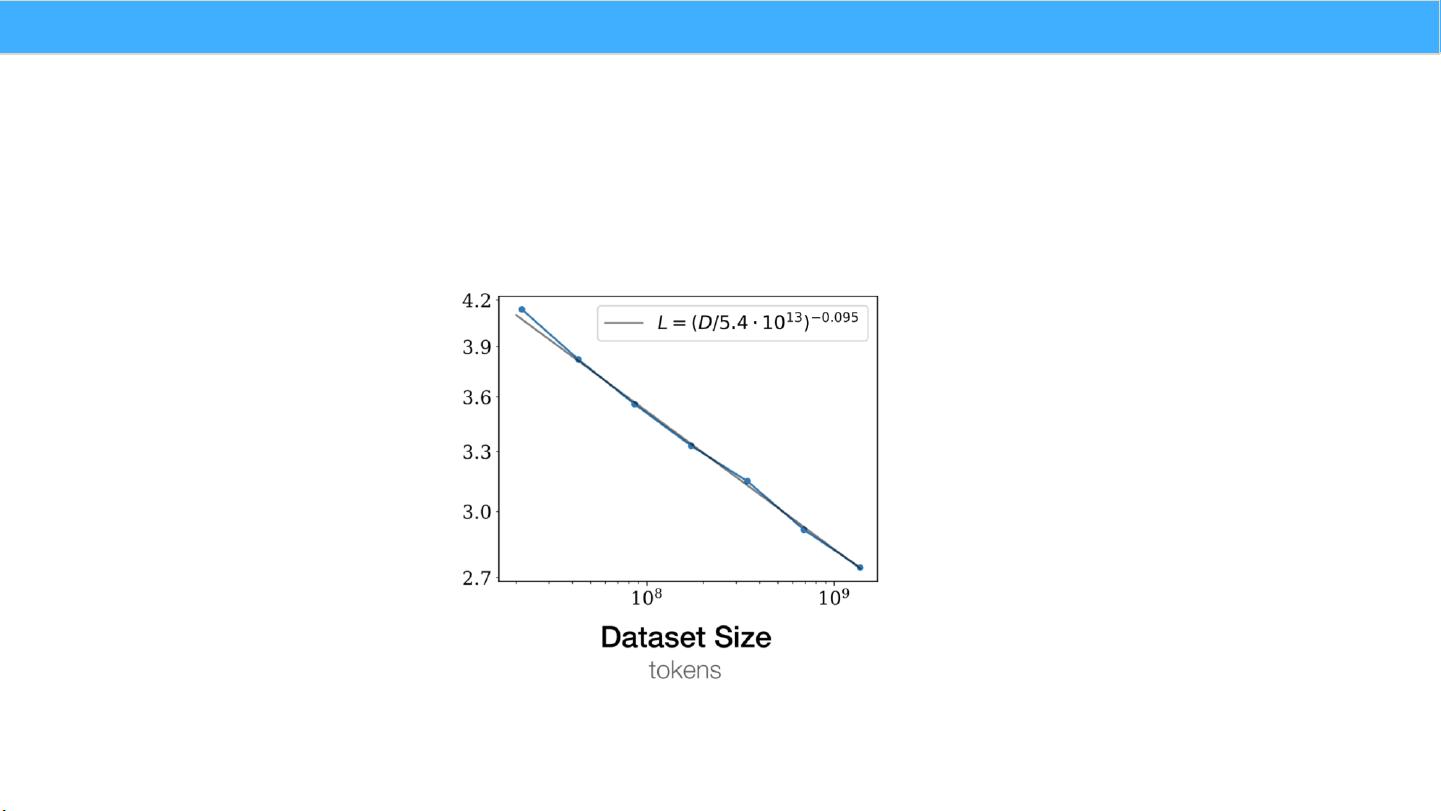
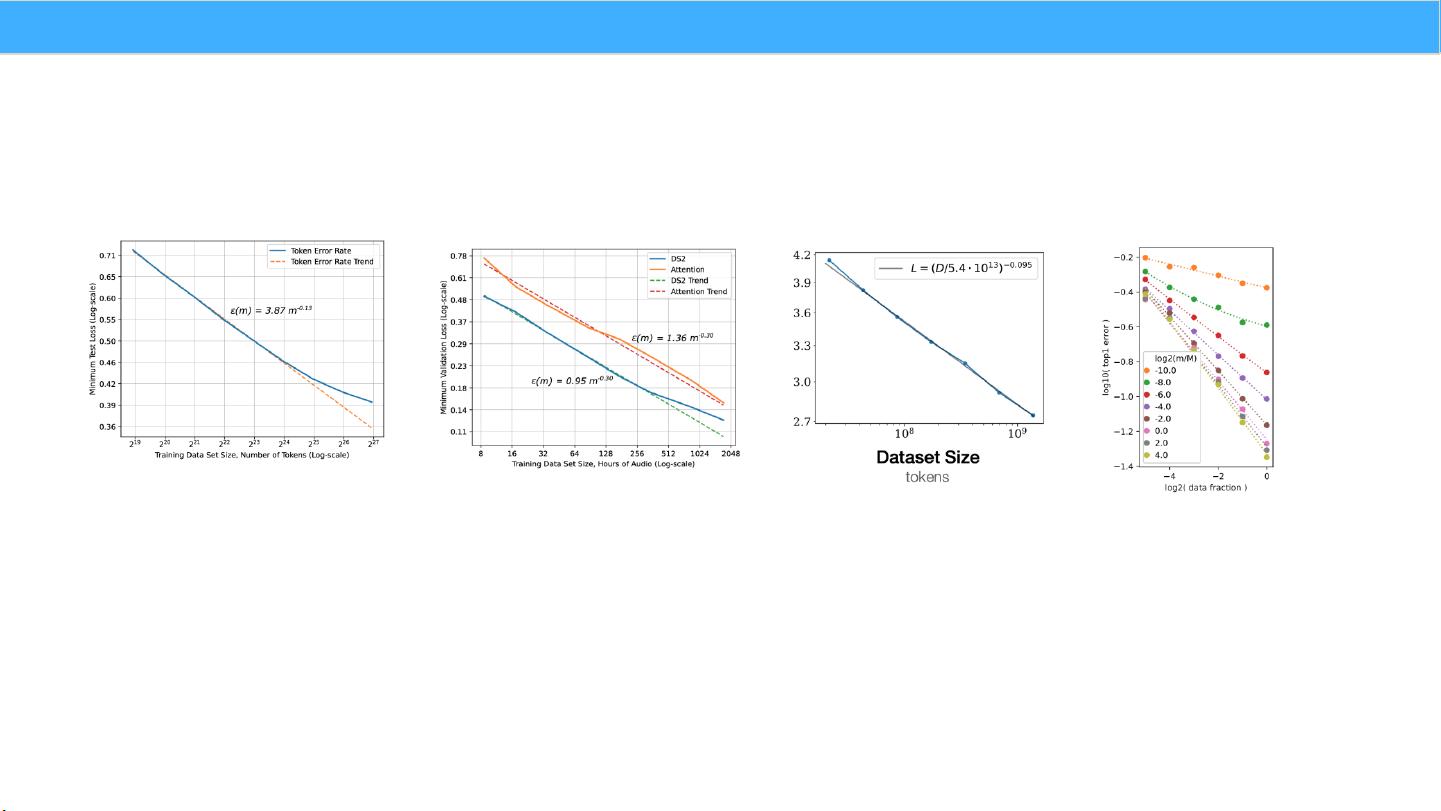
"CS324课程大模型中的Scaling Law(规模法则)课件,探讨了在人工智能和自然语言处理领域,大规模模型性能与其参数量、数据集大小和计算量之间的关系。Scaling Law指出,为了达到最佳性能,模型的参数、数据和计算资源需同步增长,并存在幂律关系。在Decoder-only模型中,性能与计算量C、模型参数N和数据大小D之间有特定的关联性,即C ≈6ND。当计算量固定时,模型性能主要由N和D决定,与结构参数如层数、深度和注意力头数量关联性较小。课程内容包括对数据、超参数和性能之间的规模法则分析,以及如何利用这些规则进行优化和预测。" Scaling Law是机器学习和人工智能领域的一个重要概念,它描述了模型性能随着模型复杂度、数据量和计算资源增加的趋势。在CS324课程中,Scaling Law被用来解决超参数调优的高昂成本问题。传统的超参数调优方法如猜测和祈祷、穷举搜索效率低下,而Scaling Law提供了一种更为简单和预测性的规则,可以在小规模模型上找到最优超参数,然后推断到大规模模型上。 课程分为几个部分,首先讨论了数据量与性能的关系,即数据规模法则。这意味着存在一个简单的公式,可以将数据集的大小映射到模型的性能。