Spark架构解析:Master、Worker与Executor的协同
需积分: 12 172 浏览量
更新于2024-07-18
收藏 15.72MB PDF 举报
"本文档主要解析Spark的核心原理,包括系统架构、执行计划、Shuffle过程、缓存与checkpoint机制以及广播变量等内容。文档以中文形式详细阐述,适合对Spark感兴趣的读者深入学习。"
在Spark系统中,部署是整个流程的第一步。Spark集群由Master节点和Worker节点组成,类似于Hadoop的Master和Slave结构。Master节点上运行Master守护进程,其职责是监控和管理所有的Worker节点。而Worker节点则运行Worker守护进程,这些进程与Master节点通信,并且负责管理Executor的生命周期。
Driver程序是应用程序的主入口点,即运行main()函数的部分,它创建SparkContext对象。在不同的运行模式下,Driver的位置有所不同。例如,如果在Master节点上运行示例应用,如`./bin/run-example SparkPi 10`,那么SparkPi就是Master上的Driver。在YARN集群环境中,Driver可能会被调度到任意一个Worker节点上运行。而在本地开发环境中,如Eclipse,可以直接运行Driver程序,但这样做可能导致Driver与Executor之间的网络通信效率低下,因为它们可能不在同一网络环境中。
每个Spark应用包含一个Driver和多个Executor。Executor是由Driver分配的任务执行器,它们在一个或多个ExecutorBackend进程中运行。ExecutorBackend在Standalone模式下通常是CoarseGrainedExecutorBackend,每个Executor拥有一个线程池,每个线程可以并行执行一个Task。
在Spark的逻辑执行计划中,JobLogicalPlan描述了任务的高级计算逻辑,它被转化为JobPhysicalPlan,这个物理执行计划包含了实际的数据处理操作和数据传输策略。ShuffleDetails部分则详细讲解了在数据处理过程中,如何通过Shuffle操作重新组织数据,以满足不同Stage之间的依赖。
CacheAndCheckpoint机制是Spark优化性能的重要手段。通过缓存中间结果到内存或磁盘,可以避免重复计算,提高整体效率。而Checkpoint则用于持久化RDD(弹性分布式数据集),即使在故障情况下,也能从已保存的状态恢复,确保容错性。
Broadcast机制在Spark中用于高效地分发大型静态数据到集群的每个节点,减少网络传输开销。每个节点只需接收一次广播变量,然后在本地存储,多次使用时直接从本地读取,提高了大规模数据处理的效率。
