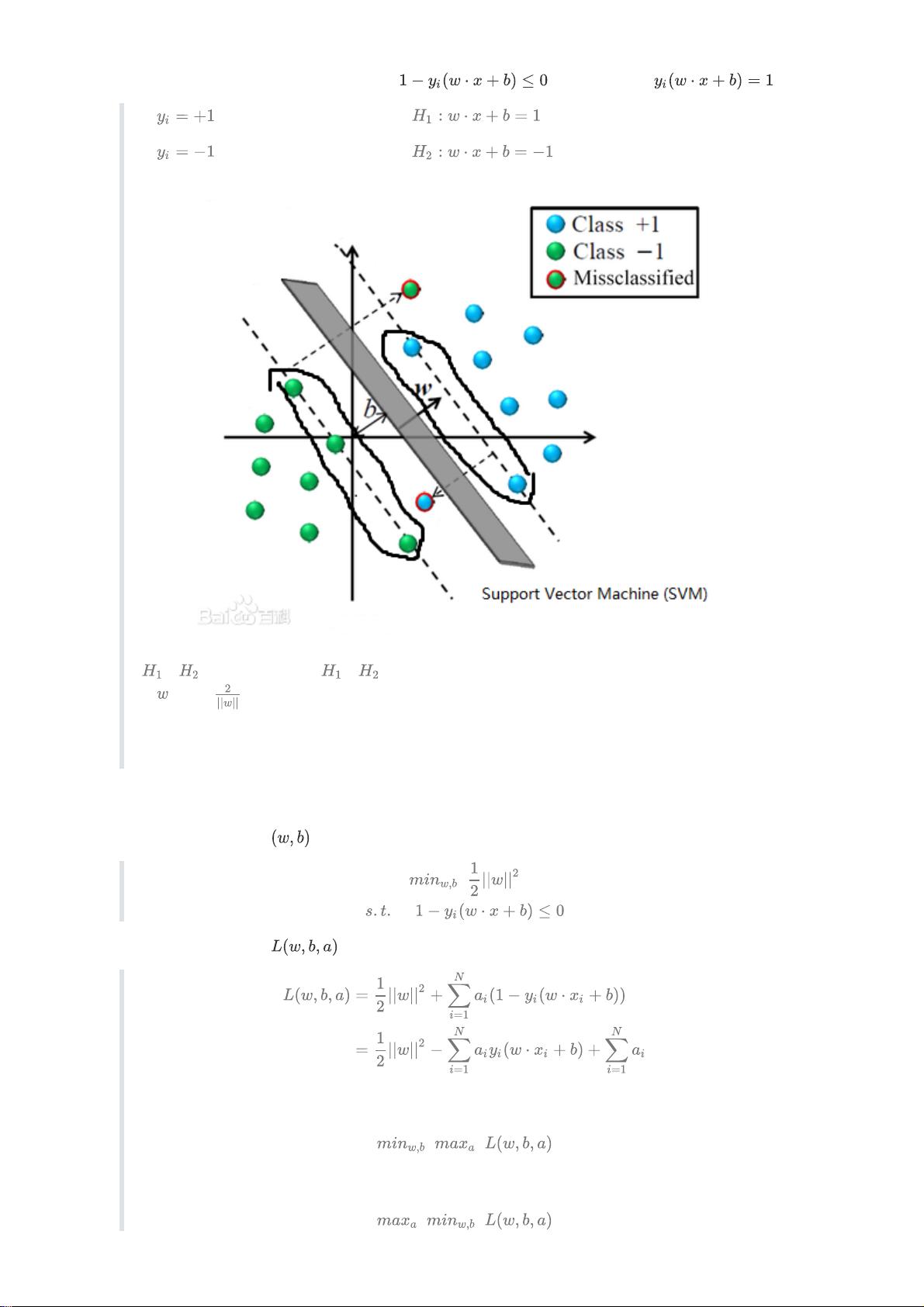
SVM(支持向量机)是一种强大的机器学习算法,特别适用于处理线性和非线性分类问题。本文档深入探讨了支持向量机的基本概念,重点介绍了线性可分情况下的SVM。在给定训练数据
\[ \{(x_1, y_1), (x_2, y_2), ..., (x_n, y_n)\} \]
中,SVM的目标是找到一个超平面 \( w \cdot x + b = 0 \),其中 \( w \) 是法向量,\( b \) 是偏置项,能将不同类别的样本点 \( x_i \) 根据标签 \( y_i \) (通常为{-1, 1})分开,同时最大化分类的“间隔”。
间隔有两种类型:函数间隔和几何间隔。函数间隔 \( \Delta_i \) 表示样本点 \( x_i \) 到超平面的距离,用 \( |w \cdot x_i + b| \) 表示,它反映了分类的准确性和确信度。而几何间隔 \( d_i \) 是样本点到最近分类边界的距离,它不随 \( w \) 的缩放而变化,有助于找到具有最大间隔的最优分类边界。
对于线性可分数据,间隔最大化问题可以通过凸二次规划解决,寻找的是几何间隔最大化的超平面,即所谓的最大间隔分离超平面。这相当于解决以下优化问题:
\[
\begin{align*}
\max_{w, b} & \quad \frac{1}{2} w^T w \\
\text{s.t.} & \quad y_i(w \cdot x_i + b) \geq 1 \quad \text{for all } i=1,2,...,n \\
& \quad w \cdot x_j \geq 1 - \epsilon \quad \text{for support vectors } j \\
\end{align*}
\]
这里的 \( \epsilon \) 代表允许的误分类容忍度,即部分样本点可能距离分类边界的距离小于1,但不超过 \( \epsilon \)。当 \( \epsilon \) 趋近于0时,问题转化为硬间隔最大化,即严格要求所有样本点被正确分类。
SMO(Sequential Minimal Optimization)算法在此优化问题中发挥关键作用,它是一种迭代方法,通过局部搜索的方式在高维空间中逐步更新超平面,直到达到全局最优。Python实现SMO算法通常涉及矩阵运算、梯度下降和双线性核函数等技巧,能够有效地处理大规模数据集,并找到最合适的分类决策函数。
本文档通过理论阐述和Python代码示例,详细介绍了SVM的原理,特别是SMO算法如何处理线性可分问题,以及如何通过间隔最大化选择最优超平面,这对于理解和应用SVM技术具有重要的参考价值。