深度解析Transformer模型:从概念到工作原理
"图解Transformer.pdf"
Transformer模型是现代自然语言处理(NLP)领域中的一个里程碑,由Google在2017年的论文《Attention is All You Need》中首次提出。该模型彻底改变了序列建模的方式,尤其是在机器翻译任务中表现出了卓越的性能,并且其高效并行计算的能力解决了循环神经网络(RNN)在长序列处理时的效率问题。Transformer的核心创新在于自我注意力(Self-Attention)机制,这一机制允许模型在处理序列数据时同时考虑所有元素,而不仅仅是依赖于前一时刻的状态。
Transformer模型结构分为编码器(Encoder)和解码器(Decoder)两部分,每一部分都由多层堆叠的块组成。每个块包含两个主要组件:自注意力层和前馈神经网络(FFN)。自注意力层允许模型在计算每个位置的表示时,考虑序列中所有其他位置的信息。这通过三个矩阵运算——键(Key)、值(Value)和查询(Query)实现,它们都是输入序列的线性变换。自注意力机制使得Transformer能够捕捉长距离的依赖关系,而无需像RNN那样顺序处理。
在编码器中,自注意力层之后通常会接一个残差连接(Residual Connection)和层归一化(Layer Normalization),这有助于梯度的传播和模型的稳定训练。接着,FFN由两个全连接层组成,中间采用ReLU激活函数,进一步增加了模型的表达能力。
解码器与编码器类似,但也包含额外的机制来防止当前位置访问到未来的信息,这对于序列生成任务至关重要。解码器的第一层自注意力层是对自身位置的注意力,第二层则同时考虑编码器的输出和自身的位置,这种机制被称为遮罩自注意力(Masked Self-Attention)。
Transformer模型的成功也在于其引入了位置编码(Positional Encoding),因为模型本身不具备位置感知能力。位置编码是向输入序列添加的固定向量,以保持词汇顺序信息,这些向量是正弦和余弦函数的组合,随着位置的增加而变化,确保了不同位置的信号具有不同的频率和相位。
Transformer的另一个重要贡献是BERT(Bidirectional Encoder Representations from Transformers),它在预训练阶段使用Transformer架构对大量未标记文本进行学习,然后在各种下游任务上进行微调。BERT通过引入掩码语言模型(Masked Language Modeling)和下一句预测(Next Sentence Prediction)任务,实现了对输入序列的双向上下文理解,进一步提升了模型的性能。
