Flink与Atlas整合:实现数据治理与追踪
需积分: 11 50 浏览量
更新于2024-08-04
收藏 323KB PDF 举报
"这篇文章主要讨论了Flink与Apache Atlas的整合,目的是为了实现数据治理,追踪数据处理的元数据、所有权以及血统等信息。Apache Atlas是一个数据治理框架,已经与HDFS、Kafka、Hive等多个系统集成。在Flink中添加Atlas支持将允许我们追踪Flink作业的输入输出数据、所有者以及不同Flink作业之间的关联。本文将重点介绍Flink Streaming程序的Atlas集成,主要包括Flink实体定义和Flink Atlas钩子的实现细节。"
在Flink和Apache Atlas的整合过程中,有两个关键组成部分:
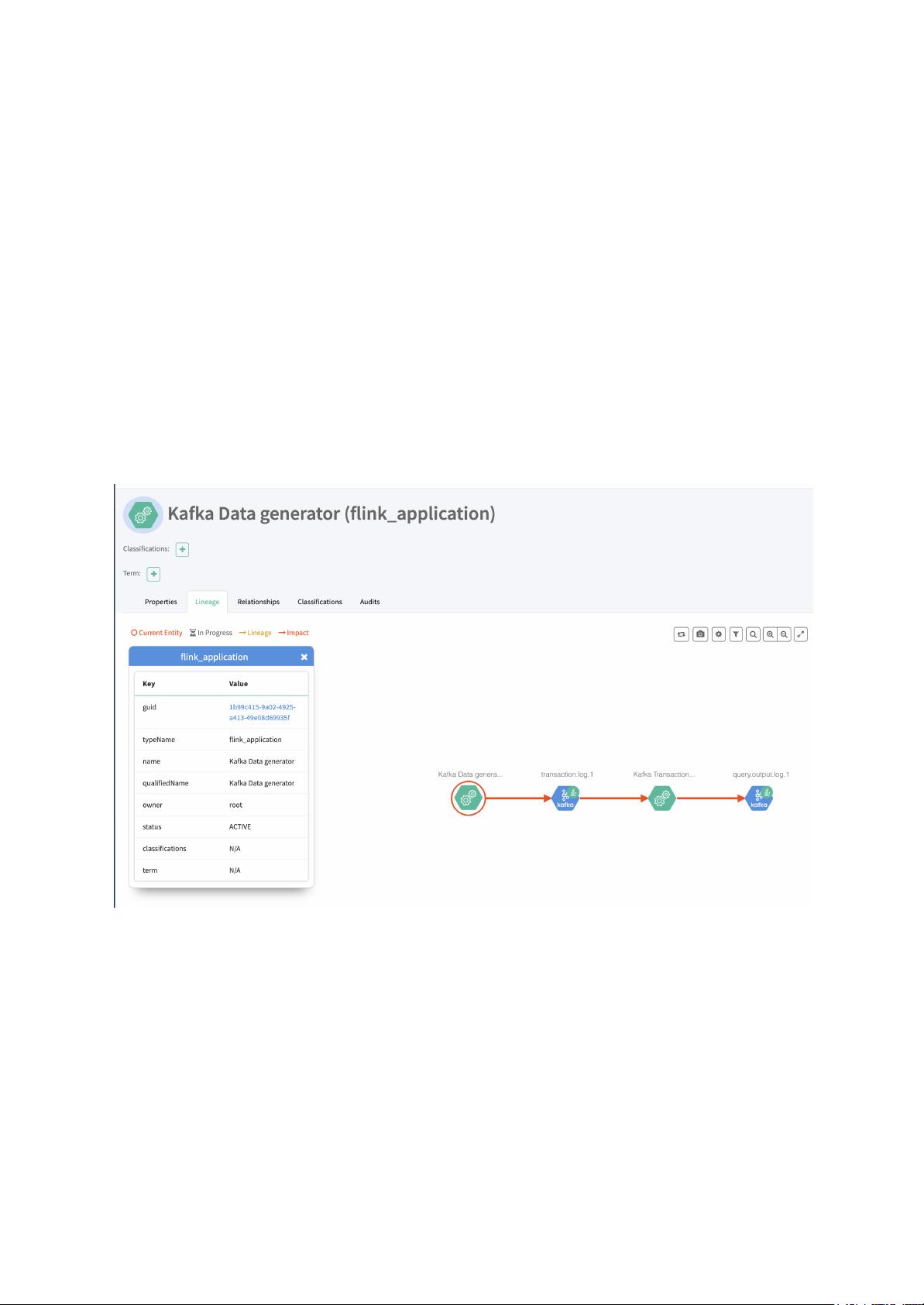
1. **Flink实体定义**:这是描述我们希望在Atlas中注册的关于Flink作业的信息。首先建议创建一个基础的Flink Application实体,未来可以根据需要进行扩展。提议的Flink Application实体包含以下属性:
- `id`:作业的唯一标识。
- `startTime`:作业的开始时间。
- `endTime`:作业的结束时间。
- `conf`:作业配置的Map。
- `inputs`:输入数据源的列表。
- `outputs`:输出数据目标的列表。
2. **Flink Atlas钩子**:这个钩子是Flink与Atlas之间的桥梁,它会在Flink作业的生命周期中执行特定操作,如在作业启动和结束时向Atlas注册或更新作业元数据。当Flink作业开始运行时,钩子会将Flink Application实体的信息注册到Atlas中;当作业结束时,它可能会更新作业的结束时间或者清除相关元数据。这使得我们可以实时追踪Flink作业的状态和数据流动。
Flink Atlas整合的实现可能包括以下几个步骤:
- **集成准备**:在Flink环境中配置Atlas的连接信息,如服务地址、端口和认证信息。
- **开发Flink Atlas Hook**:实现一个Flink的CheckpointCompletionCallback或者JobListener,以便在作业启动、结束、检查点完成等关键点触发与Atlas的交互。
- **注册Flink实体**:在Hook中定义如何将Flink作业转换为Atlas的实体,包括提取作业的元数据和输入输出信息。
- **与Atlas通信**:使用Atlas的Java客户端API来创建、更新或查询实体。
- **测试与优化**:确保在各种场景下(如作业失败、重启、动态调整)Flink Atlas Hook都能正确地处理元数据。
通过这样的整合,企业可以在大规模的数据处理环境中实现更高级别的数据治理和监控,提高数据质量,保证合规性,并且能够快速响应数据问题,如数据丢失或异常。这对于大型公司来说是一个非常重要的需求。
Flink Atlas Integration
