
python datax.py /a/tmp/datax/datax.conf
java -server -Xms1g -Xmx1g
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tools/datax/log
-Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tools/datax/log
-Dloglevel=info -Dfile.encoding=UTF-8
-Dlogback.statusListenerClass=ch.qos.logback.core.status.NopStatusListener
-Djava.security.egd=file:///dev/urandom -Ddatax.home=/tools/datax
-Dlogback.configurationFile=/tools/datax/conf/logback.xml
-classpath /tools/datax/lib/*:.
-Dlog.file.name=tmp_datax_datax_conf
com.alibaba.datax.core.Engine
-mode standalone
-jobid -1
-job /a/tmp/datax/datax.conf
调用程序入口: com.alibaba.datax.core.Engine
入参: -mode standalone -jobid -1 -job /a/tmp/datax/datax.conf
调用程序入口: Engine.entry(args);
加载配置参数
解析了java命令行的三个参数,分别是job、jobid和mode,其中job是用
户配置的json文件路径,jobid和mode是python文件带进来的
ConfigParser会解析Job、Plugin、Core配置文件全部信息
读取用户配置的json文件,转化为内部的configuration配置
打印相关信息,并校验json文件的合法性
VMInfo vmInfo = VMInfo.getVmInfo();
ConfigurationValidate.doValidate(configuration);
启动
engine.start(configuration);
Engine engine = new Engine();
初始化: 绑定column转换信息 [日期函数格式,编码格式]
StringCast.init(configuration);
DateCast.init(configuration);
BytesCast.init(configuration);
初始化PluginLoader,设置pluginConfigs,方便后面插件来获取
创建 Container
1.设置运行模式: standalone ?
2.创建JobContainer
3.返回job 实例 ID: core.container.job.id = -1 ?????
启用: perfTrace , 默认 true
启用: perfReportEnable 默认值 true
注: standlone模式的datax shell任务不进行汇报
设置优先级, 默认 0
获取 job 信息
Configuration jobInfoConfig =
allConf.getConfiguration(CoreConstant.DATAX_JOB_JOBINFO);
PerfTrace 创建&初始化
启动 container
com.alibaba.datax.core.job.JobContainer#start
启动 container
jobContainer主要负责的工作全部在start()里面,包括init、prepare、split、
scheduler、 post以及destroy和statistics
1、preHandle():job前置操作
2、init():初始化reader和writer
3、prepare():执行插件的prepare操作
4、split():切分任务
5、schedule():执行任务
6、post():执行插件的post操作
7、postHandle():job后置操作
8、invokeHooks():调用hook
9、输出统计结果
执行之前是否需要进行检查
job.setting.dryRun 进行配置, 默认 false
1、preHandle():job前置操作
2、init():初始化reader和writer
3、prepare():执行插件的prepare操作
4、split():切分任务[将一个查询 sql根据 splitPk 范围切分为多个任务]
执行reader和writer最细粒度的切分,需要注意的是,writer的切分结果要参照
reader的切分结果,
达到切分后数目相等,才能满足1:1的通道模型,所以这里可以将reader和writer
的配置整合到一起,
然后,为避免顺序给读写端带来长尾影响,将整合的结果shuffler掉
4.1、计算限速和并发,即实际的channel数和每个channel的限速,主要在
adjustChannelNumber()中,这里不做过多说明
4.2、根据实际的channel数,切分reader端,具体的切分逻辑reader插件可以自行
实现
4.3、根据reader端切分的数目切分writer端,达到reader:writer=1:1,这样每
个task中都包含一个reader和一个writer
5、schedule():执行任务
5.1、计算taskGroup个数
5.2、将切分的task分配到taskGroup中
5.3、启动线程池执行taskGroup
6、post():执行插件的post操作
7、postHandle():job后置操作
8、invokeHooks():调用hook
9、输出统计结果
获取配置: job.preHandler.pluginType
配置类型如下:
READER("reader"),
TRANSFORMER("transformer"),
WRITER("writer"),
HANDLER("handler")
执行具体内容, 这个等以后用到的时候再看
1. 更新线程名字
2. 创建: DefaultJobPluginCollector
3. 初始化Reader
4. 初始化 Writer
初始化 Reader: initJobReader
创建任务收集器: JobPluginCollector
初始化 Writer: jobWriter
获取 reader 配置文件
根据插件类型和插件的名称获取jar 加载器 JarLoader
使用 JarLoader 加载各种依赖 jar : /tools/datax/plugin/reader/mysqlreader
通过反射获取 Reader.Job 实例, 加载配置并初始化
获取 writer 配置文件
根据插件类型和插件的名称获取jar 加载器 JarLoader
使用 JarLoader 加载各种依赖 jar : /tools/datax/plugin/reader/mysqlwriter
通过反射获取Writer.Job 实例, 加载配置并初始化
分别执行reader和writer插件Job中的prepare函数即可,
同样,每次执行前都会先加载对应的classLoader用于隔离
1.计算要生成多少个切片
2.计算切分数据 splitPk 的最大值和最小值
3.根据splitPk对应的 ID 范围,划分到不同的切片中.
