgent等信息,这些信息可以用来做很多有意思的大数据分析,也是短网址服务商的主要盈利来源。
所以,正确答案是302重定向。
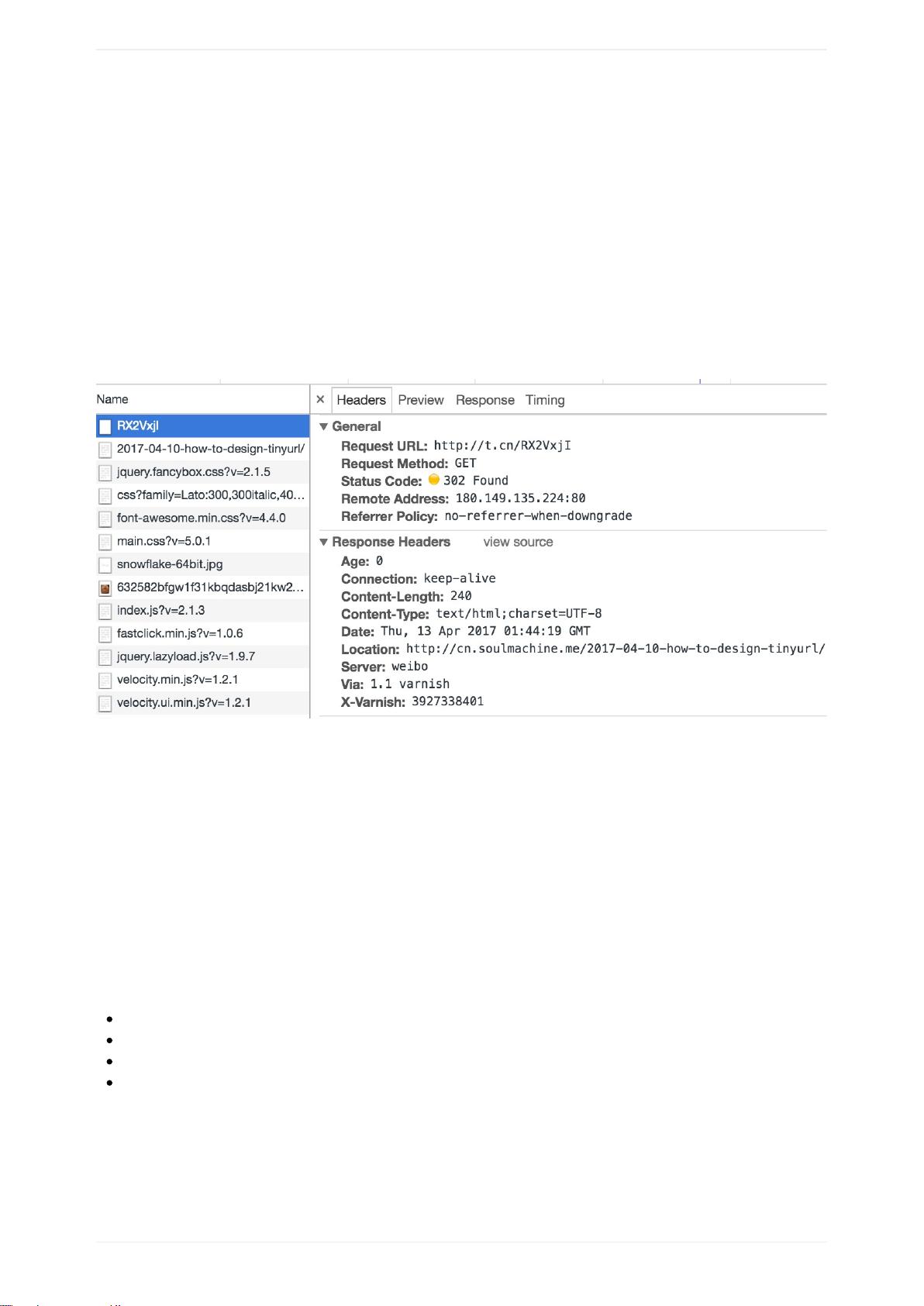
可以抓包看看新浪微博的短网址是怎么做的,使用Chrome浏览器,访问这个URLhttp://t.cn/RX2VxjI,是我事先发微博自动
生成的短网址。来抓包看看返回的结果是啥,
可见新浪微博用的就是302临时重定向。
预防攻击
如果一些别有用心的黑客,短时间内向TinyURL服务器发送大量的请求,会迅速耗光ID,怎么办呢?
首先,限制IP的单日请求总数,超过阈值则直接拒绝服务。
光限制IP的请求数还不够,因为黑客一般手里有上百万台肉鸡的,IP地址大大的有,所以光限制IP作用不大。
可以用一台Redis作为缓存服务器,存储的不是ID->长网址,而是长网址->ID,仅存储一天以内的数据,用LRU机制进行淘
汰。这样,如果黑客大量发同一个长网址过来,直接从缓存服务器里返回短网址即可,他就无法耗光我们的ID了。
参考资料
Sharding&IDsatInstagram
TicketServers:DistributedUniquePrimaryKeysontheCheap
TwitterSnowflake
短URL系统是怎么设计的?
短网址系统(TinyURL)
7

剩余38页未读,继续阅读
2024-11-22 上传
2024-11-22 上传
2024-11-22 上传

zhichuanxun
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