Motivation/Background
Very simply put Apache Atlas is a data governance framework that stores metadata for our
data and processing logic to track ownership, lineage etc. It is already integrated with
systems like HDFS, Kafka, Hive and many others.
Adding Flink integration would mean that we can track the input output data of our Flink jobs,
their owners and how different Flink jobs are connected to each other through the data they
produce (lineage). This is a very strong requirement at many large companies.
In this first version we will focus on Flink Streaming programs.
Atlas integration in a nutshell
In order to integrate with Atlas we basically need 2 things.
- Flink entity definitions
- Flink Atlas hook
下载后可阅读完整内容,剩余7页未读,立即下载
2023-06-26 上传
2022-11-25 上传
2023-08-23 上传
2023-07-27 上传
2023-11-23 上传
2023-07-28 上传
2023-05-30 上传
2023-08-23 上传
2024-05-30 上传

胖胖胖胖胖虎
- 粉丝: 130
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- Hadoop生态系统与MapReduce详解
- MDS系列三相整流桥模块技术规格与特性
- MFC编程:指针与句柄获取全面解析
- LM06:多模4G高速数据模块,支持GSM至TD-LTE
- 使用Gradle与Nexus构建私有仓库
- JAVA编程规范指南:命名规则与文件样式
- EMC VNX5500 存储系统日常维护指南
- 大数据驱动的互联网用户体验深度管理策略
- 改进型Booth算法:32位浮点阵列乘法器的高速设计与算法比较
- H3CNE网络认证重点知识整理
- Linux环境下MongoDB的详细安装教程
- 压缩文法的等价变换与多余规则删除
- BRMS入门指南:JBOSS安装与基础操作详解
- Win7环境下Android开发环境配置全攻略
- SHT10 C语言程序与LCD1602显示实例及精度校准
- 反垃圾邮件技术:现状与前景
