
【【NLP】】Seq2Seq模型与实战(模型与实战(Tensoflow2.x、、Keras))
文章目录文章目录一、从RNN到Seq2Seq1.1 Seq2Seq1.2 encoder-decoder结构01、encoder02、decoder1.3 模型训练二、 实战2.1超参数设置2.2数据的预处理2.3模型输入2.4模型构建2.5
模型使用
一、从一、从RNN到到Seq2Seq
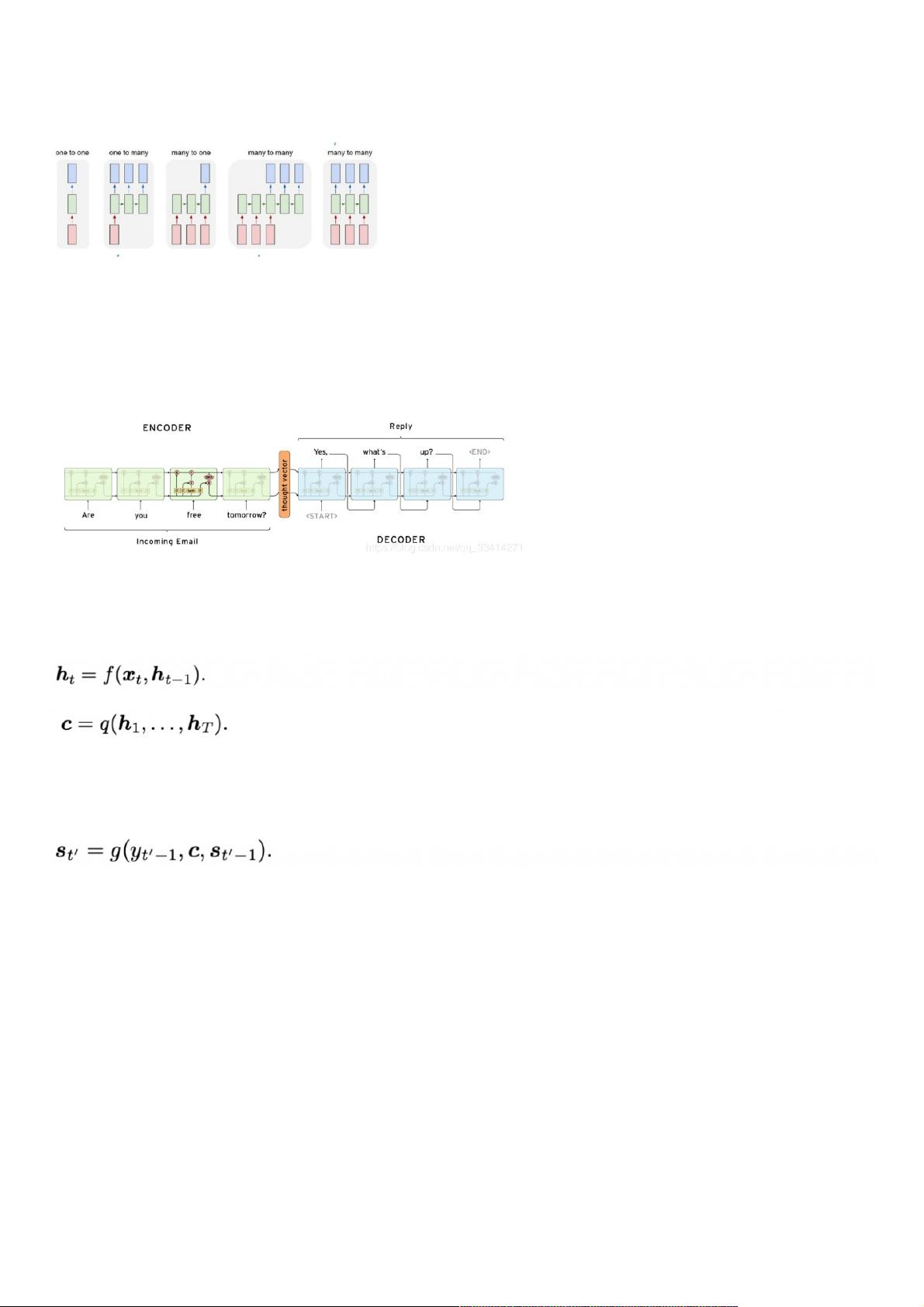
根据输出和输入序列不同数量rnn可以有多种不同的结构,不同结构自然就有不同的引用场合。如下图,
one to one 结构,仅仅只是简单的给一个输入得到一个输出,此处并未体现序列的特征,例如图像分类场景。
one to many 结构,给一个输入得到一系列输出,这种结构可用于生产图片描述的场景。
many to one 结构,给一系列输入得到一个输出,这种结构可用于文本情感分析,对一些列的文本输入进行分类,看是消极还是积极情感。
many to many 结构,给一些列输入得到一系列输出,这种结构可用于翻译或聊天对话场景,对输入的文本转换成另外一些列文本。
同步 many to many 结构,它是经典的rnn结构,前一输入的状态会带到下一个状态中,而且每个输入都会对应一个输出,我们最熟悉的就是用于字符预测了,同样也可以用于视频分
类,对视频的帧打标签。
1.1 Seq2Seq
在 many to many 的两种模型中,上图可以看到第四和第五种是有差异的,经典的rnn结构的输入和输出序列必须要是等长,它的应用场景也比较有限。而第四种它可以是输入和输出
序列不等长,这种模型便是seq2seq模型,即Sequence to Sequence。它实现了从一个序列到另外一个序列的转换,比如google曾用seq2seq模型加attention模型来实现了翻译功
能,类似的还可以实现聊天机器人对话模型。经典的rnn模型固定了输入序列和输出序列的大小,而seq2seq模型则突破了该限制。
其实对于seq2seq的decoder,它在训练阶段和预测阶段对rnn的输出的处理可能是不一样的,比如在训练阶段可能对rnn的输出不处理,直接用target的序列作为下时刻的输入,预测
阶段会将rnn的输出当成是下一时刻的输入。
