
数据挖掘实战数据挖掘实战–二手车交易价格预测(二)数据探索性分析(二手车交易价格预测(二)数据探索性分析(EDA))
包的安装:
采用Anaconda 3进行代码的编译,Anaconda 3里基础的数据分析包都已经准备好,我们需要安装的就是sklearn,lightgbm和xgboost包。
Anaconda可以支持我们采取多种方式安装所需要的包。可以采用pip,conda和从PYPI下载相关包等方式。这里采用的是pip方式。
pip install scikit-learn
pip install lightgbm
pip install xgboost
因为之前一直在进行Arcpy的开发工作,因此我电脑里装配的是Anaconda 2 32位,这在安装lightgbm和xgboost的过程中遇到了错误。因此又安装了
Anaconda 3 64位版本。同队的韩哥也遇到了报错的问题,似乎是因为pip的版本不够新,需要升级后再安装。
数据加载与查看数据加载与查看
首先我们需要将已有的数据读进内存里,
import pandas as pd
import numpy as np
import warnings
#为了防止没有维护的包弹警告,可以在这里过滤掉警告
warnings.filterwarnings('ignore')
#在Jupyter里,可能会对过多的列进行隐藏, 如果想要查看全部的列,可以设置max_columns
pd.set_option('display.max_columns', None)
train_df = pd.read_csv('D:/DataMining/Train Data/used_car_train_20200313.csv', sep=' ')
print(train_df.shape)
train_df.describe()
train_df.head()
下一步来求一下空值数量,看看各个变量空值缺失的状况,如果缺失多,可以考虑在构建特证的时候剔除。
train_df.isnull().sum().sort_values(ascending=False).head()
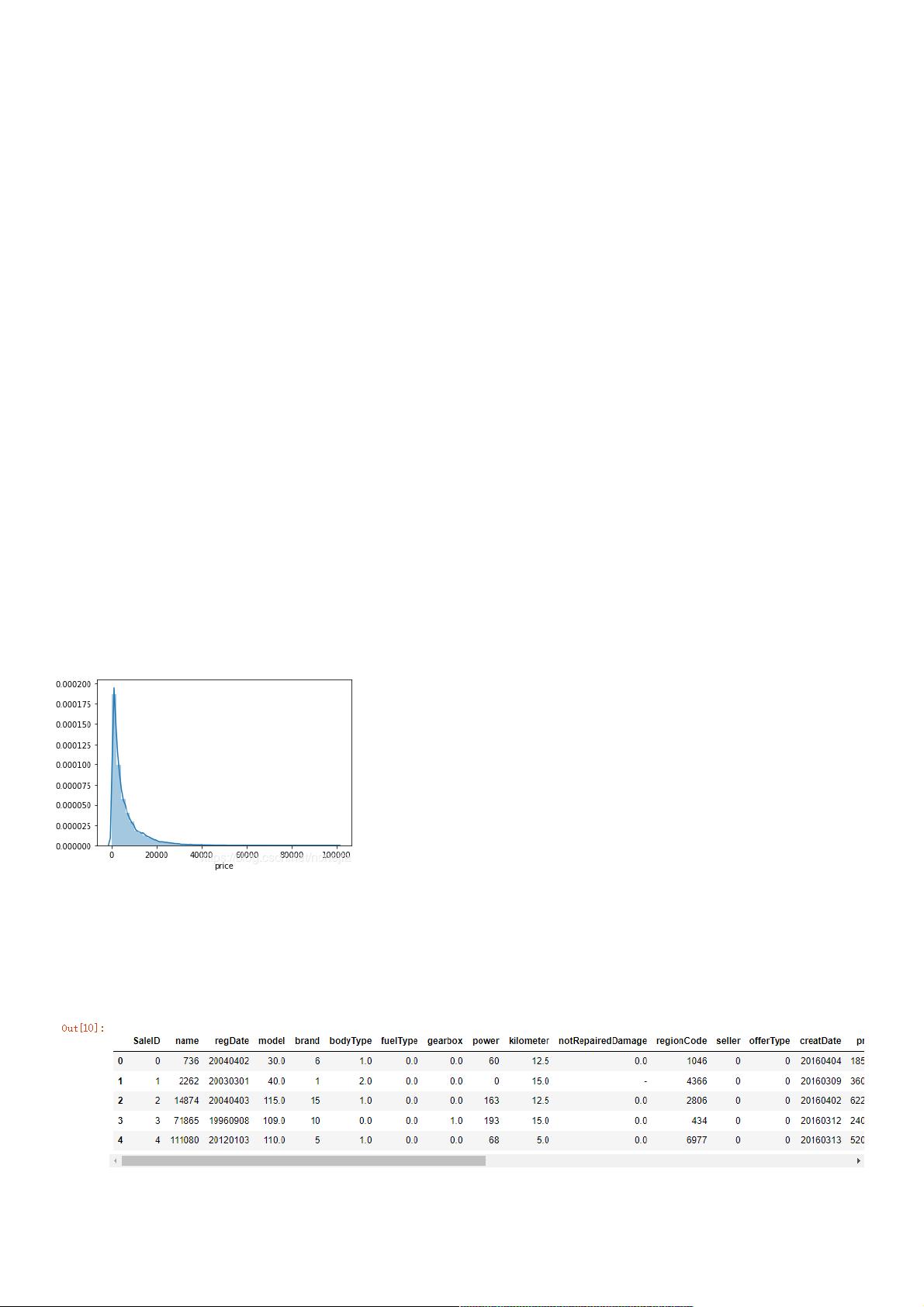
接下来看一下价格的分布
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure()
sns.distplot(train_df['price'])
plt.figure()
train_df['price'].plot.box()
plt.show()
再将测试集读进来,看一下测试集的状态。
import gc
test_df = pd.read_csv('datalab/231784/used_car_testA_20200313.csv', sep=' ')
print(test_df.shape)
df = pd.concat([train_df, test_df], axis=0, ignore_index=True)
del train_df, test_df
gc.collect()
df.head()
我们接下来可以看一下非匿名的几个可能会比较相关的数据的分布。
plt.figure()
plt.figure(figsize=(16, 6))
i = 1
for f in date_cols:

weixin_38669881
- 粉丝: 5
- 资源: 918
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 计算机系统基石:深度解析与优化秘籍
- 《ThinkingInJava》中文版:经典Java学习宝典
- 《世界是平的》新版:全球化进程加速与教育挑战
- 编程珠玑:程序员的基础与深度探索
- C# 语言规范4.0详解
- Java编程:兔子繁殖与素数、水仙花数问题探索
- Oracle内存结构详解:SGA与PGA
- Java编程中的经典算法解析
- Logback日志管理系统:从入门到精通
- Maven一站式构建与配置教程:从入门到私服搭建
- Linux TCP/IP网络编程基础与实践
- 《CLR via C# 第3版》- 中文译稿,深度探索.NET框架
- Oracle10gR2 RAC在RedHat上的安装指南
- 微信技术总监解密:从架构设计到敏捷开发
- 民用航空专业英汉对照词典:全面指导航空教学与工作
- Rexroth HVE & HVR 2nd Gen. Power Supply Units应用手册:DIAX04选择与安装指南
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


