"该文档主要探讨了使用贝叶斯最大后验概率准则对Iris大数据进行地分类的问题。实验涉及多元正态分布的理论,参数估计方法以及贝叶斯分类策略。通过Iris数据集,该文详细解释了如何对三类数据(setosa,versicolor和virginica)进行两两分类,每类数据服从四维正态分布。"
1、实验背景与目标
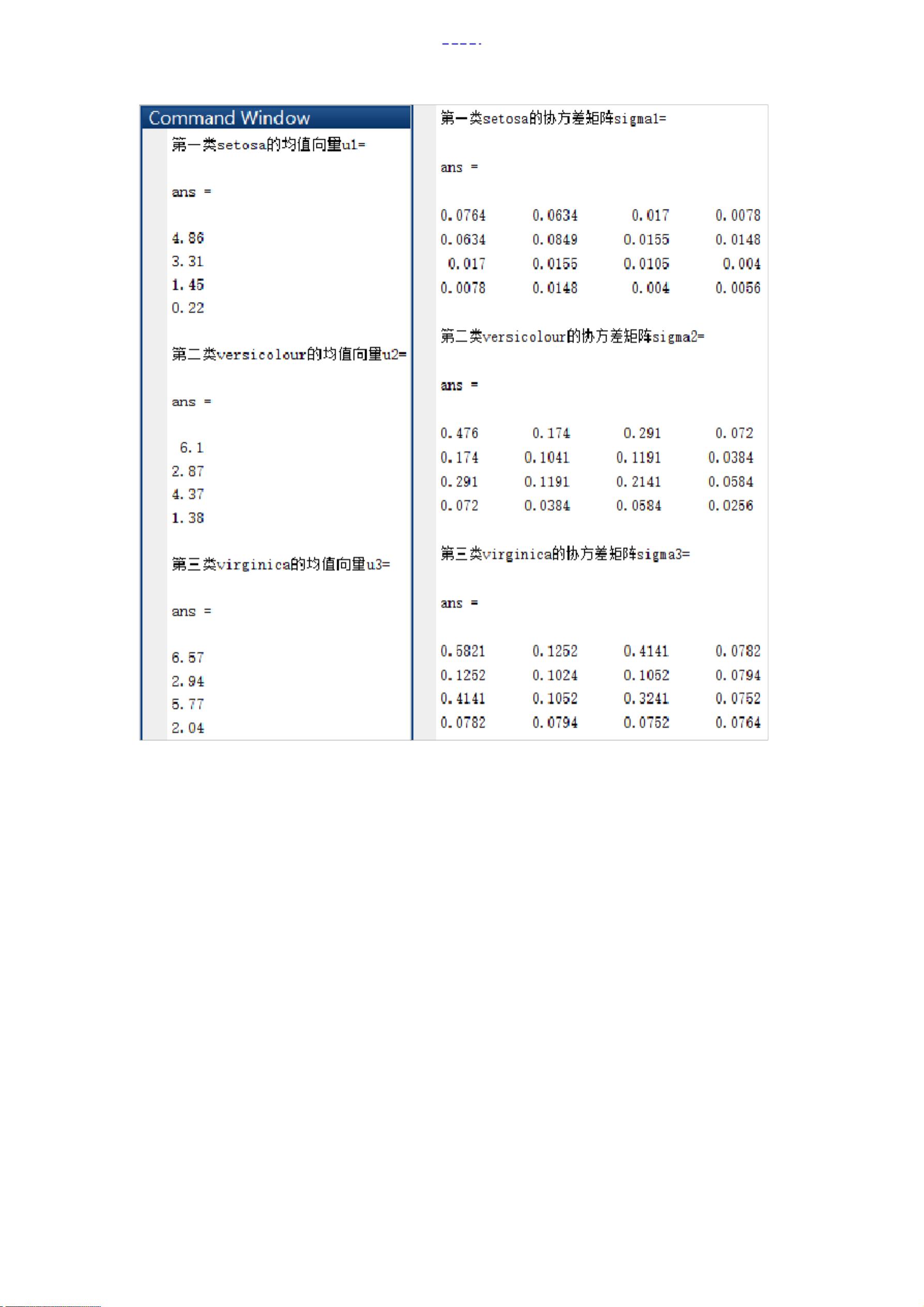
实验旨在理解和应用多元正态分布理论,通过矩估计法估计参数,并利用贝叶斯最大后验概率准则实现数据分类。实验对象是Iris数据集,包含setosa、versicolou和virginica三个类别,每个类别有50个四维向量数据,这些向量均服从四维正态分布。
2、多元正态分布
多元正态分布是一种统计学上的概念,表示随机向量X的概率密度函数形式,其中μ是均值向量,Σ是协方差矩阵。在确定了这两个参数后,就可以完全定义一个多元正态分布。
3、参数估计
在实验中,采用矩估计法对每组数据的四维正态分布参数进行估计。通过对训练数据的均值向量和协方差矩阵的计算,得到每类数据的参数估计,从而构建各自的数据分布密度函数。
4、贝叶斯最大后验概率准则
贝叶斯分类基于后验概率最大化,即给定观测特征,选择具有最高后验概率的类别作为分类结果。在两两分类问题中,通过计算输入数据向量x在两类别的后验概率,选择概率较大的一类进行分类。
5、实验步骤
- 首先,利用部分数据进行训练,估计出每类数据的均值向量和协方差矩阵。
- 其次,使用贝叶斯公式计算输入数据在各类别的后验概率。
- 最后,将数据分配给后验概率最高的类别,完成分类。
6、应用与意义
这种分类方法在大数据分析和机器学习领域有广泛应用,特别是在处理高维数据和需要考虑先验知识的情况下。通过贝叶斯最大后验概率准则,可以有效地处理不确定性,提高分类的准确性和可靠性。
总结来说,该文档深入浅出地介绍了如何运用统计学方法处理Iris数据集,特别是利用贝叶斯最大后验概率准则进行数据分类。这一方法不仅适用于Iris数据,也可以推广到其他类似的大数据分类问题中。