文本分析参数估计:LDA模型详解与推断算法
需积分: 9 59 浏览量
更新于2024-07-18
收藏 1.46MB PDF 举报
本篇技术报告深入探讨了文本分析中的参数估计方法,特别是与离散概率分布相关的概念。参数估计在文本建模中具有特殊的重要性,因为它决定了模型的性能和适应性。报告首先介绍了基本的参数估计方法,包括最大似然估计、后验估计以及贝叶斯方法。重点提到了共轭分布的概念,这是一种简化参数估计过程的重要工具,它使得某些复杂的分布可以通过易于处理的形式进行参数更新。
接着,文章详细讲解了隐含狄利克雷分配(Latent Dirichlet Allocation, LDA)这一主题模型。LDA假设文档由多个潜在主题组成,每个单词在文档中由这些主题混合而成。报告中对LDA的完整推导进行了详尽阐述,包括基于吉布斯采样(Gibbs Sampling)的近似推理算法,这是一种常用的无监督学习技术,用于估计文档中主题的分布和主题词汇的混合比例。
狄利克雷超参数是LDA中的关键部分,它们控制了主题分布的复杂性和文档中各个主题的平衡。报告中涉及了如何估计这些超参数,通常通过调整模型以最大化数据的似然函数或遵循特定的先验知识来实现。
最后,报告讨论了LDA模型的分析方法,包括模型评估指标(如 perplexity 和 held-out log likelihood),以及模型诊断工具,如话题一致性检查和可视化技术,以便于理解模型的性能和潜在主题的内容。
本报告为理解和应用文本分析中的参数估计提供了一个全面的指南,特别是在LDA模型的背景下,它强调了理论基础和实践技巧的结合,对于从事自然语言处理和信息检索领域的研究人员和工程师来说,具有很高的参考价值。

6
(a posteriori) value of the data-generated parameters, but it also incorporates expec-
tation as another parameter estimate as well as variance information as a measure of
estimation quality or confidence. The main step in this approach is the calculation of
the posterior according to Bayes’ rule:
p(ϑ|X) =
p(X|ϑ) · p(ϑ)
p(X)
. (18)
As we do not restrict the calculation to finding a maximum, it is necessary to calculate
the normalisation term, i.e., the probability of the “evidence”, p(X), in Eq. 18. Its value
can be expressed by the total probability w.r.t. the parameters
7
:
p(X) =
Z
ϑ∈Θ
p(X|ϑ) p(ϑ) dϑ. (19)
As new data are observed, the posterior in Eq. 18 is automatically adjusted and can
eventually be analysed for its statistics. However, often the normalisation integral in
Eq. 19 is the intricate part of Bayesian inference, which will be treated further below.
In the prediction problem, the Bayesian approach extends MAP by ensuring an
exact equality in Eq. 14, which then becomes:
p( ˜x|X) =
Z
ϑ∈Θ
p( ˜x|ϑ) p(ϑ|X) dϑ (20)
=
Z
ϑ∈Θ
p( ˜x|ϑ)
p(X|ϑ)p(ϑ)
p(X)
dϑ (21)
Here the posterior p(ϑ|X) replaces an explicit calculation of parameter values ϑ. By
integration over ϑ, the prior belief is automatically incorporated into the prediction,
which itself is a distribution over ˜x and can again be analysed w.r.t. confidence, e.g., via
its variance.
As an example, we build a Bayesian estimator for the above situation of having N
Bernoulli observations and a prior belief that is expressed by a beta distribution with
parameters (5, 5), as in the MAP example. In addition to the maximum a posteriori
value, we want the expected value of the now-random parameter p and a measure of
estimation confidence. Including the prior belief, we obtain
8
:
p(p|C, α, β) =
Q
N
i=1
p(C=c
i
|p) p(p|α, β)
R
1
0
Q
N
i=1
p(C=c
i
|p) p(p|α, β) dp
(22)
=
p
n
(1)
(1 − p)
n
(0)
1
B(α,β)
p
α−1
(1 − p)
β−1
Z
(23)
=
p
[n
(1)
+α]−1
(1 − p)
[n
(0)
+β]−1
B(n
(1)
+ α, n
(0)
+ β)
(24)
= Beta(p|n
(1)
+ α, n
(0)
+ β) (25)
7
This marginalisation is why evidence is also refered to as “marginal likelihood”. The integral
is used here as a generalisation for continuous and discrete sample spaces, where the latter
require sums.
8
The marginal likelihood Z in the denominator is simply determined by the normalisation con-
straint of the beta distribution.
