
SSD: Single Shot MultiBox Detector 3
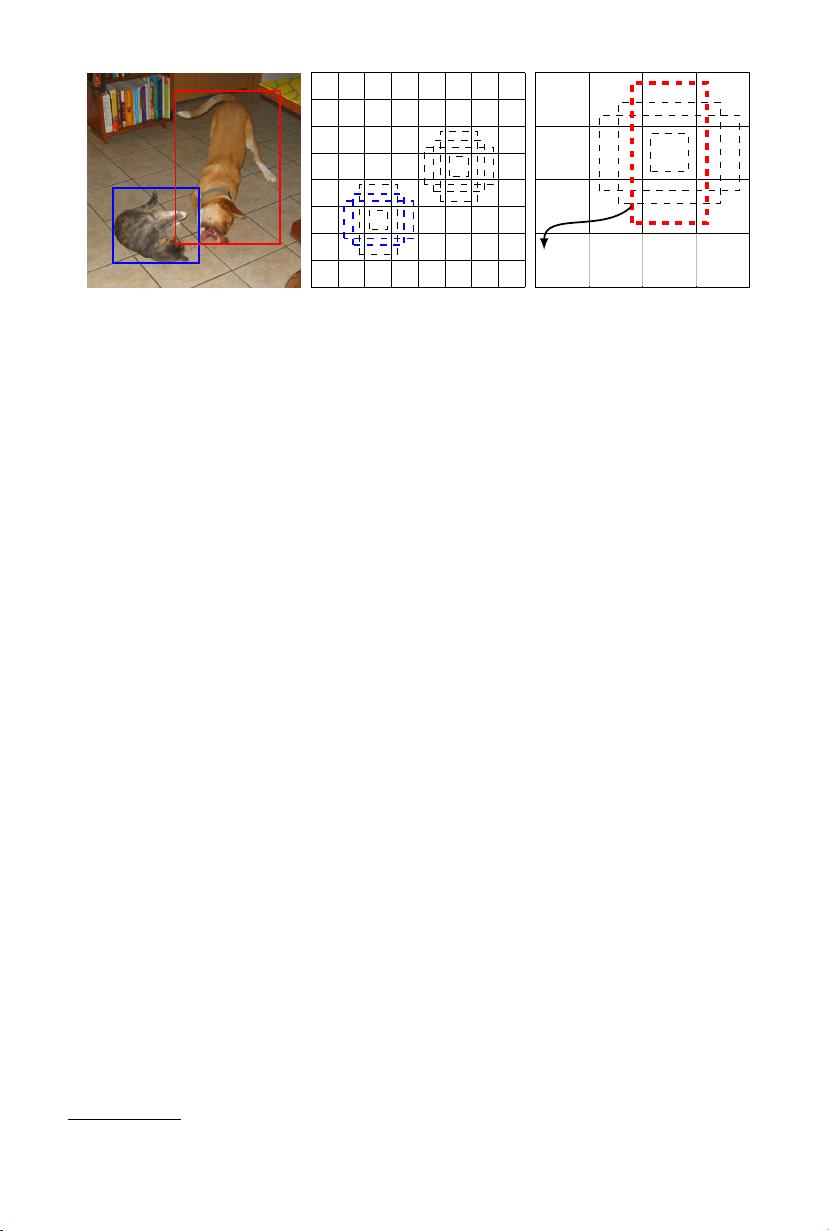
(a) Image with GT b oxes
(b) 8 × 8 feature map (c) 4 × 4 feature map
loc : ∆(cx, cy, w, h)
conf : (c
1
, c
2
, ···, c
p
)
Fig. 1: SSD framework. (a) SSD only needs an input image and ground truth boxes for
each object during training. In a convolutional fashion, we evaluate a small set (e.g. 4)
of default boxes of different aspect ratios at each location in several feature maps with
different scales (e.g. 8 × 8 and 4 × 4 in (b) and (c)). For each default box, we predict
both the shape offsets and the confidences for all object categories ((c
1
, c
2
, ··· , c
p
)).
At training time, we first match these default boxes to the ground truth boxes. For
example, we have matched two default boxes with the cat and one with the dog, which
are treated as positives and the rest as negatives. The model loss is a weighted sum
between localization loss (e.g. Smooth L1 [6]) and confidence loss (e.g. Softmax).
2.1 Model
The SSD approach is based on a feed-forward convolutional network that produces
a fixed-size collection of bounding boxes and scores for the presence of object class
instances in those boxes, followed by a non-maximum suppression step to produce the
final detections. The early network layers are based on a standard architecture used for
high quality image classification (truncated before any classification layers), which we
will call the base network
1
. We then add auxiliary structure to the network to produce
detections with the following key features:
Multi-scale feature maps for detection We add convolutional feature layers to the end
of the truncated base network. These layers decrease in size progressively and allow
predictions of detections at multiple scales. The convolutional model for predicting
detections is different for each feature layer (cf Overfeat[4] and YOLO[5] that operate
on a single scale feature map).
Convolutional predictors for detection Each added feature layer (or optionally an ex-
isting feature layer from the base network) can produce a fixed set of detection predic-
tions using a set of convolutional filters. These are indicated on top of the SSD network
architecture in Fig. 2. For a feature layer of size m × n with p channels, the basic el-
ement for predicting parameters of a potential detection is a 3 × 3 × p small kernel
that produces either a score for a category, or a shape offset relative to the default box
1
In our reported experiments we use the VGG-16 network as a base, but other networks should
also produce good results.
剩余14页未读,继续阅读

pylkaoyan2
- 粉丝: 1
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建Cadence PSpice仿真模型库教程
- VMware 10.0安装指南:步骤详解与网络、文件共享解决方案
- 中国互联网20周年必读:影响行业的100本经典书籍
- SQL Server 2000 Analysis Services的经典MDX查询示例
- VC6.0 MFC操作Excel教程:亲测Win7下的应用与保存技巧
- 使用Python NetworkX处理网络图
- 科技驱动:计算机控制技术的革新与应用
- MF-1型机器人硬件与robobasic编程详解
- ADC性能指标解析:超越位数、SNR和谐波
- 通用示波器改造为逻辑分析仪:0-1字符显示与电路设计
- C++实现TCP控制台客户端
- SOA架构下ESB在卷烟厂的信息整合与决策支持
- 三维人脸识别:技术进展与应用解析
- 单张人脸图像的眼镜边框自动去除方法
- C语言绘制图形:余弦曲线与正弦函数示例
- Matlab 文件操作入门:fopen、fclose、fprintf、fscanf 等函数使用详解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


