Python决策树实验:模型评估与选择关键方法
需积分: 5 41 浏览量
更新于2024-08-03
收藏 1.55MB PDF 举报
在本次Python机器学习实验中,主要关注的是决策树作为基本算法之一的学习和模型评估。实验的主要目的是通过Python编程实践,理解并掌握模型验证与性能度量的关键概念和方法,以便在实际项目中应用。
首先,实验涉及到以下几个关键知识点:
1. **模型验证**:通过交叉验证(Cross-validation)来评估模型的泛化能力。交叉验证是一种统计学方法,将数据集分成几个互斥的子集,然后在每个子集上进行训练和测试,最终汇总结果以减少过拟合风险。
2. **性能度量**:包括混淆矩阵(Confusion Matrix),用来分析模型预测结果的准确性,如查准率(Precision)、查全率(Recall)或召回率,以及F1分数,它是查准率和查全率的调和平均数,提供了一个平衡的评价指标。此外,P-R曲线和受试者工作特征曲线(Receiver Operating Characteristic, ROC曲线)用于可视化模型性能,AUC(Area Under Curve)则衡量ROC曲线下的面积,AUC值越大,模型性能越好。
3. **基础算法介绍**:
- **逻辑回归**:专用于二分类问题,估计事件发生的概率。
- **虚拟分类器**:作为一种基准模型,不应用于实际问题,主要用于比较其他分类器的效果。
- **决策树**:基于树状结构的分类模型,通过对属性的递归划分进行预测。
- **支持向量机(SVM)**:基于最大间隔分类,原始为线性模型,但通过核函数可以处理非线性问题。
- **随机森林**:集成多个决策树,通过随机选择属性和样本构建,降低过拟合风险。
实验内容参考了《Python机器学习基础教程》第五章的特定章节,但需要排除mglearn.plots部分,这些内容通常涉及可视化工具的使用,而不是模型评估的核心原理。
在整个实验过程中,参与者将学习如何在Python环境中实现这些算法,并通过实例代码来实践模型的训练、评估和优化。通过这个过程,不仅掌握了理论知识,也提升了实际操作技能。同时,对模型选择的理解将有助于根据具体任务需求,决定哪种模型更适合解决问题。
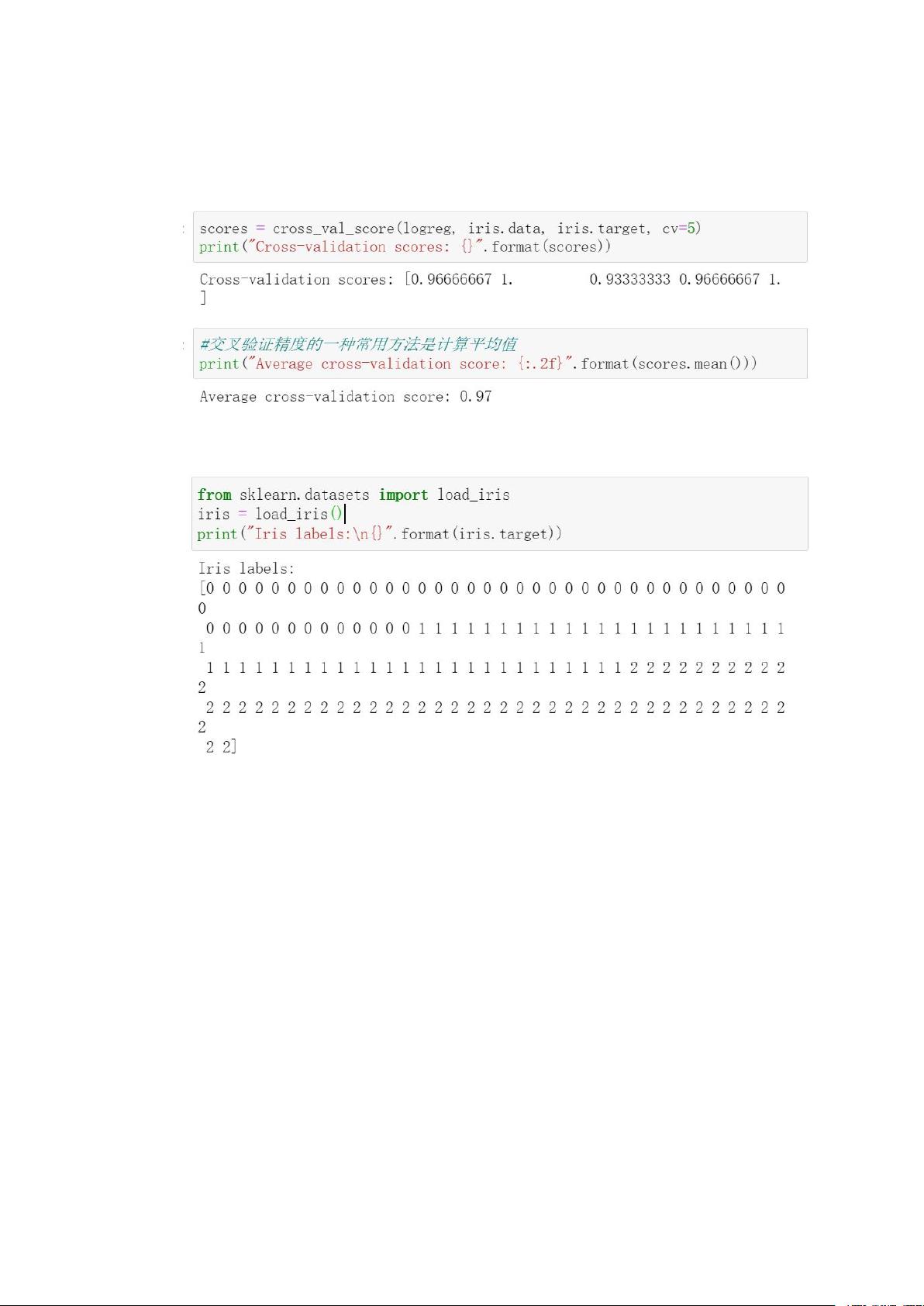
默认情况下,cross_val_score 执行 3 折交叉验证,返回 3 个精度值。
可以通过修改 cv 参数来改变折数。
2. 分层 k 折交叉验证和其他策略
对交叉验证的更多控制--个交叉验证分离器(cross-validation splitter)
剩余12页未读,继续阅读
2023-08-18 上传
2017-03-18 上传
2023-06-12 上传
2023-08-20 上传
2023-09-18 上传
2023-09-01 上传
2024-11-11 上传
2023-06-11 上传
2023-06-10 上传

小嘤嘤怪学
- 粉丝: 1520
- 资源: 21
 我的内容管理
展开
我的内容管理
展开







