"生物学意义与数据聚类应用:分级聚类方法探讨"
需积分: 0 193 浏览量
更新于2024-03-21
收藏 1.59MB PDF 举报
Hierarchical clustering is a method used in data analysis and bioinformatics that is inspired by the hierarchical classification system used in biology. Just like how species are classified into orders, families, genera, and species, data can also be clustered into different levels of similarity.
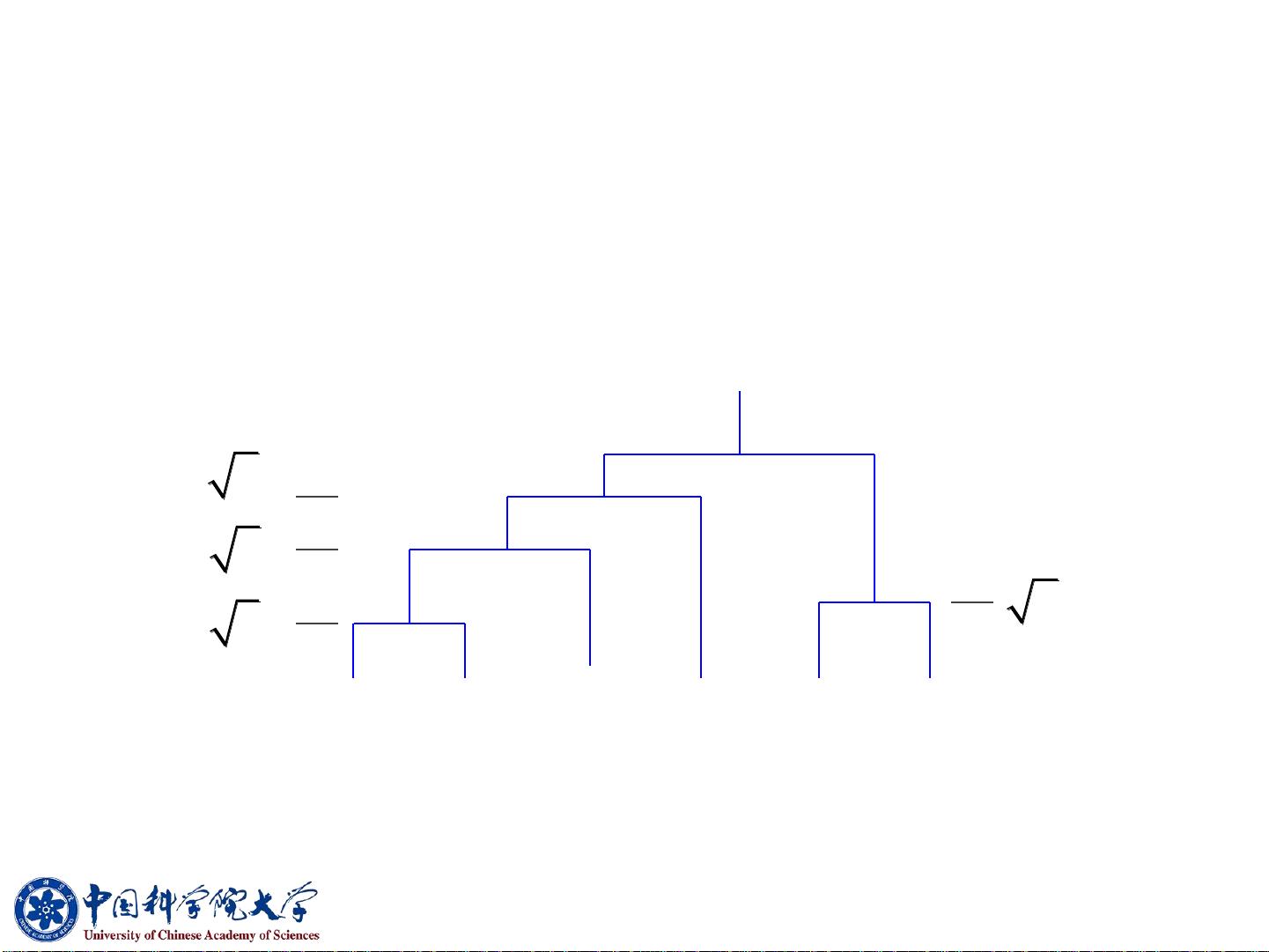
In hierarchical clustering, there are two main approaches: agglomerative clustering (bottom-up) and divisive clustering (top-down). In agglomerative clustering, each data point is initially considered as a single cluster and then pairs of clusters are merged based on a similarity measure until all data points belong to a single cluster. On the other hand, divisive clustering starts with all data points belonging to a single cluster and then splits the clusters into smaller clusters based on some criteria.
The hierarchical clustering method has great significance in biology, where it is used to classify species, study evolutionary relationships, and discover new species. This hierarchical approach can also be applied in data clustering, where it is known as hierarchical clustering or systematic clustering.
In conclusion, hierarchical clustering is a versatile method that can be used in various fields to group data based on similarity and uncover hidden patterns. Its hierarchical nature allows for a multi-level classification process that can reveal complex relationships and structures within the data. By mimicking the natural classification system found in biology, hierarchical clustering provides a powerful tool for organizing and analyzing data in a structured and intuitive manner.

