NEON指令优化:高效处理RGB图像通道交换
NEON指令优化PPT主要关注于如何有效地利用ARM Cortex-A系列处理器中的Neon(单精度向量扩展)架构来提升图像处理性能。在处理像24-bit RGB图像这样的数据时,常规的线性加载方法可能会遇到效率问题,尤其是当需要进行复杂的数据转换,如R和B通道的互换时。
首先,传统的线性加载方式将RGB数据逐个像素读取到D寄存器,这种方法不仅耗时,而且需要额外的掩码、移位和合并操作,导致代码复杂且执行效率不高。然而,Neon提供了结构化的加载和存储指令,这些指令能够一次性将多个元素从内存加载到寄存器,并允许对这些元素进行分组处理,简化了数据操作。
例如,VLD3(Vector Load Data)指令可以用来一次性加载三个RGB分量到不同的寄存器,使得数据的处理变得高效。之后,通过VSWP(Vector Swap Pairs)指令,可以直接在寄存器之间交换R和B值,无需复杂的掩码操作。存储时,使用VST3(Vector Store Data)指令,结合interleave(交织)模式,确保数据按正确的顺序写回内存。
具体来说,结构化加载和存储指令的语法如下:
- 指令助记符(如VLD1、VLD2或VLD3)
- 插入一个表示interleave模式的数字(1-4,表示元素间间距)
- 元素类型,如8、16或32位
- 目标64-bit NEON寄存器(最多4个,取决于模式)
- 可选的ARM寄存器用于存储内存地址,地址可在每次访问时更新
VLD1适用于无交织的简单加载,而VLD2和VLD3则分别针对2或4个元素进行解交织和加载。这些指令大大简化了数据操作流程,提高了处理图像等密集型任务的性能。
这个PPT教程深入讲解了如何利用Neon指令优化来提高图像处理中的性能,特别是针对大规模数据处理的高效策略,这对于开发人员在实际项目中优化代码和提升硬件利用效率具有重要意义。理解并掌握这些技术对于编写出既快速又高效的代码至关重要。
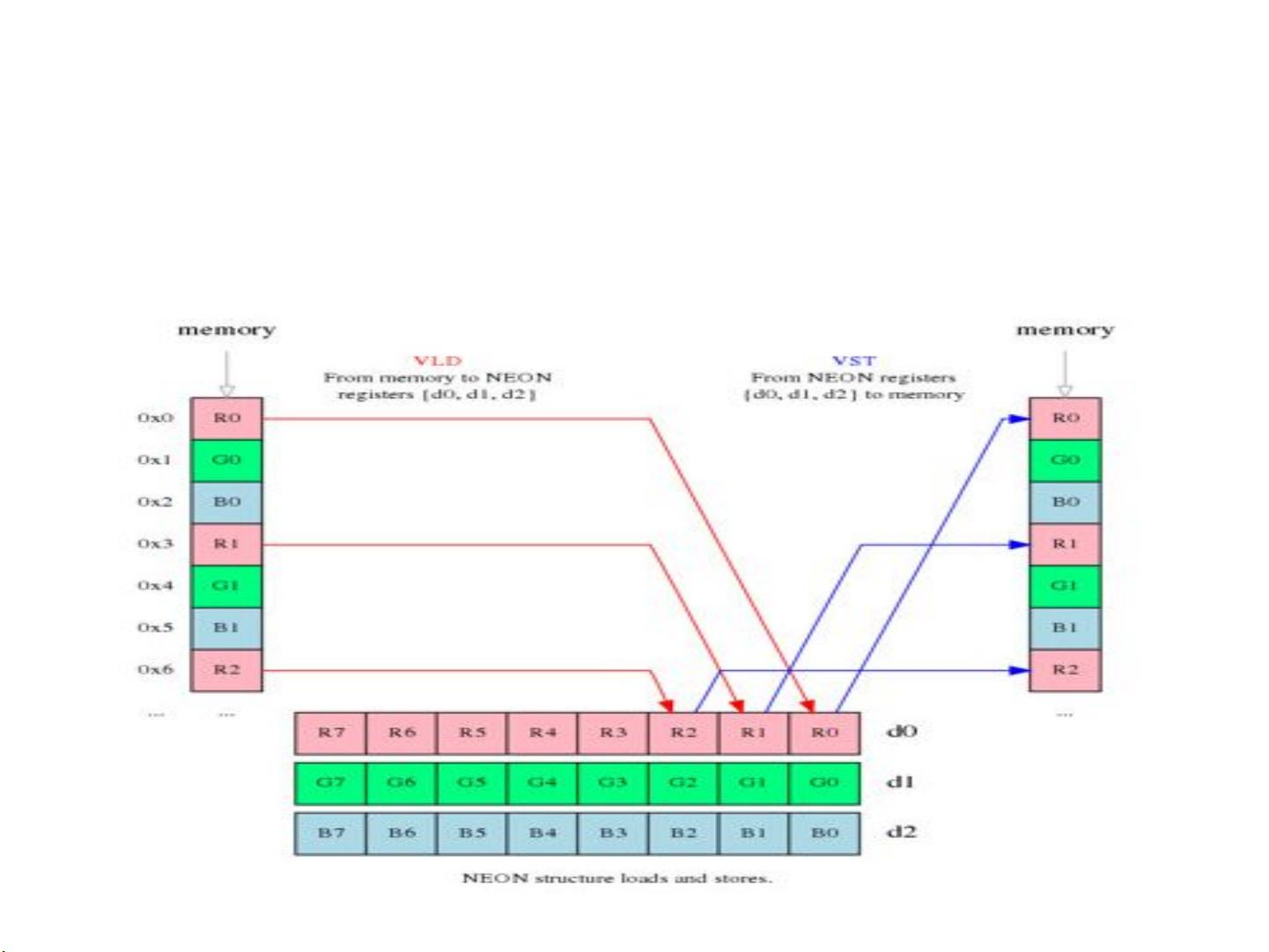
结构化加载和存储语法和具体指令
•
NEON 结构化加载会读取内存内容到 64-bit 的 NEON 寄存器,使用可选
的 deinterleave 选项,同样加载指令也可以采用这种 reinterleave 的方
式把寄存器的内容写到内存空间。
剩余22页未读,继续阅读
2023-05-19 上传
2023-05-17 上传
2023-05-19 上传
2023-05-09 上传
2023-05-16 上传
2023-06-08 上传

aliqing777
- 粉丝: 10
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- AirKiss技术详解:无线传递信息与智能家居连接
- Hibernate主键生成策略详解
- 操作系统实验:位示图法管理磁盘空闲空间
- JSON详解:数据交换的主流格式
- Win7安装Ubuntu双系统详细指南
- FPGA内部结构与工作原理探索
- 信用评分模型解析:WOE、IV与ROC
- 使用LVS+Keepalived构建高可用负载均衡集群
- 微信小程序驱动餐饮与服装业创新转型:便捷管理与低成本优势
- 机器学习入门指南:从基础到进阶
- 解决Win7 IIS配置错误500.22与0x80070032
- SQL-DFS:优化HDFS小文件存储的解决方案
- Hadoop、Hbase、Spark环境部署与主机配置详解
- Kisso:加密会话Cookie实现的单点登录SSO
- OpenCV读取与拼接多幅图像教程
- QT实战:轻松生成与解析JSON数据
