Spark:超越Hadoop的高效数据分析工具
94 浏览量
更新于2024-08-30
收藏 120KB PDF 举报
"Spark是一种快速数据分析平台,以其高效性能和内存计算能力成为Hadoop的有力替代方案。它在Scala语言中实现,与Hadoop相比,Spark更擅长处理迭代工作负载,通过内存计算显著提高了数据处理速度。Spark的核心是弹性分布式数据集(RDD),这是一种容错的只读对象集合,可以用于构建大规模、低延迟的数据分析应用。Spark可以在Hadoop文件系统上并行运行,也可以利用Mesos集群框架进行部署。"
Spark作为快速数据分析工具,其主要优势在于其内存计算模型。传统的Hadoop MapReduce模型在处理大数据时需要频繁地读写硬盘,这导致了较高的延迟。相比之下,Spark将数据存储在内存中,减少了I/O操作,极大地提升了处理速度,尤其适合需要多次迭代的计算任务,如机器学习算法。
Spark的编程模型是基于Scala语言的,这使得开发人员能够利用Scala的函数式编程特性,以简洁、高效的代码处理分布式数据。Scala与Spark的紧密结合使得开发人员能够像操作本地集合一样操作分布式数据集,降低了开发复杂度。
Spark的核心概念是弹性分布式数据集(RDD)。RDD是一个逻辑上的分片,分布在集群的不同节点上,具有容错性。当某个分片丢失时,可以通过其血统信息重新计算。RDD支持两种基本操作:转换和行动。转换创建新的RDD而不立即执行,而行动则触发实际的计算并可能返回结果给驱动程序或写入外部存储。
Spark还提供了一个交互式的Shell,名为Spark Shell,允许数据科学家和分析师快速测试和探索数据,进一步增强了其作为快速数据分析工具的吸引力。此外,Spark支持多种数据处理模式,包括批处理、流处理、图形处理和SQL查询,通过Spark SQL模块实现了与SQL的兼容性,方便传统SQL用户使用。
在集群管理方面,Spark可以与Hadoop的YARN或Apache Mesos配合使用,实现资源调度和任务管理。这种灵活性使得Spark可以无缝集成到现有的大数据生态系统中,成为Hadoop之外的一个强大选择。
Spark通过其内存计算、Scala集成、RDD抽象和广泛的功能支持,提供了一个高效、灵活且易用的大数据分析平台,尤其适用于需要高性能和低延迟的场景。
Spark,一种快速数据分析替代方案,一种快速数据分析替代方案
虽然 Hadoop 在分布式数据分析方面备受关注,但是仍有一些替代产品提供了优于典型 Hadoop 平台的令人关注的优势。
Spark 是一种可扩展的数据分析平台,它整合了内存计算的基元,因此,相对于 Hadoop 的集群存储方法,它在性能方面更具
优势。Spark 是在 Scala 语言中实现的,并且利用了该语言,为数据处理提供了独一无二的环境。了解 Spark 的集群计算方法
