机器学习优化困境:局部最小值与鞍点
需积分: 14 186 浏览量
更新于2024-08-04
收藏 6.16MB PDF 举报
"李宏毅机器学习.pdf"
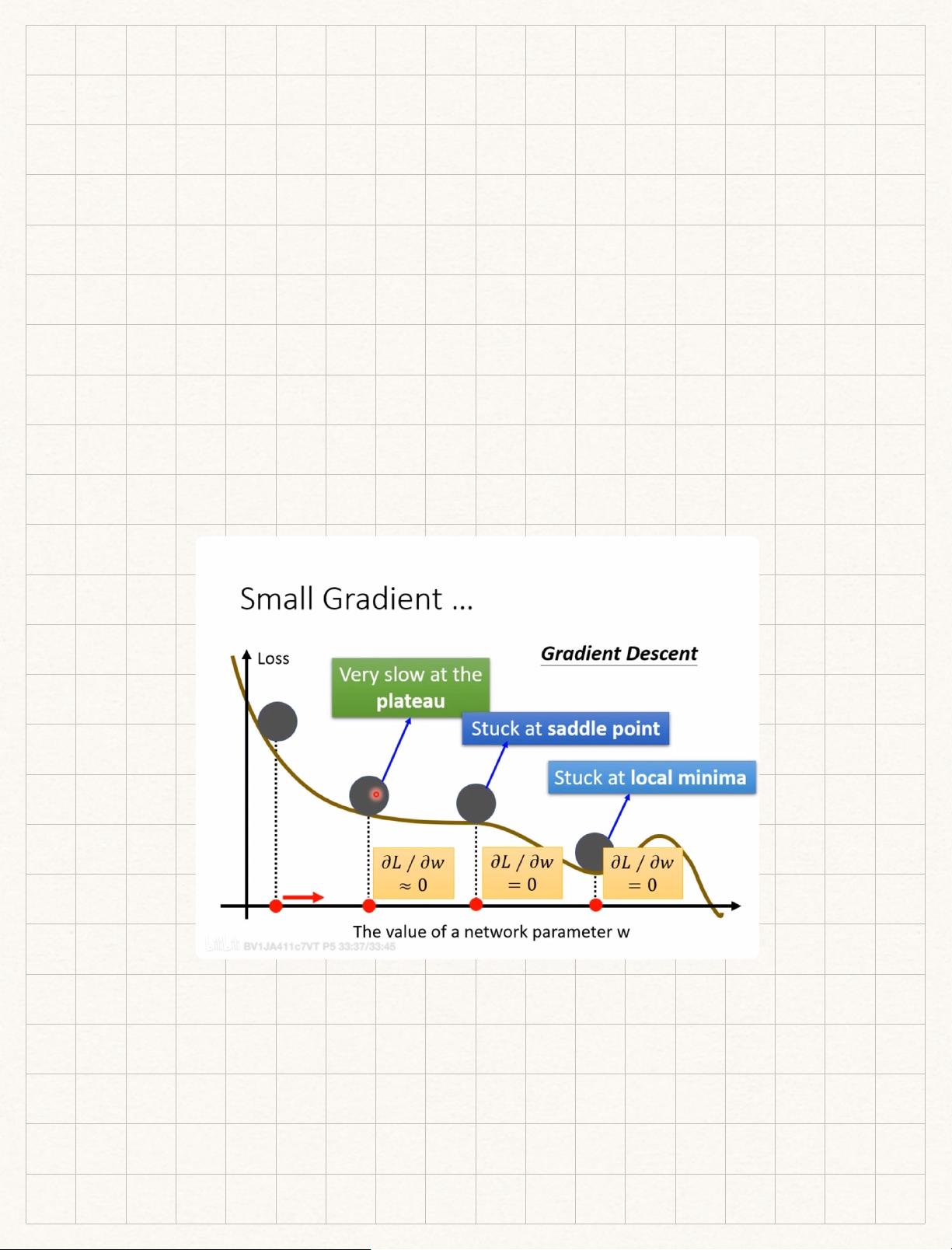
在机器学习领域,优化是核心问题,特别是当我们面临复杂的模型和大量的参数时。优化失败通常与梯度接近0有关,这可能表明我们处于一个临界点,即局部最小值或鞍点。临界点是梯度消失的地方,其中局部最小值是函数在周围区域中的最低点,而鞍点则是某些方向上是局部最小值,但在其他方向上是局部最大值的点。
泰勒级数近似(Tayler Series Approximation)常用来分析这些临界点的性质。通过展开函数的二阶导数矩阵,即海森矩阵(Hessian),我们可以判断这些点的特性。海森矩阵的特征值决定了临界点的类型:如果所有特征值都是正的,那么我们面对的是一个局部最小值;如果所有特征值都是负的,则为局部最大值;如果特征值有正有负,则可能是鞍点。
在实际训练神经网络时,大部分情况下我们会遇到鞍点而不是局部最小值。这是因为网络训练过程中,minimum ratio(正特征值数量与总特征值数量的比值)通常不超过0.5,这意味着特征值既有正也有负,更倾向于鞍点而非局部最小值。
批量优化(batch optimization)是解决这一问题的一种策略。使用批量更新可以提高效率,因为它减少了每次更新所需的计算次数。但是,批量大小的选择至关重要。小批量(batch size)可以更快地进行参数更新,但计算成本较高;而大批量可以减少整个epoch的计算时间,但可能在验证集上表现不佳,因为其降低了模型的泛化能力。
动量(Momentum)是一种优化技术,它结合了之前的梯度方向和当前的梯度来决定更新的方向,有助于快速穿过平坦区域和避开局部最小值。然而,这依然无法完全解决鞍点问题。
适应性学习率(adaptive learning rate)是另一个关键的优化方法,例如Adagrad、RMSProp和Adam。Adagrad通过考虑每个参数的历史梯度平方和来调整学习率,但它假设所有参数的梯度大小相同,这可能限制了学习率的适应性。RMSProp解决了这个问题,它仅基于最近的梯度信息来调整学习率。Adam是目前最常用的优化器之一,结合了动量和RMSProp的优点,并引入了动量项的指数移动平均,使得在多种任务中都能获得良好的性能。此外,学习率调度(learning rate scheduling),如衰减(decay)和预热(warmup),也是优化过程中的常用技巧,以帮助模型在训练过程中找到更好的解决方案。
