Hadoop集群详解:架构、网络与服务器关系
"深入理解Hadoop集群和网络,探讨Hadoop在云计算环境中的网络架构,以及其与服务器基础设施的关系。"
Hadoop是一个分布式计算框架,它允许在大规模集群中处理大量数据。Hadoop集群的核心组成部分包括Client机器、主节点和从节点。主节点包括名称节点(NameNode)和JobTracker,它们分别管理HDFS(Hadoop Distributed File System)和MapReduce的运行。名称节点负责存储文件系统的元数据,并协调数据块的访问;JobTracker则负责作业调度和任务分配。
从节点(DataNodes)是集群中的工作horse,它们存储数据并执行MapReduce任务。每个从节点既是数据节点,也是与主节点通信的守护进程。Client机器则扮演数据输入输出的角色,提交作业,接收结果,但并不参与实际的计算过程。
在小型集群中,可能在一个物理服务器上同时运行JobTracker和名称节点,以节省硬件成本。然而,在大型生产环境中,为了保证高可用性和性能,通常会将这些角色分开,每项任务由单独的服务器承载。这是因为虚拟化会引入额外的开销,而Hadoop设计的目标是直接与硬件交互,以实现最佳性能。
在Hadoop集群的物理布局中,服务器通常采用机架式结构,机架之间通过高速网络交换机互连。常见的网络带宽为1GB或2GB,但更高速的10GB带宽可以显著提升集群的处理能力,尤其是在处理高密度的CPU和磁盘I/O时。这种网络架构允许数据在节点间快速移动,确保了MapReduce操作的高效执行。
Hadoop在Linux操作系统上的表现最佳,因为它可以直接访问底层硬件,提供更好的性能和更低的成本。集群的扩展性是其另一大优势,可以根据需求添加更多服务器来扩展存储和计算能力。理解Hadoop集群的网络架构对于优化大数据处理的性能和效率至关重要。
4
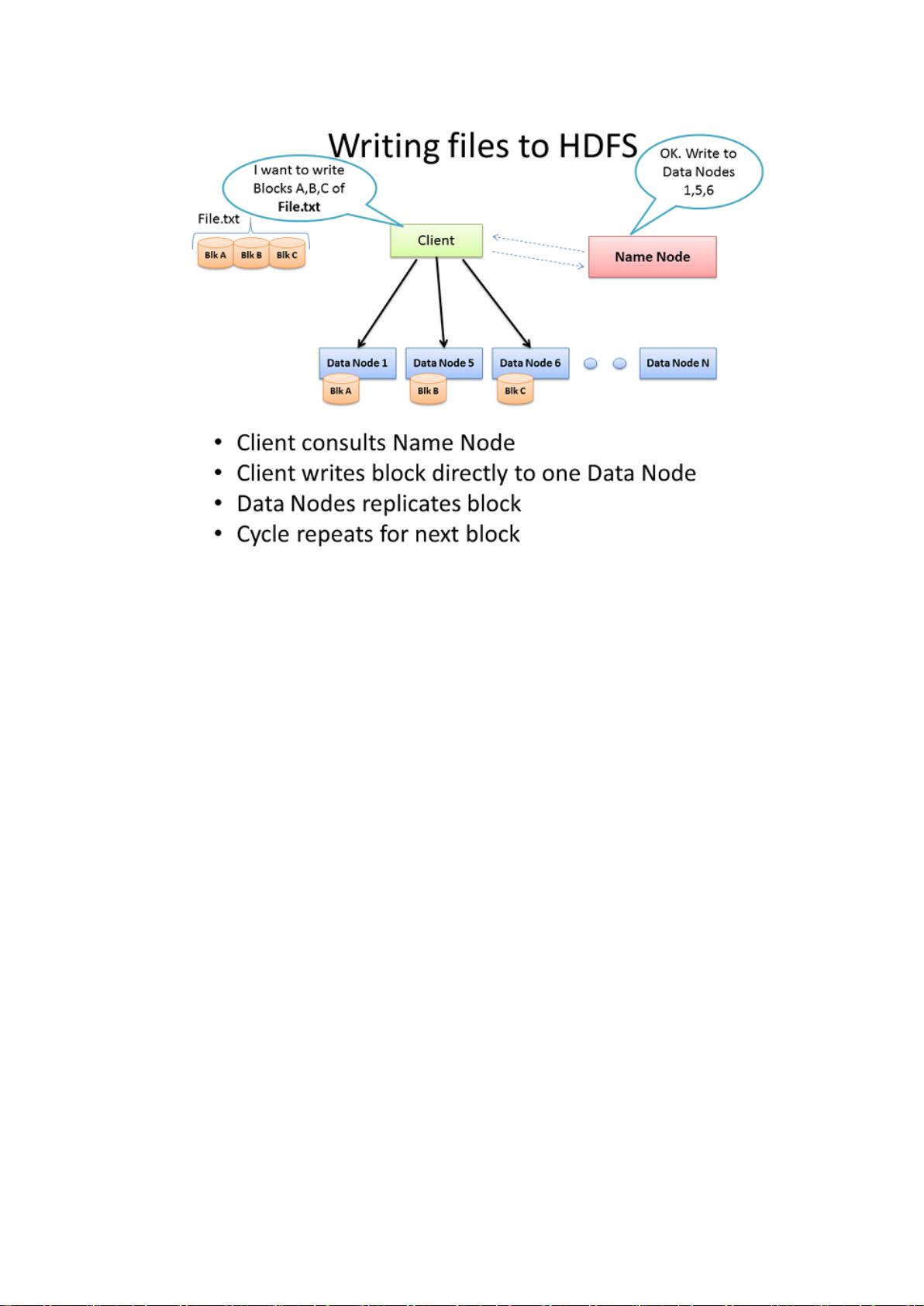
向 HDFS 里写入 File
Hadoop 集群在没有注入数据之前是不起作用的,所以我们先从加载庞大的 File.txt 到
集群中开始。首要的目标当然是数据快速的并行处理。为了实现这个目标,我们需要竟可能
多的机器同时工作。最后,Client 将把数据分成更小的模块,然后分到不同的机器上贯穿
整个集群。模块分的越小,做数据并行处理的机器就越多。同时这些机器机器还可能出故障,
所以为了避免数据丢失就需要单个数据同时在不同的机器上处理。所以每块数据都会在集群
上被重复的加载。Hadoop 的默认设置是每块数据重复加载 3 次。这个可以通过 hdfs-site.xml
文件中的 dfs.replication 参数来设置。
Client 把 File.txt 文件分成 3 块。Cient 会和名称节点达成协议(通常是 TCP 9000
协议)然后得到将要拷贝数据的 3 个数据节点列表。然后 Client 将会把每块数据直接写入
数据节点中(通常是 TCP 50010 协议)。收到数据的数据节点将会把数据复制到其他数据节
点中,循环只到所有数据节点都完成拷贝为止。名称节点只负责提供数据的位置和数据在族
群中的去处(文件系统元数据)。
剩余17页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2013-11-11 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2018-10-09 上传
2010-07-12 上传

bigdatayunzhongyan
- 粉丝: 23
- 资源: 14
 我的内容管理
展开
我的内容管理
展开