以及它与 Hadoop 的不同之处。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些
工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工
作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的
Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoo 文件系统中并行
运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms,
Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。
Spark 集群计算架构
虽然 Spark 与 Hadoop 有相似之处,但它提供了具有有用差异的一个新的集群计算框架。首先,Spark 是为集群计算中的特定
类型的工作负载而设计,即那些在并行操作之间重用工作数据集(比如机器学习算法)的工作负载。为了优化这些类型的工作
负载,Spark 引进了内存集群计算的概念,可在内存集群计算中将数据集缓存在内存中,以缩短访问延迟。
Spark 还引进了名为 弹性分布式数据集 (RDD) 的抽象。RDD 是分布在一组节点中的只读对象集合。这些集合是弹性的,如果
数据集一部分丢失,则可以对它们进行重建。重建部分数据集的过程依赖于容错机制,该机制可以维护 “血统”(即充许基于数
据衍生过程重建部分数据集的信息)。RDD 被表示为一个 Scala 对象,并且可以从文件中创建它;一个并行化的切片(遍布
于节点之间);另一个 RDD 的转换形式;并且最终会彻底改变现有 RDD 的持久性,比如请求缓存在内存中。
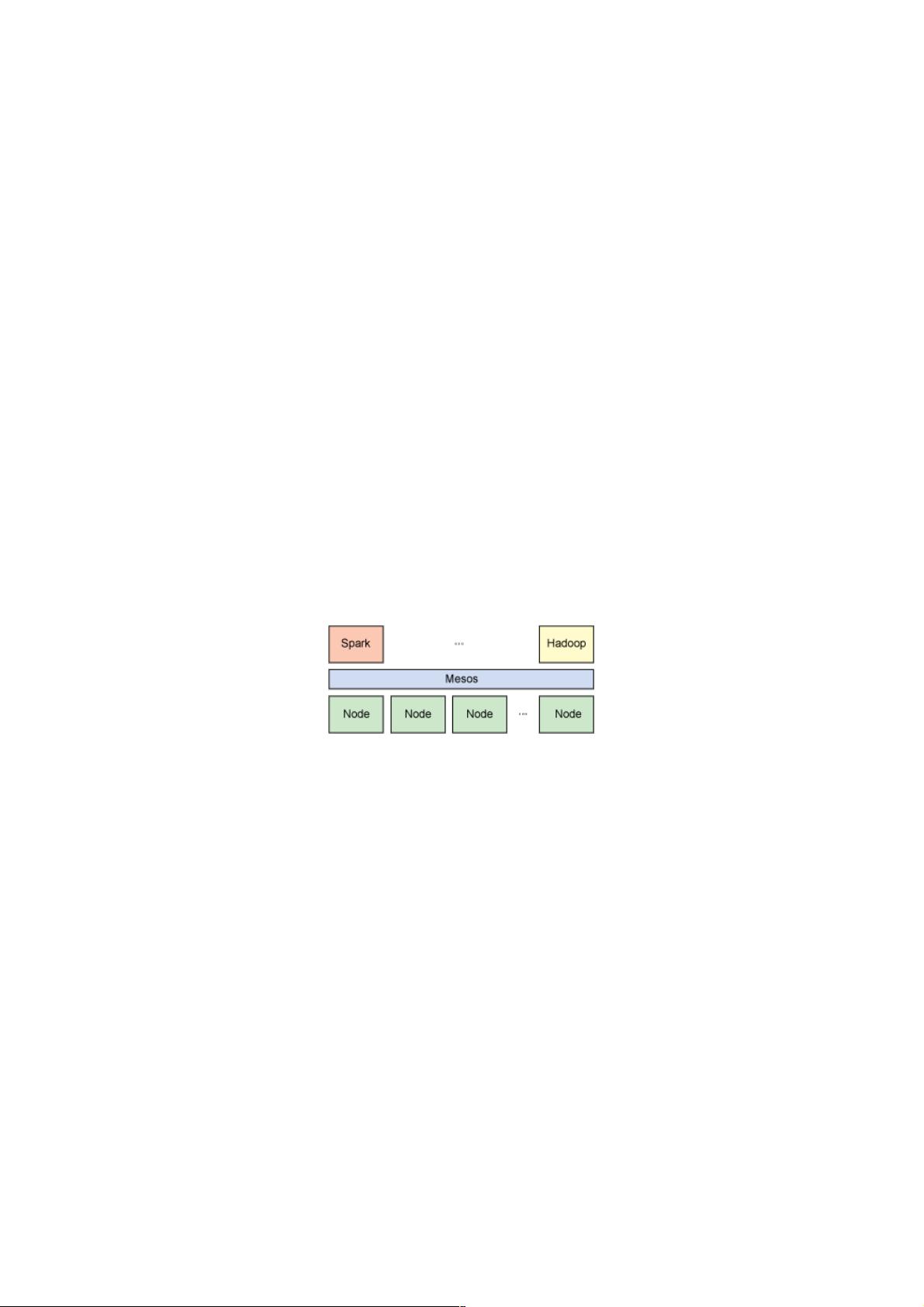
Spark 中的应用程序称为驱动程序,这些驱动程序可实现在单一节点上执行的操作或在一组节点上并行执行的操作。与
Hadoop 类似,Spark 支持单节点集群或多节点集群。对于多节点操作,Spark 依赖于 Mesos 集群管理器。Mesos 为分布式
应用程序的资源共享和隔离提供了一个有效平台(参见 图 1)。该设置充许 Spark 与 Hadoop 共存于节点的一个共享池中。
图 1. Spark 依赖于 Mesos 集群管理器实现资源共享和隔离。
Spark 编程模式
驱动程序可以在数据集上执行两种类型的操作:动作和转换。动作 会在数据集上执行一个计算,并向驱动程序返回一个值;
而转换 会从现有数据集中创建一个新的数据集。动作的示例包括执行一个 Reduce 操作(使用函数)以及在数据集上进行迭
代(在每个元素上运行一个函数,类似于 Map 操作)。转换示例包括 Map 操作和 Cache 操作(它请求新的数据集存储在内
存中)。
我们随后就会看看这两个操作的示例,但是,让我们先来了解一下 Scala 语言。
Scala 简介