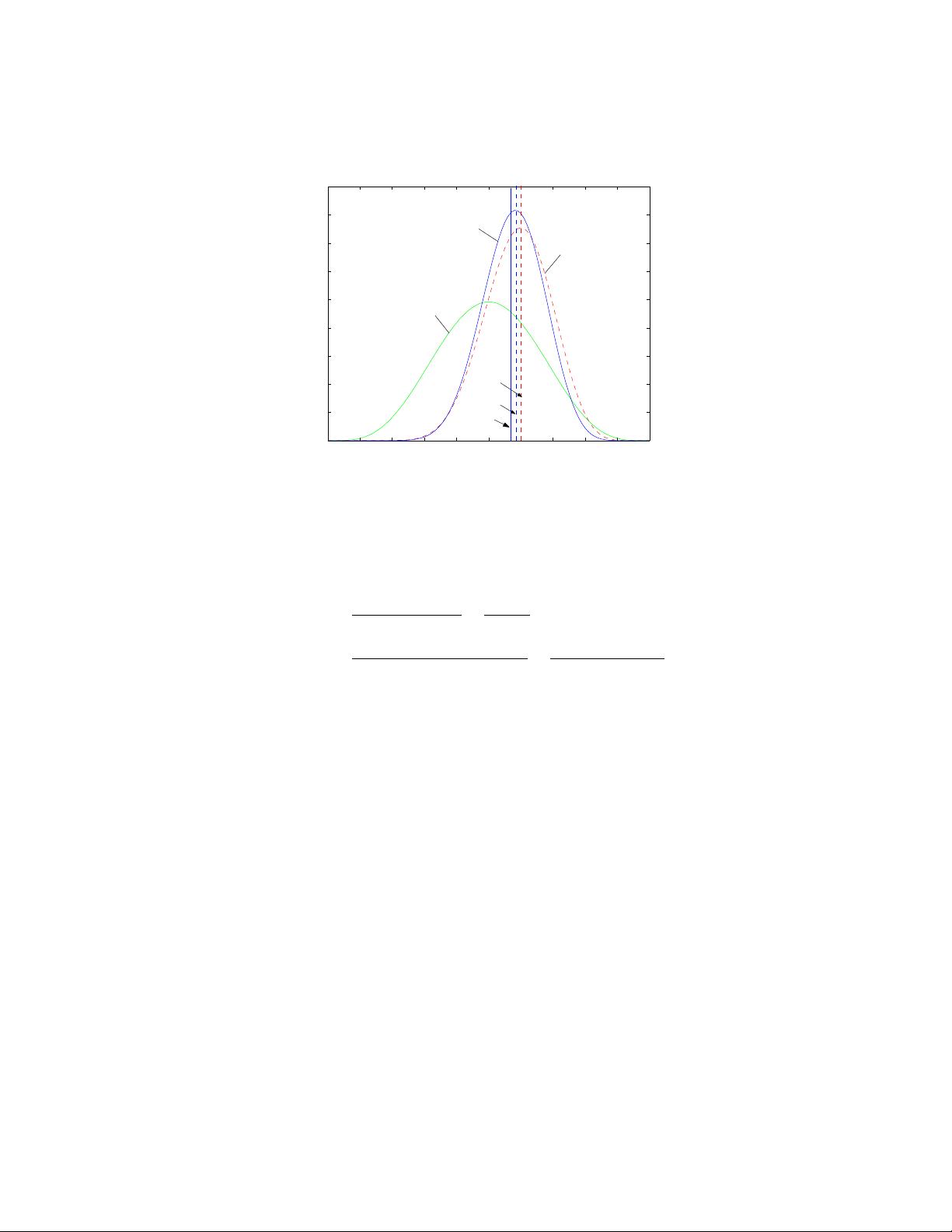
n(1):事件1发生的次数
n(0):事件0发生的次数
这里是一个posteriori分布,和
prior的分布属于同一个分布,都
是beta分布
这里只是算出了概率密度函数
剩余31页未读,继续阅读
115 浏览量
133 浏览量
346 浏览量
251 浏览量
MATLAB Normal Distribution Parameter Estimation: Unveiling the Distribution Patterns Behind the Data
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

athreading
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- VC++挂机锁功能源码解析与下载
- 织梦公司企业通用HTML项目资源包介绍
- Flat-UI:Bootstrap风格的扁平化前端框架
- 打造高效动态的JQuery横向纵向菜单
- 掌握cmd命令:Windows系统下的命令提示符操作指南
- 在Linux系统中实现FTP客户端与服务器的C语言编程教程
- Ubuntu Budgie桌面环境安装全攻略:一键部署
- SAS9.2完整教程:掌握程序与数据集操作
- 精英K8M800-M2主板BIOS更新指南
- OkSocket:Android平台上的高效Socket通信框架
- 使用android SurfaceView绘制人物动画示例
- 提升效率的桌面快捷方式管理工具TurboLaunch
- 掌握AJAX与jQuery技术的全面指南
- Pandora-Downloader:结合Flask实现Pandora音乐下载及管理
- 基于RNN的Twitter情感预测模型:英文推文情绪分析
- 使用Python脚本合并具有相同前缀的PDF文件