这种关系对于理解模型在不同数据量下的行为至关重要,有助于确定增加数据量是否能有效提升模型性能。 其次,课程探讨了超参数与性能之间的联系。通常,理想的超参数设置在不同的数据和模型之间是否一致是个问题。Scaling Law提供了一种理解这些关系的方法,可能揭示在不同环境下的最佳超参数选择具有共性,从而减少对每种新模型或数据集的独立调优需求。 最后,课程还涉及了利用Scaling Laws进行性能预测。通过观察和分析模型在不同规模下的表现,可以预测在更大规模上的性能趋势,这对于资源规划和项目决策具有重要意义。 在Decoder-only模型的示例中,模型的计算量(FLOPs)与模型参数量N和数据大小D之间存在近似线性关系C ≈6ND。这表明,在计算资源有限的情况下,模型性能主要由N和D的平衡决定,而模型的具体架构细节如层数、深度和注意力头数量的影响相对较小,性能波动通常在2%的范围内。这一发现简化了优化过程,有助于在构建大型语言模型时更有效地分配资源。 Scaling Law为理解和优化大模型提供了强大的理论框架,使得研究者和工程师能够在资源有限的情况下做出更明智的决策,提高模型训练的效率和最终性能。通过深入学习和理解这些规则,我们可以更好地预测模型在大规模扩展时的行为,从而降低超参数调优的成本,并加速AI和NLP领域的进展。
剩余36页未读,继续阅读