Scala 可能是 Internet 上不为人知的秘密之一。您可以在一些最繁忙的 Internet 网站(如 Twitter、LinkedIn 和
Foursquare,Foursquare 使用了名为 Lift 的 Web 应用程序框架)的制作过程中看到 Scala 的身影。还有证据表明,许多金融
机构已开始关注 Scala 的性能(比如 EDF Trading 公司将 Scala 用于衍生产品定价)。
Scala 是一种多范式语言,它以一种流畅的、让人感到舒服的方法支持与命令式、函数式和面向对象的语言相关的语言特性。
从面向对象的角度来看,Scala 中的每个值都是一个对象。同样,从函数观点来看,每个函数都是一个值。Scala 也是属于静
态类型,它有一个既有表现力又很安全的类型系统。
此外,Scala 是一种虚拟机 (VM) 语言,并且可以通过 Scala 编译器生成的字节码,直接运行在使用 Java Runtime
Environment V2 的 Java? Virtual Machine (JVM) 上。该设置充许 Scala 运行在运行 JVM 的任何地方(要求一个额外的 Scala
运行时库)。它还充许 Scala 利用大量现存的 Java 库以及现有的 Java 代码。
最后,Scala 具有可扩展性。该语言(它实际上代表了可扩展语言)被定义为可直接集成到语言中的简单扩展。
举例说明 Scala
让我们来看一些实际的 Scala 语言示例。Scala 提供自身的解释器,充许您以交互方式试用该语言。Scala 的有用处理已超出
下载后可阅读完整内容,剩余4页未读,立即下载
106 浏览量
106 浏览量
2024-07-03 上传
158 浏览量
122 浏览量
点击了解资源详情
833 浏览量
522 浏览量
点击了解资源详情

weixin_38626192
- 粉丝: 4
- 资源: 932
 我的内容管理
展开
我的内容管理
展开







最新资源
- PJBlog2 qihh
- TodoRestApi:待办事项其余应用程序的服务器端
- spread:SPREAD 移动前景中的所有图形并尝试以愉快的方式排列它们。-matlab开发
- SeleniumDemo:Selenium自动化框架模板
- For-While
- kaggle dataset: publicassistance-数据集
- PHPWind论坛 prettyshow
- multitranslator
- 使用CNN的OCR韩语辅助应用程序
- SwiftUI仿表格效果完成代码
- Impermalink:用于创建缩短的,即将到期的链接的工具
- anime-sync
- Arduino-基于Web的MP3播放器-项目开发
- 预算跟踪器:使用503020方法的简单预算跟踪器
- TITUNI:Tituni - 标题程序。 还在测试中。-matlab开发
- BBSxp论坛 蓝语风格