Transformer模型通过自我注意力机制、残差连接、层归一化以及位置编码等设计,极大地推动了NLP领域的进展,不仅在机器翻译任务中取得了优异效果,还在问答、情感分析、文本生成等多个NLP任务中成为首选模型。随着对Transformer的深入理解和不断优化,它已经成为现代深度学习研究和应用中不可或缺的部分。
2019/12/12 AI基础:图解Transformer
https://mp.weixin.qq.com/s?__biz=MzIwODI2NDkxNQ==&mid=2247486926&idx=2&sn=48bb3547b4cebe17dc2bc06e686b9073&chksm=97048
…
6/29
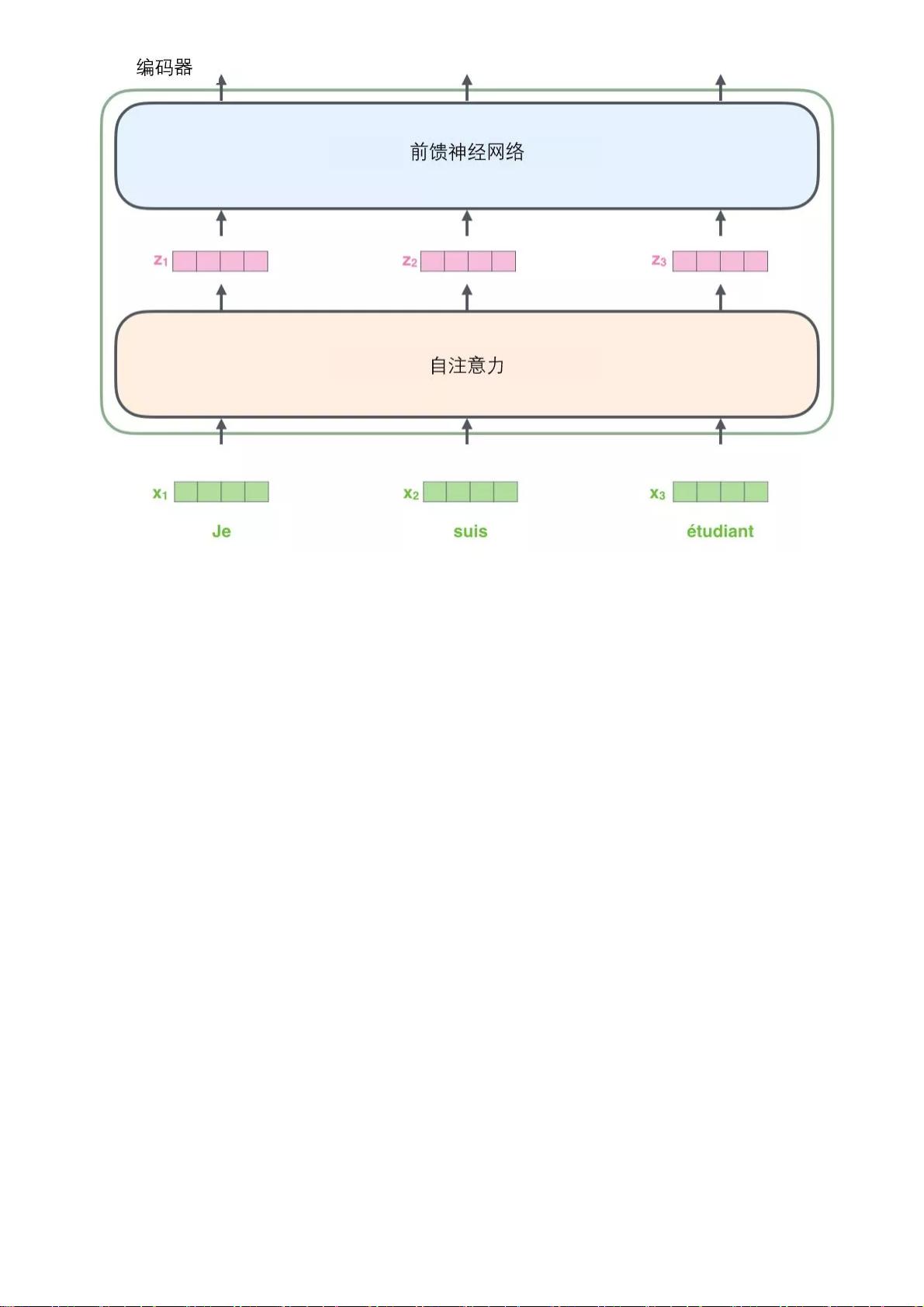
接下来我们看看Transformer的一个核心特性,在这里输入序列中每个位置的单词都有自己独
特 的 路 径 流 入 编 码 器 。 在 自 注 意 力 层 中 , 这 些 路 径 之 间 存 在 依 赖 关 系 。 而 前 馈 ( feed-
forward)层没有这些依赖关系。因此在前馈(feed-forward)层时可以并行执行各种路径。
然后我们将以一个更短的句子为例,看看编码器的每个子层中发生了什么。
现在我们开始“编码”
如上述已经提到的,一个编码器接收向量列表作为输入,接着将向量列表中的向量传递到自注
意力层进行处理,然后传递到前馈神经网络层中,将输出结果传递到下一个编码器中。
剩余28页未读,继续阅读
2020-04-09 上传
2023-08-03 上传
2024-03-16 上传
2023-07-28 上传
2024-06-18 上传
2023-09-04 上传
2023-08-24 上传

不安分实验室
- 粉丝: 130
- 资源: 23
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多模态联合稀疏表示在视频目标跟踪中的应用
- Kubernetes资源管控与Gardener开源软件实践解析
- MPI集群监控与负载平衡策略
- 自动化PHP安全漏洞检测:静态代码分析与数据流方法
- 青苔数据CEO程永:技术生态与阿里云开放创新
- 制造业转型: HyperX引领企业上云策略
- 赵维五分享:航空工业电子采购上云实战与运维策略
- 单片机控制的LED点阵显示屏设计及其实现
- 驻云科技李俊涛:AI驱动的云上服务新趋势与挑战
- 6LoWPAN物联网边界路由器:设计与实现
- 猩便利工程师仲小玉:Terraform云资源管理最佳实践与团队协作
- 类差分度改进的互信息特征选择提升文本分类性能
- VERITAS与阿里云合作的混合云转型与数据保护方案
- 云制造中的生产线仿真模型设计与虚拟化研究
- 汪洋在PostgresChina2018分享:高可用 PostgreSQL 工具与架构设计
- 2018 PostgresChina大会:阿里云时空引擎Ganos在PostgreSQL中的创新应用与多模型存储
