DKRL:无监督语义分析中的术语嵌入与分类构建方法
需积分: 19 72 浏览量
更新于2024-09-09
收藏 1.11MB PDF 举报
DKRL(Description Knowledge Representation Learning)是一种用于自然语言处理(NLP)的模型,特别关注零样本学习(zero-shot learning),它旨在通过结合描述信息来改进和增强语义分析中的知识表示。在传统的基于模式的方法中,它们主要通过识别超nym-hyponym术语对并将其组织成一个分类体系来构建词典或概念图谱。然而,这些方法往往将每个术语视为独立的概念节点,忽视了主题相关性和上下文关联的重要性。
DKRL模型旨在克服这一局限性,它通过自适应的术语嵌入(adaptive term embedding)技术,捕捉到词汇之间的潜在语义关系,尤其是那些主题相关的联系。这种方法利用深度学习的潜在能力,比如强化学习(Reinforcement Learning,RL)或者潜在的表示学习,来动态地学习和调整术语之间的相似度,从而更准确地反映文本数据中的主题结构。
在TaxoGen这一具体应用中,研究人员Chao Zhang、Fangbo Tao等人提出了一种无监督的税收分类学构建方法,无需预先标记的训练数据。它结合了聚类技术,如词向量的聚类,以及适应性术语嵌入,使得模型能够在理解词语在文档集合中的上下文含义的基础上,自动发现和组织术语之间的层级关系,进而形成一个更为丰富和精细的词典或主题分类。
这种方法的优势在于提高了知识表示的效率和有效性,使得零样本模型能够更好地理解和处理新的、未见过的数据。这对于信息过滤、推荐系统以及Web搜索等应用场景具有重要意义,因为它们需要快速适应和理解新出现的主题和概念,而DKRL提供了这样的能力。
总结来说,DKRL是一种结合描述信息和强化学习的技术,用于改善自然语言处理中的知识图谱构建,通过自适应术语嵌入和聚类策略,解决了传统方法在捕捉主题相关性和零样本学习方面的不足,对于提升文本数据分析的精确度和实用性有着显著贡献。
TaxoGen: Unsupervised Topic Taxonomy Construction by
Adaptive Term Embedding and Clustering
Chao Zhang
1
, Fangbo Tao
2
, Xiusi Chen
3
, Jiaming Shen
1
, Meng Jiang
4
,
Brian Sadler
5
, Michelle Vanni
5
, and Jiawei Han
1
1
Dept. of Computer Science, University of Illinois at Urbana-Champaign, Urbana, IL, USA
2
Facebook Inc., Menlo Park, CA, USA
3
Dept. of Computer Science and Technology, Peking University, Beijing, China
4
Dept. of Computer Science and Engineering, University of Notre Dame, Notre Dame, IN, USA
5
U.S. Army Research Laboratory, Adelphi, MD, USA
1
{czhang82, js2, hanj}@illinois.edu
2
fangbo.tao@gmail.com
3
xiusi0721@gmail.com
4
mjiang2@nd.edu
5
{brian.m.sadler6.civ, michelle.t.vanni.civ}@mail.mil
ABSTRACT
Taxonomy construction is not only a fundamental task for semantic
analysis of text corpora, but also an important step for applications
such as information ltering, recommendation, and Web search.
Existing pattern-based methods extract hypernym-hyponym term
pairs and then organize these pairs into a taxonomy. However, by
considering each term as an independent concept node, they over-
look the topical proximity and the semantic correlations among
terms. In this paper, we propose a method for constructing topic
taxonomies, wherein every node represents a conceptual topic and
is dened as a cluster of semantically coherent concept terms. Our
method, TaxoGen, uses term embeddings and hierarchical cluster-
ing to construct a topic taxonomy in a recursive fashion. To ensure
the quality of the recursive process, it consists of: (1) an adaptive
spherical clustering module for allocating terms to proper levels
when splitting a coarse topic into ne-grained ones; (2) a local
embedding module for learning term embeddings that maintain
strong discriminative power at dierent levels of the taxonomy. Our
experiments on two real datasets demonstrate the eectiveness of
TaxoGen compared with baseline methods.