基于上述矩阵,根据最小距离准则,应将 x
5
和x
6
合并
为一类,得到 G
1
={x
1
,x
2
}, {x
3
}, {x
4
}, G
2
={x
5
,x
6
}。
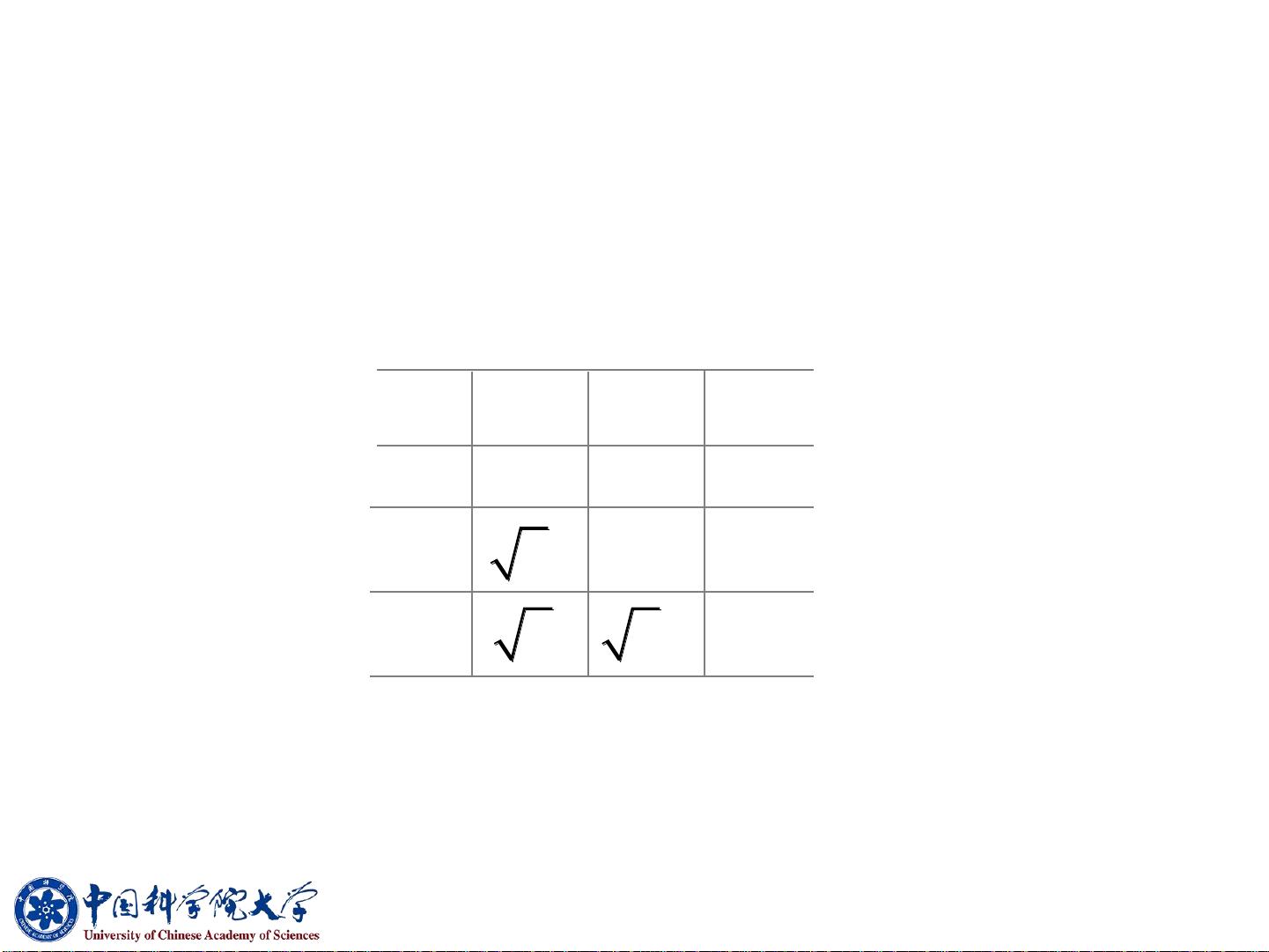
按最小距离原则重新计算各类之间的距离,见下表:
解 (续):
解释:比如,类G
1
与类G
2
之间的距离,
按最小距离准则,计算为x
2
与x
5
的距离
x
3
x
4
0
60
5 13 0
8 6 7 0
G
1
x
3
x
4
G
1
G
2
G
2

剩余89页未读,继续阅读
2022-08-03 上传
2022-08-03 上传
2023-06-12 上传
2023-07-27 上传
2023-10-23 上传
2023-02-06 上传
2023-06-03 上传
2023-08-01 上传
2023-07-28 上传

陈熙昊
- 粉丝: 25
- 资源: 318
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多模态联合稀疏表示在视频目标跟踪中的应用
- Kubernetes资源管控与Gardener开源软件实践解析
- MPI集群监控与负载平衡策略
- 自动化PHP安全漏洞检测:静态代码分析与数据流方法
- 青苔数据CEO程永:技术生态与阿里云开放创新
- 制造业转型: HyperX引领企业上云策略
- 赵维五分享:航空工业电子采购上云实战与运维策略
- 单片机控制的LED点阵显示屏设计及其实现
- 驻云科技李俊涛:AI驱动的云上服务新趋势与挑战
- 6LoWPAN物联网边界路由器:设计与实现
- 猩便利工程师仲小玉:Terraform云资源管理最佳实践与团队协作
- 类差分度改进的互信息特征选择提升文本分类性能
- VERITAS与阿里云合作的混合云转型与数据保护方案
- 云制造中的生产线仿真模型设计与虚拟化研究
- 汪洋在PostgresChina2018分享:高可用 PostgreSQL 工具与架构设计
- 2018 PostgresChina大会:阿里云时空引擎Ganos在PostgreSQL中的创新应用与多模型存储