4.根据每个切片对应的splitPk范围,生成多个 sql 语句
5.处理splitPk 值是 null 的数据, 生成一个 sql
5.返回对应的配置执行任务配置 List<Configuration>
6. writer 的任务数同 reader 的任务数量一致.
1. channelsPerTaskGroup: core.container.taskGroup.channel 默认值 5
taskNumber 为 job.content
needChannelNumber : Math.min(this.needChannelNumber, taskNumber);
2. assignFairly: 公平的分配 task 到对应的 taskGroup 中。
int taskGroupNumber = (int) Math.ceil(1.0 * channelNumber / channelsPerTaskGroup);
3. 设置任务运行模式 standalone
4. 给 taskGroupContainer 的 Communication 注册
5. 启动任务 startAllTaskGroup(configurations)
6. 根据任务组的数量,创建线程池
7. 将每个线程组的任务分装成TaskGroupContainerRunner , 交由线程池运行.
TaskGroupContainer#start
初始化
1. 设置配置文件 configuration
2. 初始化监控
3. 设置 jobId
4. 设置taskGroupId
5. 设置 channel 实例
com.alibaba.datax.core.transport.channel.memory.MemoryChannel
6. 设置架空
com.alibaba.datax.core.statistics.plugin.task.StdoutPluginCollector
start 方法
1、初始化task执行相关的状态信息,分别是taskId->Congifuration的map、
待运行的任务队列taskQueue、
运行失败任务taskFailedExecutorMap、
运行中的任务runTasks、
任务开始时间taskStartTimeMap
2、循环检测所有任务的执行状态
1)判断是否有失败的task,如果有则放入失败对立中,并查看当前的执行是否支持重跑和failOver,
如果支持则重新放回执行队列中;
如果没有失败,则标记任务执行成功,并从状态轮询map中移除
2)如果发现有失败的任务,则汇报当前TaskGroup的状态,并抛出异常
3)查看当前执行队列的长度,如果发现执行队列还有通道,则构建TaskExecutor加入执行队列,并从待运
行移除
4)检查执行队列和所有的任务状态,如果所有的任务都执行成功,则汇报taskGroup的状态并从循环中退
出
5)检查当前时间是否超过汇报时间检测,如果是,则汇报当前状态
6)当所有的执行完成从while中退出之后,再次全局汇报当前的任务状态
1. 状态check时间间隔,较短,可以把任务及时分发到对应channel中
2. 状态汇报时间间隔,稍长,避免大量汇报
3. 2分钟汇报一次性能统计
4. 获取任务配置 List<Configuration> taskConfigs
5. 构建待运行的任务队列
List<Configuration> taskQueue = buildRemainTasks(taskConfigs);
6. 开始执行任务 [while (true) 死循环]
while(true)
1.判断task状态
循环遍历所有任务, 如果任务尚未完成, 这跳过.
如果任务已经执行完成的话, 在任务列表中移除任务.
如果失败的话,看 task 是否支持重试, 并且重试次数是否超过最大限制.
如果被kill, 这设置 failedOrKilled 在下面的步骤二会跳出循环,抛出异常,程序退出.
如果执行成功, 收集任务运行信息,输出程序运行日志.
2.发现该taskGroup下taskExecutor的总状态失败则汇报错误,抛出DataXException,
程序退出.