ACM Reference Format:
Chao Zhang
1
, Fangbo Tao
2
, Xiusi Chen
3
, Jiaming Shen
1
, Meng Jiang
4
, Brian
Sadler
5
, Michelle Vanni
5
, and Jiawei Han
1
. 2018. TaxoGen: Unsupervised
Topic Taxonomy Construction by Adaptive Term Embedding and Clustering.
In KDD 2018: 24th ACM SIGKDD International Conference on Knowledge
Discovery & Data Mining, August 19–23, 2018, London, United Kingdom.
ACM, New York, NY, USA, 9 pages. https://doi.org/10.1145/3219819.3220064
1 INTRODUCTION
Automatic taxonomy construction from a text corpus is a fundamen-
tal task for semantic analysis of text data and plays an important
role in many applications. For example, organizing a massive news
Permission to make digital or hard copies of all or part of this work for personal or
classroom use is granted without fee provided that copies are not made or distributed
for prot or commercial advantage and that copies bear this notice and the full citation
on the rst page. Copyrights for components of this work owned by others than ACM
must be honored. Abstracting with credit is permitted. To copy otherwise, or republish,
to post on servers or to redistribute to lists, requires prior specic permission and/or a
fee. Request permissions from permissions@acm.org.
KDD 2018, August 19–23, 2018, London, United Kingdom
© 2018 Association for Computing Machinery.
ACM ISBN 978-1-4503-5552-0/18/08.. . $15.00
https://doi.org/10.1145/3219819.3220064
Computer Science
computer_science
computation_time
algorithm
computation
computation_approach
Information Retrieval
information_retrieval
ir
information_filtering
text_retrieval
retrieval_effectiveness
…
…
Machine Learning
machine_learning
learning_algorithms
clustering
reinforcement_learning
classification
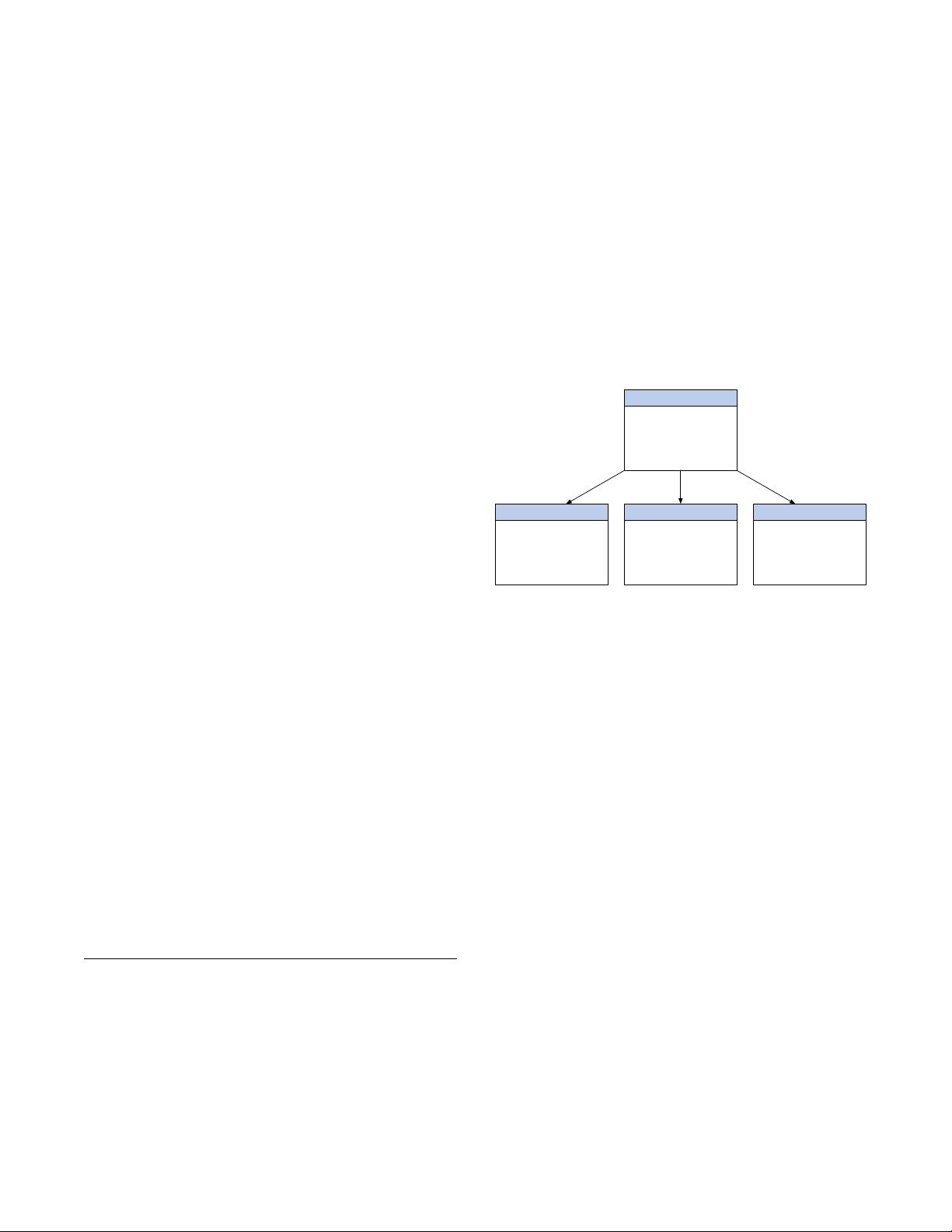
Figure 1: An example topic taxonomy. Each node is a clus-
ter of semantically coherent concept terms representing a
conceptual topic.
corpus into a well-structured taxonomy allows users to quickly
