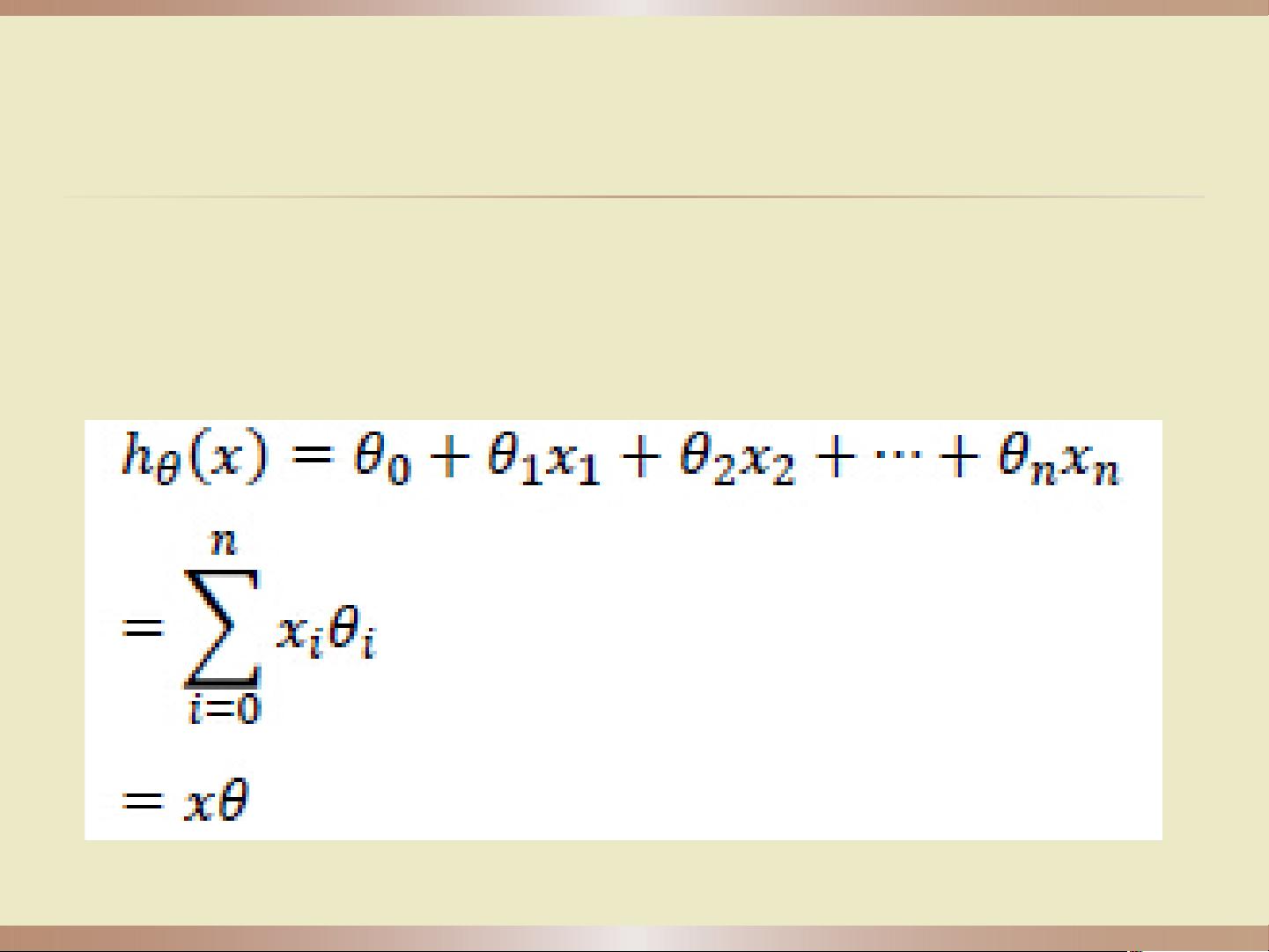梯度下降法是一种广泛应用在机器学习和优化问题中的算法,它通过沿着目标函数(如风险或损失函数)的负梯度方向调整参数,以逐步降低函数值,从而找到局部或全局最优解。本文档主要关注梯度下降法的三种形式:批量梯度下降(BGD)、随机梯度下降(SGD)和小批量梯度下降(MBGD)。
首先,我们从一元线性回归开始介绍,这是一种基本的预测模型,假设数据可以用线性关系y = kx + b来近似。在这个背景下,我们需要求解参数θ(包括θ0和θ1)来最小化误差,通常使用2-范数作为损失函数。批量梯度下降的目标是通过迭代更新参数,使得误差函数J(θ)减小,直到达到预设的收敛条件。
在批量梯度下降中,每一步更新都是基于所有训练样本的梯度平均,这可能导致计算量大,尤其是在大规模数据集上。更新公式显示,它能找到全局最优解,但效率不高。相比之下,随机梯度下降(SGD)在每次迭代时只使用一个或一小部分随机样本的梯度,因此计算速度更快,但可能会陷入局部最优。SGD的收敛图通常表现出迭代次数较多,但总体上速度较快的特点。
小批量梯度下降(MBGD)介于两者之间,它取批量梯度下降的全局优化性和随机梯度下降的高效性,每次更新使用一小部分随机选择的样本,既降低了计算复杂度,又提高了收敛速度。这种折衷方法在实际应用中很常见。
总结来说,梯度下降法是机器学习基础的重要组成部分,理解其原理和不同形式的优缺点对于优化模型训练至关重要。在实际项目中,根据数据规模、计算资源和性能需求,选择合适的梯度下降变种是提高模型性能的关键步骤。