3.有任务未执行,且正在运行的任务数小于最大通道限制
将 task 构建成构建TaskExecutor , 调用 doStart方法,执行 task
4.任务列表为空,executor已结束, 搜集状态为success--->成功
5.如果当前时间已经超出汇报时间的interval,那么我们需要马上汇报
6.最后还要汇报一次
new TaskExecutor()
创建 new WriterRunner(taskPlugin) 设置其任务信息 & 创建 writer 线程并设置类加载器
创建 new ReaderRunner(taskPlugin) 设置其任务信息 & 创建 reader 线程并设置类加载器
TaskExecutor#doStart
启动writerThread
启动readerThread
doStart()
taskWriter.init();
taskWriter.prepare();
taskWriter.startWrite(recordReceiver);
taskWriter.post();
taskWriter.destroy();
taskReader.init();
taskReader.prepare();
taskReader.startRead(recordSender);
taskReader.post();
taskReader.destroy();
缓存数据存放到队列中
MemoryChannel # ArrayBlockingQueue<Record>
存入
Record
拉取
Record
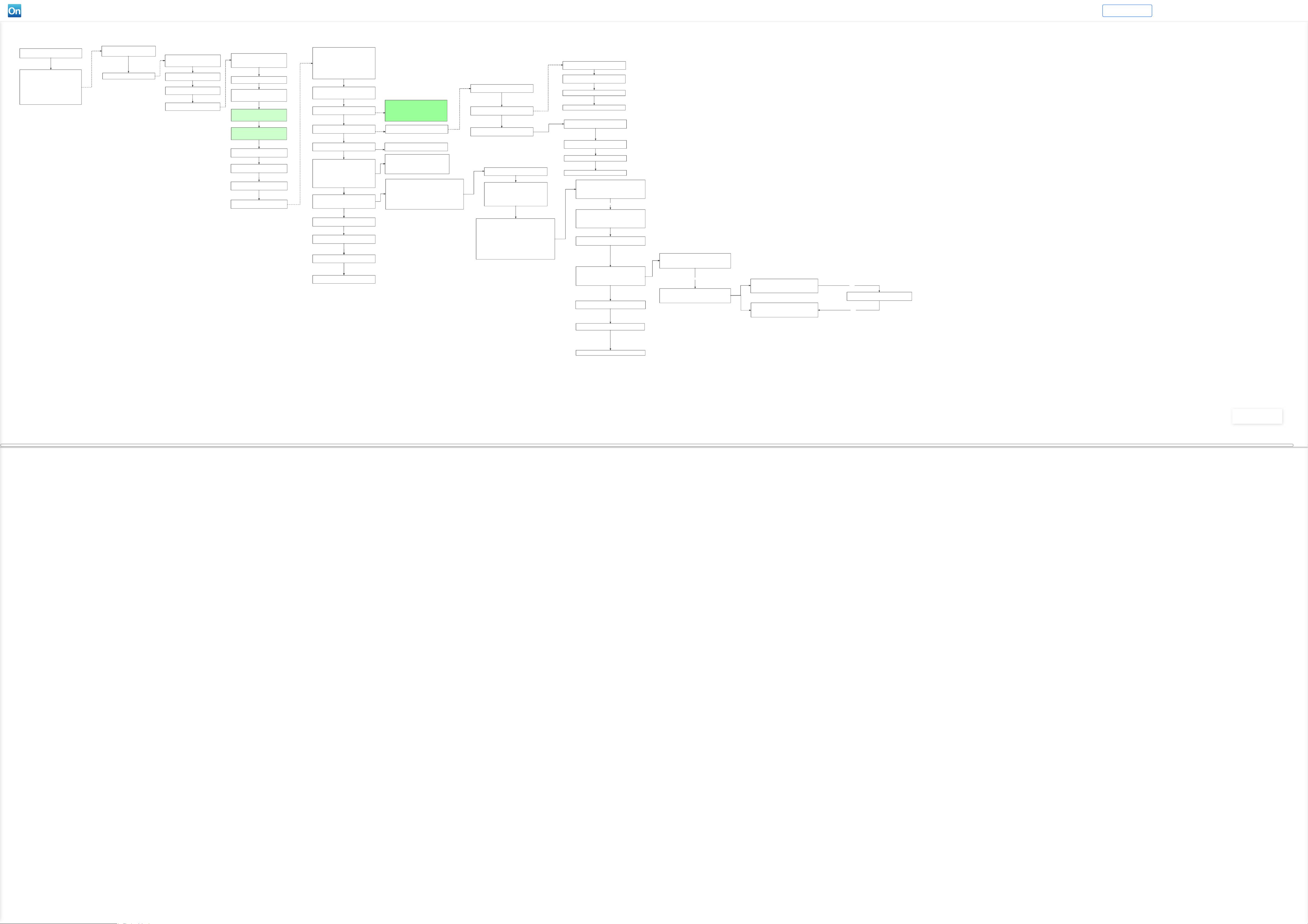
图解DataX执行流程
1 135 0 登录 注册 克隆(¥5.0)

踏雪江南
- 粉丝: 27
- 资源: 4
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 京瓷TASKalfa系列维修手册:安全与操作指南
- 小波变换在视频压缩中的应用
- Microsoft OfficeXP详解:WordXP、ExcelXP和PowerPointXP
- 雀巢在线媒介投放策划:门户网站与广告效果分析
- 用友NC-V56供应链功能升级详解(84页)
- 计算机病毒与防御策略探索
- 企业网NAT技术实践:2022年部署互联网出口策略
- 软件测试面试必备:概念、原则与常见问题解析
- 2022年Windows IIS服务器内外网配置详解与Serv-U FTP服务器安装
- 中国联通:企业级ICT转型与创新实践
- C#图形图像编程深入解析:GDI+与多媒体应用
- Xilinx AXI Interconnect v2.1用户指南
- DIY编程电缆全攻略:接口类型与自制指南
- 电脑维护与硬盘数据恢复指南
- 计算机网络技术专业剖析:人才培养与改革
- 量化多因子指数增强策略:微观视角的实证分析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