navigate to their interested topics and easily acquire useful infor-
mation. As another example, many recommender systems involve
items with textual descriptions, and a taxonomy for these items
can help the system better understand user interests to make more
accurate recommendations [32].
Existing methods mostly generate a taxonomy wherein each
node is a single term representing an independent concept [
13
,
18
].
They use pre-dened lexico-syntactic patterns (e.g., A such as B,
A is a B) to extract hypernym-hyponym term pairs, and then or-
ganize these pairs into a concept taxonomy by considering each
term as a node. Although they can achieve high precision for the
extracted hypernym-hyponym pairs, considering each term as an
independent concept node causes three critical problems to the
taxonomy: (1) low coverage: Since term correlations are not con-
sidered, only the pairs exactly matching the pre-dened patterns
are extracted, which leads to low coverage of the result taxonomy.
(2) high redundancy: As one concept can be expressed in dierent
ways, the taxonomy is highly redundant because many nodes are
just dierent expressions of the same concept (e.g., ‘information
retrieval’ and ‘ir’). (3) limited informativeness: Representing a node
with a single term provides limited information about the concept
and causes ambiguity.
下载后可阅读完整内容,剩余8页未读,立即下载
2019-08-09 上传
2018-10-25 上传
2023-05-26 上传
2023-05-11 上传
2023-02-15 上传
2023-04-11 上传
2023-03-16 上传
2023-07-08 上传
2023-04-23 上传

BlueblueblueBLUEFLY
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 李兴华Java基础教程:从入门到精通
- U盘与硬盘启动安装教程:从菜鸟到专家
- C++面试宝典:动态内存管理与继承解析
- C++ STL源码深度解析:专家级剖析与关键技术
- C/C++调用DOS命令实战指南
- 神经网络补偿的多传感器航迹融合技术
- GIS中的大地坐标系与椭球体解析
- 海思Hi3515 H.264编解码处理器用户手册
- Oracle基础练习题与解答
- 谷歌地球3D建筑筛选新流程详解
- CFO与CIO携手:数据管理与企业增值的战略
- Eclipse IDE基础教程:从入门到精通
- Shell脚本专家宝典:全面学习与资源指南
- Tomcat安装指南:附带JDK配置步骤
- NA3003A电子水准仪数据格式解析与转换研究
- 自动化专业英语词汇精华:必备术语集锦