这个文档全面解析了Spark的核心组件和工作流程,对于理解和优化Spark应用的性能具有很高的参考价值。
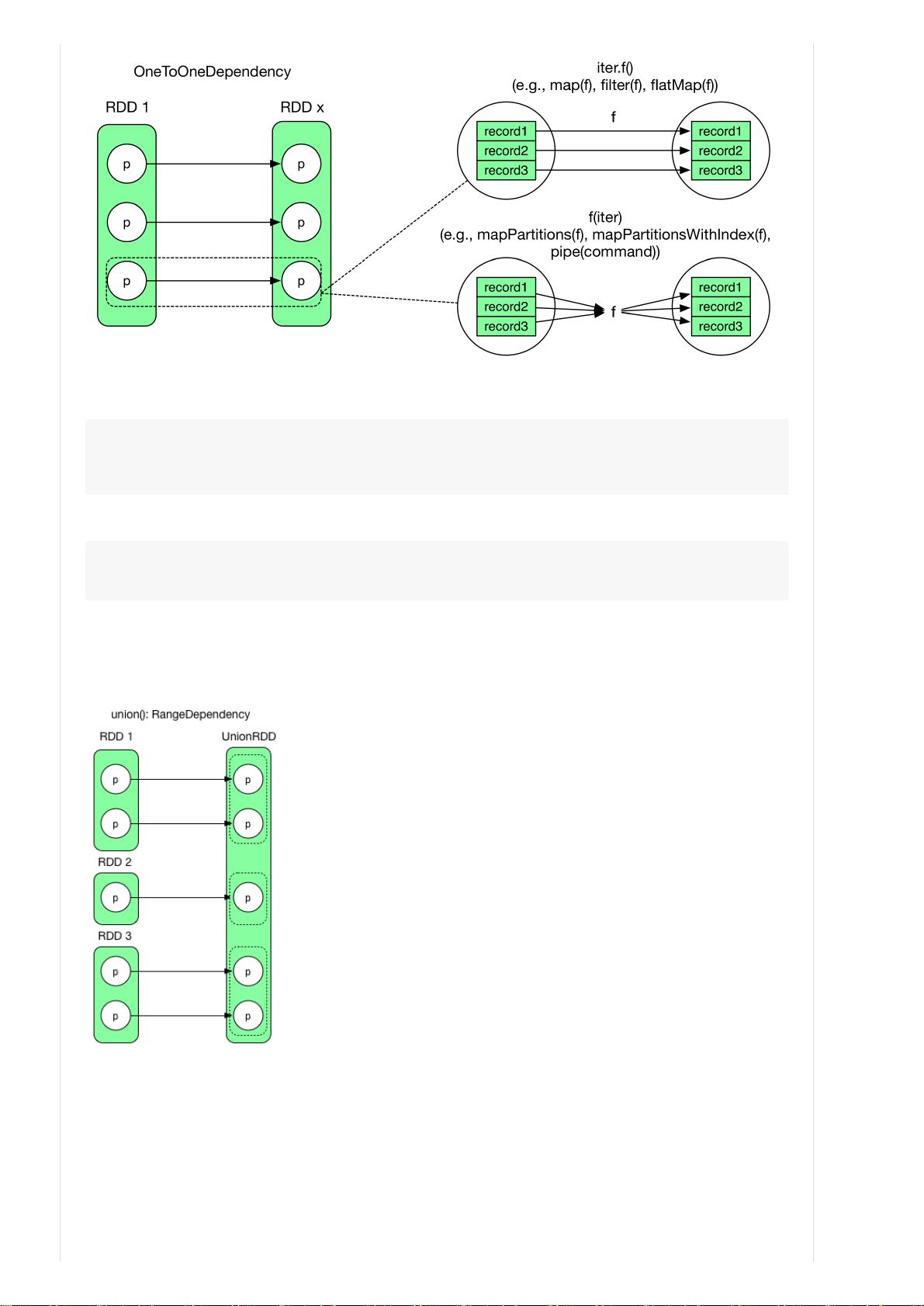
code1 of iter.f()
int[]array={1,2,3,4,5}
for(inti=0;i<array.length;i++)
f(array[i])
code2 of f(iter)
int[]array={1,2,3,4,5}
f(array)
1) union(otherRDD)
union() 将两个 RDD 简单合并在一起,不改变 partition 里面的数据。RangeDependency 实际上也是 1:1,只是为了访问
union() 后的 RDD 中的 partition 方便,保留了原始 RDD 的 range 边界。
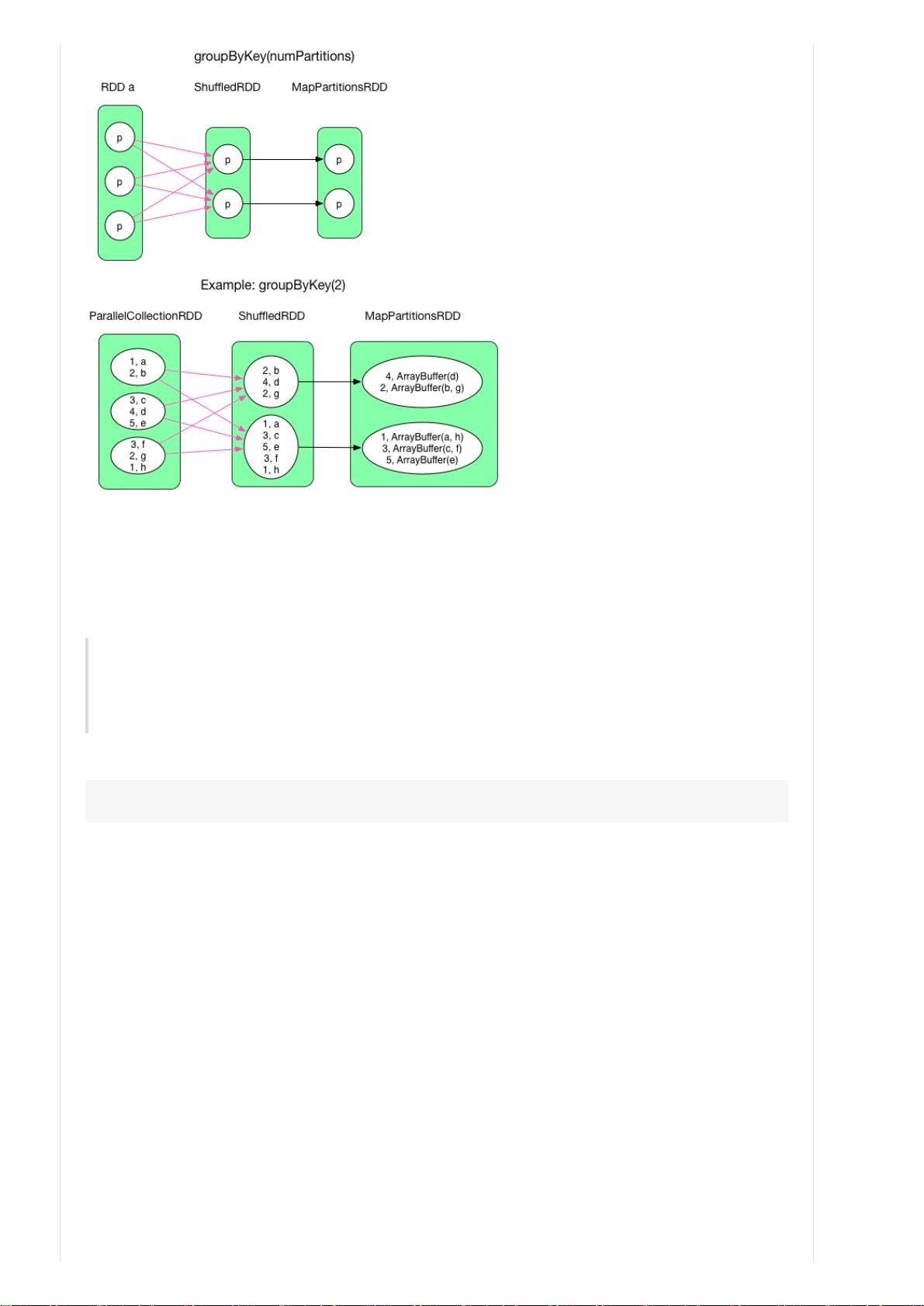
2) groupByKey(numPartitions)
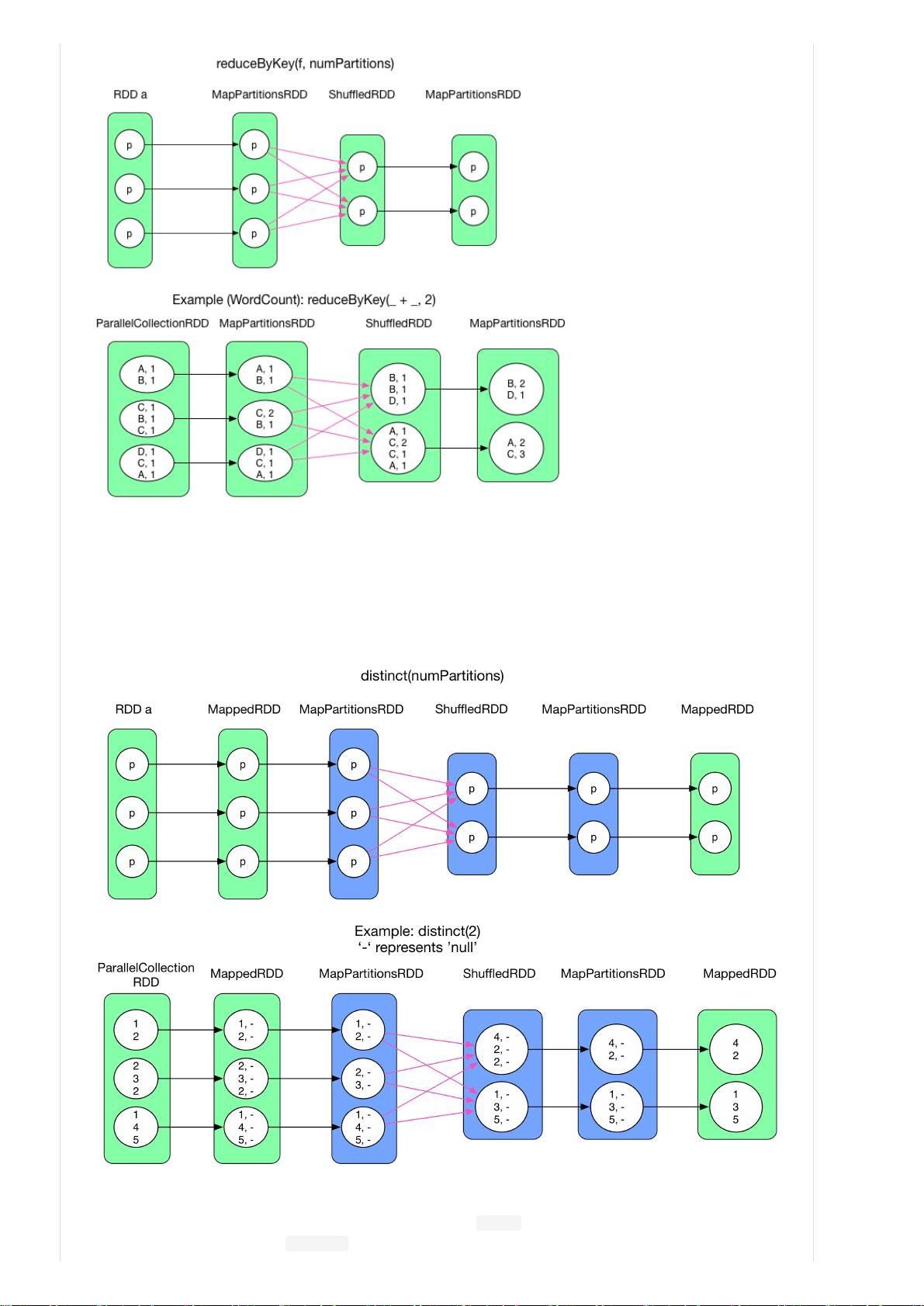
3. 给出一些典型的 transformation() 的计算过程及数据依赖图
剩余58页未读,继续阅读
2018-03-28 上传
2016-03-01 上传
2018-12-01 上传
2018-12-01 上传
2019-12-13 上传
2022-03-16 上传
点击了解资源详情

shixuexeon
- 粉丝: 17
- 资源: 54
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python中快速友好的MessagePack序列化库msgspec
- 大学生社团管理系统设计与实现
- 基于Netbeans和JavaFX的宿舍管理系统开发与实践
- NodeJS打造Discord机器人:kazzcord功能全解析
- 小学教学与管理一体化:校务管理系统v***
- AppDeploy neXtGen:无需代理的Windows AD集成软件自动分发
- 基于SSM和JSP技术的网上商城系统开发
- 探索ANOIRA16的GitHub托管测试网站之路
- 语音性别识别:机器学习模型的精确度提升策略
- 利用MATLAB代码让古董486电脑焕发新生
- Erlang VM上的分布式生命游戏实现与Elixir设计
- 一键下载管理 - Go to Downloads-crx插件
- Java SSM框架开发的客户关系管理系统
- 使用SQL数据库和Django开发应用程序指南
- Spring Security实战指南:详细示例与应用
- Quarkus项目测试展示柜:Cucumber与FitNesse实践