在回归和分类问题中,softmax函数经常用于多分类任务,而交叉熵(cross-entropy)作为损失函数来衡量预测概率分布与真实标签之间的差异。在Python中,通常会将softmax和交叉熵损失函数一起使用,以实现端到端的训练流程。
ma !
!
local minima在另⼀个维度上看会不会是⼀个saddle point呢? !
是在经过 empirical study 后能验证这个假说:!
条件:训练⽹络,直到它到达critical point!
minimum ratio = 正的特征值的数量 / 特征值的数量 ,正特征值越多,越像local minima!
由图可得,minimum ratio 最⾼也只有0.5,说明特征值仍然有正有负。!
!
总结:⼤部分⽹络训练都是saddle point!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
剩余12页未读,继续阅读
218 浏览量
2024-03-30 上传
2023-08-17 上传
2023-08-01 上传
2023-09-06 上传
2024-06-06 上传
2023-07-28 上传
2024-08-11 上传
2023-12-20 上传

江某1111号机
- 粉丝: 2
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Hadoop生态系统与MapReduce详解
- MDS系列三相整流桥模块技术规格与特性
- MFC编程:指针与句柄获取全面解析
- LM06:多模4G高速数据模块,支持GSM至TD-LTE
- 使用Gradle与Nexus构建私有仓库
- JAVA编程规范指南:命名规则与文件样式
- EMC VNX5500 存储系统日常维护指南
- 大数据驱动的互联网用户体验深度管理策略
- 改进型Booth算法:32位浮点阵列乘法器的高速设计与算法比较
- H3CNE网络认证重点知识整理
- Linux环境下MongoDB的详细安装教程
- 压缩文法的等价变换与多余规则删除
- BRMS入门指南:JBOSS安装与基础操作详解
- Win7环境下Android开发环境配置全攻略
- SHT10 C语言程序与LCD1602显示实例及精度校准
- 反垃圾邮件技术:现状与前景