1.2 encoder-decoder结构结构
01、、encoder
编码器的作用是把一个不定的输入序列变换成一个定的背景变量c,并在该背景变量中编码输入序列信息。常用的编码器是循环神经网络。
用函数f 表达循环神经网络隐藏层的变换:
编码器通过自定义函数q将各个时间步的隐藏状态变换为背景变量:
获取语义向量最简单的方式就是直接将最后一个输入的隐状态作为语义向量C。也可以对最后一个隐含状态做一个变换得到语义向量,还可以将输入序列的所有隐含状态做一个变换
得到语义变量。
02、、decoder
decoder则负责根据语义向量生成指定的序列,这个过程也称为解码。
在输出序列的时间步t′ ,解码器将上一时间步的输出y(t′−1) 以及背景变量c作为输入,并将它们与上一时间步的隐藏状态s(t′−1) 变换为当前时 间步的隐藏状态s(t′) 。因此,我们可以用
函数g表达解码器隐藏层的变换:
基于当前时间步的解码器隐藏状态 s(t′) 、上一时间步的输出y(t′ −1) 以及背景 变量c来计算当前时间步输出y(t′) 的概率分布。
下载后可阅读完整内容,剩余4页未读,立即下载

weixin_38612568
- 粉丝: 3
- 资源: 898
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++多态实现机制详解:虚函数与早期绑定
- Java多线程与异常处理详解
- 校园导游系统:无向图实现最短路径探索
- SQL2005彻底删除指南:避免重装失败
- GTD时间管理法:提升效率与组织生活的关键
- Python进制转换全攻略:从10进制到16进制
- 商丘物流业区位优势探究:发展战略与机遇
- C语言实训:简单计算器程序设计
- Oracle SQL命令大全:用户管理、权限操作与查询
- Struts2配置详解与示例
- C#编程规范与最佳实践
- C语言面试常见问题解析
- 超声波测距技术详解:电路与程序设计
- 反激开关电源设计:UC3844与TL431优化稳压
- Cisco路由器配置全攻略
- SQLServer 2005 CTE递归教程:创建员工层级结构
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


